标签:单位 会话 ram bss res 大于 自动分配 声明 sci
进程/线程的区别:
进程是资源分配的最小单位,线程是CPU调度的最小单位
死锁的四个必要条件
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
网络每一层都有什么协议
、物理层协5261议有:EIA/TIA-232,4102 EIA/TIA-499,V.35, V.24,RJ45, Ethernet, 802.3
数据链路层协议有:Frame Relay,HDLC,PPP, IEEE 8./8.
、网络层协议有:IP,IPX,AppleTalk DDP?
、传输层协议有:TCP,UDP,SPX
、会话层协议有:RPC,SQL,NFS,NetBIOS,names,AppleTalk
、表示层协议有:TIFF,GIF,JPEG,PICT,ASCII,EBCDIC,encryption
、应用层协议有:FTP,WWW,Telnet,NFS,SMTP,Gateway,SNMP
TCP UDP 区别:
1.基于连接与无连接;
2.对系统资源的要求(TCP较多,UDP少);
3.UDP程序结构较简单;
4.流模式与数据报模式 ;
5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。
栈和堆的区别;
(1)管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏;?
(2)空间大小不同。每个进程拥有的栈的大小要远远小于堆的大小。理论上,程序员可申请的堆大小为虚拟内存的大小,进程栈的大小64bits的Windows默认1M,64bits的Linux默认10M;?
(3)生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。?
(4)分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由操作系统进行释放,无需我们手工实现。?
(5)分配效率不同。栈由操作系统自动分配,会在硬件层级对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是由C/C++提供的库函数或运算符来完成申请与管理,实现机制较为复杂,频繁的内存申请容易产生内存碎片。显然,堆的效率比栈要低得多。?
(6)存放内容不同。栈存放的内容,函数返回地址、相关参数、局部变量和寄存器内容等。当主函数调用另外一个函数的时候,要对当前函数执行断点进行保存,需要使用栈来实现,首先入栈的是主函数下一条语句的地址,即扩展指针寄存器的内存(eip),然后是当前栈帧的底部地址,即扩展基址指针寄存器内容(ebp),再然后是被调函数的实参等,一般情况下是按照从右向左的顺序入栈,之后是调用函数的局部变量,注意静态变量是存放在数据段或者BSS段,是不入栈的。出栈的顺序正好相反,最终栈顶指向主函数下一条语句的地址,主程序又从该地址开始执行。堆,一般情况堆顶使用一个字节的空间来存放堆的大小,而堆中具体存放内容是由程序员来填充的。
从以上可以看到,堆和栈相比,由于大量malloc()/free()或new/delete的使用,容易造成大量的内存碎片,并且可能引发用户态和核心态的切换,效率较低。栈相比于堆,在程序中应用较为广泛,最常见的是函数的调用过程由栈来实现,函数返回地址、EBP、实参和局部变量都采用栈的方式存放。虽然栈有众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,主要还是用堆。
STL库函数,数据结构都是什么
1.vector ?底层数据结构为数组 ,支持快速随机访问
2.list ? ?底层数据结构为双向链表,支持快速增删
3.deque ? 底层数据结构为一个中央控制器和多个缓冲区,详细见STL源码剖析P146,支持首尾(中间不能)快速增删,也支持随机访问
4.stack ? 底层一般用23实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时
5.queue ? 底层一般用23实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时
6.45是适配器,而不叫容器,因为是对容器的再封装
7.priority_queue 的底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现
8.set ? ? ? 底层数据结构为红黑树,有序,不重复
9.multiset ?底层数据结构为红黑树,有序,可重复?
10.map ? ? ?????底层数据结构为红黑树,有序,不重复
11.multimap 底层数据结构为红黑树,有序,可重复
12.hash_set?????底层数据结构为hash表,无序,不重复
13.hash_multiset?底层数据结构为hash表,无序,可重复?
14.hash_map ? ? ?????底层数据结构为hash表,无序,不重复
15.hash_multimap?底层数据结构为hash表,无序,可重复
虚函数的底层实现
1.每一个class产生一堆指向虚函数的指针,放在表格之中。这个表格称之为虚函数表(virtual table,vtbl)。
2.每一个对象被添加了一个指针,指向相关的虚函数表vtbl。通常这个指针被称为vptr。vptr的设定(setting)和重置(resetting)都由每一个class的构造函数,析构函数和拷贝赋值运算符自动完成。
如何在o(1)的时间内删除链表的指定结点;
待删指针不是尾指针:
待删指针的值用待删指针的下一个指针的值覆盖
删掉待删指针的下一个指针
待删指针是尾指针:
待删指针同时是头指针:
删掉头指针
待删指针不是头指针
找到待删指针的前一个指针
删掉待删指针,前一个指针的next赋值为空
TCP是如何保证可靠传输的;
1、确认和重传:接收方收到报文就会确认,发送方发送一段时间后没有收到确认就重传。
2、数据校验
3、数据合理分片和排序:
UDP:IP数据报大于1500字节,大于MTU.这个时候发送方IP层就需要分片(fragmentation).把数据报分成若干片,使每一片都小于MTU.而接收方IP层则需要进行数据报的重组.这样就会多做许多事情,而更严重的是,由于UDP的特性,当某一片数据传送中丢失时,接收方便无法重组数据报.将导致丢弃整个UDP数据报.
tcp会按MTU合理分片,接收方会缓存未按序到达的数据,重新排序后再交给应用层。
4、流量控制:当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。
5、拥塞控制:当网络拥塞时,减少数据的发送。
4次挥手时time_wait的作用是什么
(1)为实现TCP连接的可靠释放
保证最后一个ACK能到达服务器,如果服务器没有收到客户端的确认报文,它会重新进行第四次挥手,这样客户端在2MSL内能收到重发的报文,并给出回应,重置2MSL计时器(MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”)
(2)为使旧的重复数据包在网络中因过期而消失
服务端发送给客户端的一些报文在传输过程中由于网络拥堵而导致严重推迟,而在它到达客户端之前服务端已经重发了该报文,并完成其任务。如果在被推迟的报文未抵达前客户端就断开了连接,随后又建立了一个与之前相同IP、Port的连接,而之前被推迟的报文在这时恰好到达,而此时此新连接非彼连接,从而会发生数据错乱,进而导致无法预知的情况。因此必须维持一段等待时间,使迟到的报文在网络中完全消失。这个时间可以时所有网络中的报文到达应该到的位置,新的连接中不会出现旧的连接的报文
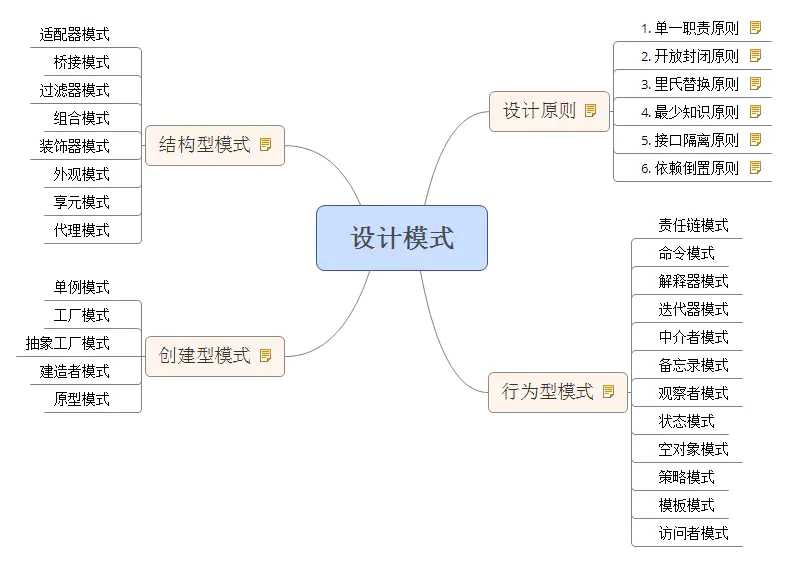
设计模式的设计原则;
Static与Const的区别
static
static局部变量 将一个变量声明为函数的局部变量,那么这个局部变量在函数执行完成之后不会被释放,而是继续保留在内存中
static 全局变量 表示一个变量在当前文件的全局内可访问
static 函数 表示一个函数只能在当前文件中被访问
static 类成员变量 表示这个成员为全类所共有
static 类成员函数 表示这个函数为全类所共有,而且只能访问静态成员变量
const
const 常量:定义时就初始化,以后不能更改。
const 形参:func(const int a){};该形参在函数里不能改变
const修饰类成员函数:该函数对成员变量只能进行只读操作
标签:单位 会话 ram bss res 大于 自动分配 声明 sci
原文地址:https://www.cnblogs.com/pengfeij/p/13052863.html