标签:dHash lazy ash static 目的 extends tran 复杂 spl
一、Set集合特点
插入无序,不可指定位置访问。且内部数据不能重复(==或equals)的元素(只要有一个为true就不能重复,重写了equals方法也算)。常用实现类有HashSet、TreeSet。
二、元素不能重复?
1.Set是如何判断元素重复?
HashSet是由HashMap实现的,HashSet.add()引用的是HashMap.put()。
首先通过hashcode判断两对象内存地址哈希值是否相等,如果不相等,则一定不重复。(先通过hashcode快速筛选不相等的对象)。
其次通过equals判断两对象内容是否相等,进而得知两对象最后是否相等。
2. 我们自己写自定义类时一定要重写equals和hashcode方法为判断元素重复提供依据。
三、HashSet
HashSet内部是由HashMap实现的,类内部定义了一个HashMap成员变量。本质就是数组+链表+红黑树。
private transient HashMap<E,Object> map;
既然底层实用hashmap实现的,那么键值对分别对应的是什么呢?让我们走进add方法。
public boolean add(E e) { return map.put(e, PRESENT)==null; }
哦?可以看出我们要添加的元素是作为mao的key的,那作为value的PRESENT是啥呢?
// Dummy value to associate with an Object in the backing Map:与备份映射中的对象关联的虚拟值 private static final Object PRESENT = new Object();
综上可知:HashSet底层使用hashmap实现,键:我们操作的元素,即集合中的数据,值:为同一个Object对象
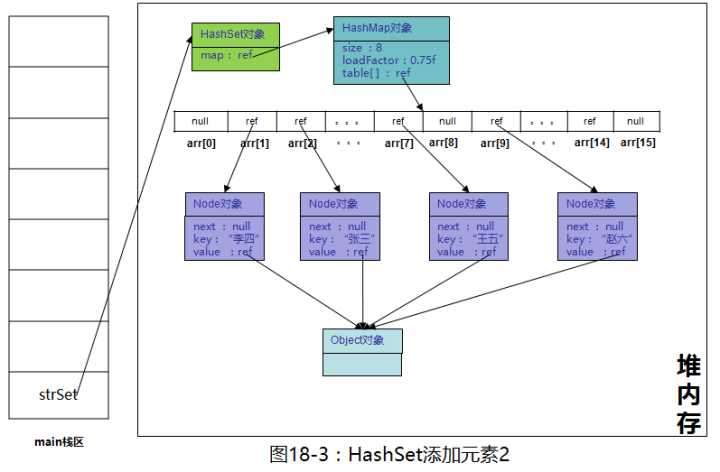
四、TreeSet
TreeSet是基于TreeMap实现的,本质就是红黑树。插入无序,内部排序,即按照对象特性进行排序。
继承关系:
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable
TreeSet中含有一个"NavigableMap类型的成员变量"m,而m实际上是"TreeMap的实例"。TreeMap也实现NavigableMap接口。
构造方法:
TreeSet(NavigableMap<E,Object> m) { this.m = m; } public TreeSet() { this(new TreeMap<E,Object>()); } public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<>(comparator)); } public TreeSet(Collection<? extends E> c) { this(); addAll(c); } public TreeSet(SortedSet<E> s) { this(s.comparator()); addAll(s); }
HashSet 效率要高于TreeSet,因为HashSet采用散列算法快速对集合进行增删改查 时间复杂度更是几乎接近O(1),但内部无序。
TreeSet 内部有序,可根据指定规则去排序。但效率要比较HashSet低。时间复杂度位O(log n)。
五、LinkedHashSet
LinkedHashSet具有Set不可重复的特点,也有插入排序的特点。其底层是由LinkedHashMap来维护的,其维护着一个运行于所有条目的双重链接列表,此链接列表顶一个迭代顺序(插入顺序或者访问顺序)。
标签:dHash lazy ash static 目的 extends tran 复杂 spl
原文地址:https://www.cnblogs.com/qmillet/p/13063005.html