标签:aci modal count 改进 sed ini idea exist exit
HashMap在进行put操作时有很多细节设计的确值得我们去学习,下面是对put方法的一些接单的介绍,如果有什么不足之处还希望大佬能给与指出;
既然说到集合的底层原理,首先要介绍一下HashMap的底层数据结构:
JDK1.8以前底层的结构为数组+链表;JDK1.8及以后对HashMap进行了优化(不急一会再来讨论主要进行了哪些优化和改进),底层的数据结构改成了数组+链表+红黑树;先看一下具体的结构(此处主要以1.8版本为例)。
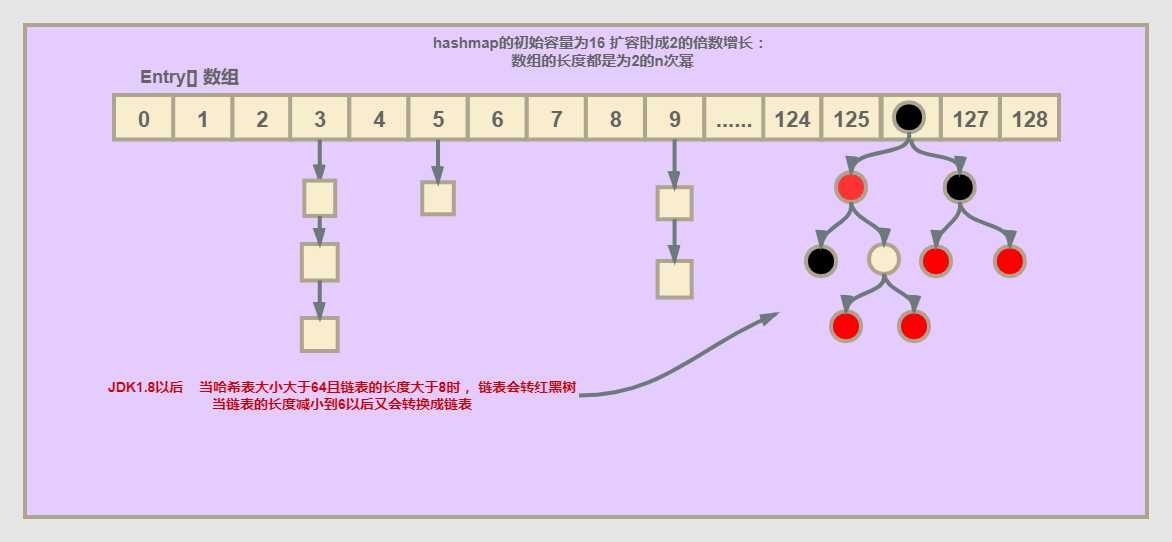
首先纠正一下很多人画这个结构图的一个误区(数组的长度大于64才会有出现红黑树的可能):当发生hash冲突时hashmap的解决方法是用 链地址法(用单链表的方法),jdk1.8以后出现了红黑树的概念,数组转红黑树的条件其实有两个:1、哈希表的容量要大于64(static final int MIN_TREEIFY_CAPACITY = 64;)2、链表的长度大于8(static final int TREEIFY_THRESHOLD = 8;);
源码如图:
/** * Replaces all linked nodes in bin at index for given hash unless * table is too small, in which case resizes instead. */ final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; //当哈希表的容量小于64时只需要进行扩容 MIN_TREEIFY_CAPACITY=64 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); //大于等于64才会转红黑树 else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }
底层数据结构简化图:
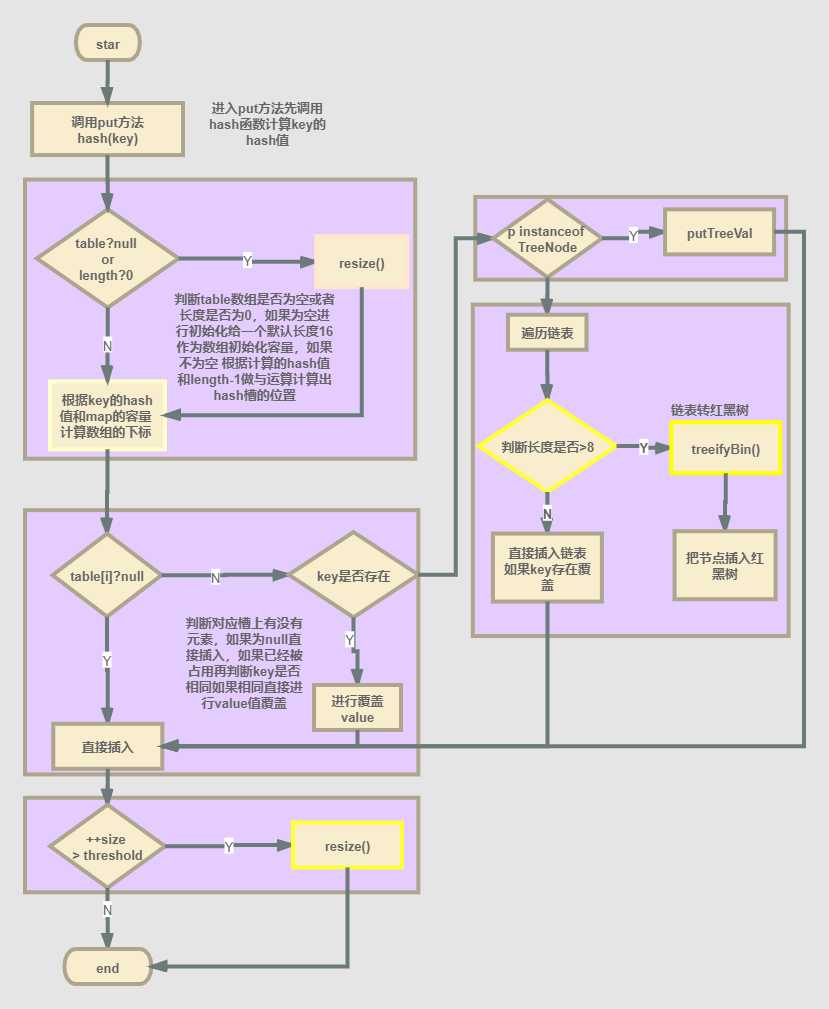
下图是HashMap的put操作简单流程图:
源码分析:我在源码中进行了一些注释希望可以帮助大家理解(如有不当望指出);
其中HashMap类中有几个参数比较关键:
1 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 数组的初始化容量 2 static final int MAXIMUM_CAPACITY = 1 << 30;就是表示一个很大的int数 int总共有4个字节最高位是符号位 如果写成(1<<31)就变成了负数 3 static final float DEFAULT_LOAD_FACTOR = 0.75f; //扩容因子的大小 4 5 static final int TREEIFY_THRESHOLD = 8; //当链表的长度大于8时 进行数组转红黑树 6 7 static final int UNTREEIFY_THRESHOLD = 6; //当红黑树的节点数小于6时 则又会进行红黑树转数组的一个操作 8 9 static final int MIN_TREEIFY_CAPACITY = 64; //最小树形化容量阈值 只有当哈希表的容量大于这个数时才进行树形化(数组转红黑树)否则会进行扩容 10 11 transient Node<K,V>[] table; //这是一个空数组 12 13 transient int modCount;//用来记录hashmap的操作次数 14 15 int threshold; //扩容时的一个阀值 大于这个阀值 就会进行resize(); 16 17 final float loadFactor; //加载因子 18 static final float DEFAULT_LOAD_FACTOR = 0.75f; 19 public HashMap() { 20 this.loadFactor = DEFAULT_LOAD_FACTOR; // al‘dl other fields defaulted 21 }
HashMap中putVal()的源码和一些对应的注释;
1 /** 2 * Implements Map.put and related methods 3 * 4 * @param hash hash for key 5 * @param key the key 6 * @param value the value to put 7 * @param onlyIfAbsent if true, don‘t change existing value 8 * @param evict if false, the table is in creation mode. 9 * @return previous value, or null if none 10 */ 11 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 12 boolean evict) { 13 Node<K,V>[] tab; Node<K,V> p; int n, i; 14 //判断table中是否有元素,如果为空,说明此操作为第一次put操作,接下来++modCount元素个数加一; 15 if ((tab = table) == null || (n = tab.length) == 0) 16 //数组初始化:长度为16; 17 n = (tab = resize()).length; 18 //-1的原码为 1000 0001 和hash值作按位与运算计算出数组下标 判断如果对应hash槽上没有元素直接插入; 19 if ((p = tab[i = (n - 1) & hash]) == null) 20 tab[i] = newNode(hash, key, value, null); 21 else { 22 Node<K,V> e; K k; 23 //如果对应的槽上有元素;判断key是否相同,若相同 则直接覆盖value值; 24 if (p.hash == hash && 25 ((k = p.key) == key || (key != null && key.equals(k)))) 26 e = p; 27 //判断p节点是否为TreeNode的实例 如果为红黑树结构则插入到红黑树对应位置上 28 else if (p instanceof TreeNode) 29 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 30 //如果key也不相同,也不是红黑树,则此处为链表结构,则需要对链表进行循环遍历 31 else { 32 for (int binCount = 0; ; ++binCount) { 33 if ((e = p.next) == null) { 34 //直到遍历到最后一个节点,将元素放到最后一位(尾插法 1.7版本使用的是头插法) 35 p.next = newNode(hash, key, value, null); 36 //判断如果链表长度大于等于8时 链表转红黑树(TREEITY_THRESHOLD = 8) binCount 从0开始 37 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 38 treeifyBin(tab, hash); 39 break; 40 } 41 //如果hash值 和 key都相同 跳出循环 42 if (e.hash == hash && 43 ((k = e.key) == key || (key != null && key.equals(k)))) 44 break; 45 p = e; 46 } 47 } 48 //链表中有重复key 将新的value替换 返回旧的value 49 if (e != null) { // existing mapping for key 50 V oldValue = e.value; 51 if (!onlyIfAbsent || oldValue == null) 52 e.value = value; 53 afterNodeAccess(e); 54 return oldValue; 55 } 56 } 57 //跳转到此处说明 对应的hash槽没有元素 修改次数+1 58 ++modCount; 59 if (++size > threshold) 60 resize(); 61 afterNodeInsertion(evict); 62 return null; 63 }
分析一下hashmap是如何通过hash()函数进行计算元素在哈希表中的下标(index);
1 package com.designmodal.design.collection; 2 3 import java.util.*; 4 5 /** 6 * 此处分析一下HashMap如何通过hash函数寻找index(数组下标) 7 */ 8 public class HashMapTest { 9 public static void main(String[] args) { 10 HashMap map = new HashMap(); 11 map.put("董亮测试HashMap中扰动函数","测试"); 12 String key = "董亮测试HashMap中扰动函数;"; 13 // static final int hash(Object key) { 14 // int h; 15 // return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 16 // } 17 System.out.println("hash()函数计算开始------------"); 18 int h; 19 h = key.hashCode(); 20 System.out.println("key.hashcode()"+":"+Integer.toBinaryString(h)); 21 22 int hh = h>>>16; 23 System.out.println("key.hashcode()>>>16"+":"+Integer.toBinaryString(hh)); 24 25 int result = h^hh; 26 System.out.println("h = (key.hashCode()) ^ (h >>> 16)"+":"+Integer.toBinaryString(result)); 27 System.out.println("hash()函数计算结束------------"); 28 // Node<K,V>[] tab; Node<K,V> p; int n, i; 29 // if ((tab = table) == null || (n = tab.length) == 0) 30 // n = (tab = resize()).length; 31 // if ((p = tab[i = (n - 1) & hash]) == null) 32 // tab[i] = newNode(hash, key, value, null); 33 //如果数组的初始化长度为16 n-1:15 result:为hash函数计算值 34 int n = 15; 35 int index = (n-1)&result; 36 System.out.println(index); 37 } 38 }
我想当每个人第一次阅读到这里都会有疑问这个hash函数为什么要这么设计,为什么要 (h = key.hashCode()) ^ (h >>> 16)? 为什么要if ((p = tab[i = (n - 1) & hash]) == null)?下面一一给大家解释一下这两个问题;
这个控制台结果是上一步的程序运行结果:
D:\jdk1.8.0_121\bin\java.exe - hash()函数计算开始------------ key.hashcode():11010110100101000001110101011100 key.hashcode()>>>16:1101011010010100 h = (key.hashCode()) ^ (h >>> 16):11010110100101001100101111001000 hash()函数计算结束------------ 8 Process finished with exit code 0
然后演示一下计算的过程:

问题一:hash()函数 为什么要 (h = key.hashCode()) ^ (h >>> 16)?
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来,这种做法可以称为“扰动函数”,目的就是为了是散列值能够解区并分散均匀;
问题二:为什么哈希表的length为2的整数次幂?
因为当length的大小为2的整数次幂(length-1)的二进制每一位都为1保证了 i = (n - 1) & hash(因为与运算只有当每位都为1结果才为1)的结果相等的几率会降低;
问题三:为什么链表的长度大于8时且哈希表的大小超过64时链表转红黑树,但当树节点数减少到6时才转换成链表?
首先设置转红黑树的阀值为8是经过大量的概率测试出来的结果,官网上的文档数据显示:链表长度超过8的几率已经非常低了阀值再加大意义也不是很大,那原因又来了为什么红黑树转链表的大小不是用8作为阀值而选择了6,原因很简单,如果哈希表的元素一直频繁的对树结构上的元素进行put()和remove()操作,这样频繁的树结构转链表然后链表转红黑树,很消耗性能(大家知道树结构的构建是需要时间的 因此效率上肯定会有很大的影响)。
1 Because TreeNodes are about twice the size of regular nodes, we 2 use them only when bins contain enough nodes to warrant use 3 (see TREEIFY_THRESHOLD). And when they become too small (due to 4 removal or resizing) they are converted back to plain bins. In 5 usages with well-distributed user hashCodes, tree bins are 6 rarely used. Ideally, under random hashCodes, the frequency of 7 nodes in bins follows a Poisson distribution 8 (http://en.wikipedia.org/wiki/Poisson_distribution) with a 9 parameter of about 0.5 on average for the default resizing 10 threshold of 0.75, although with a large variance because of 11 resizing granularity. Ignoring variance, the expected 12 occurrences of list size k are (exp(-0.5) * pow(0.5, k) / 13 factorial(k)). The first values are: 14 15 0: 0.60653066 16 1: 0.30326533 17 2: 0.07581633 18 3: 0.01263606 19 4: 0.00157952 20 5: 0.00015795 21 6: 0.00001316 22 7: 0.00000094 23 8: 0.00000006 24 more: less than 1 in ten million
今天的HashMap源码先介绍到这里,有时间会继续介绍里面的一些细节,如果有不同的见解和想法可以一起讨论和学习;
鸡汤就不说了,但还是希望自己的每一步都能有所记录,这样会鼓励自己走得更远,加油!!!;
标签:aci modal count 改进 sed ini idea exist exit
原文地址:https://www.cnblogs.com/dongl961230/p/13055438.html