标签:阈值 情况下 内存不足 tom 搜索 清空 semi reference 模型
????我们都知道Java的垃圾回收并不需要程序员主动的去写代码回收内存,JVM会自动的帮我们去回收内存,既然JVM会自动帮我们进行内存回收,那是不是就不会出现内存不足的情况,显然不是的。即使JVM帮我们进行回收,但是还是有可能出现内存溢出。下面主要将JVM GC(垃圾回收机制)分为几个部分:对象是否是垃圾的判断算法、垃圾收集算法、垃圾收集器,JVM调优几个方面
????垃圾收集器在对内存中的对象回收前,首先就是要确定内存中的对象是不是垃圾,那些对象还被引用着。判断对象是否存活的算法有:1.1 引用计数算法,1.2 可达性分析算法
????????这种算法比较简单,意思就是给每个对象添加一个引用计数器,每当这个对象在其他地方引用时,这个计数器就+1;引用失效时,这个计数器就-1;当这个计数器是0时就代表着这个对象可以被回收。
????????优点:实现起来也比较简单,判断能否被回收也简单,效率快
????????缺点:无法解决对象之间循环引用的问题,假设有两个对象,对象A,对象B,对象A引用对象B,对象B也引用对象A,这就造成了这两个对象相互引用,这时计数器无法减为0,导致这两个对象都无法被回收
????????为了解决对象之间循环引用而导致无法被回收的问题,后面又出现了可达性分析算法。可达性分析算法的基本思想就是:通过被称为"GC ROOT"的对象作为搜索起始点,从这些跟节点开始向下搜索,搜索走过的路径就被称为引用链,如果有些对象没有在这些引用链上,说明这些对象是可以被回收的。算法如图:
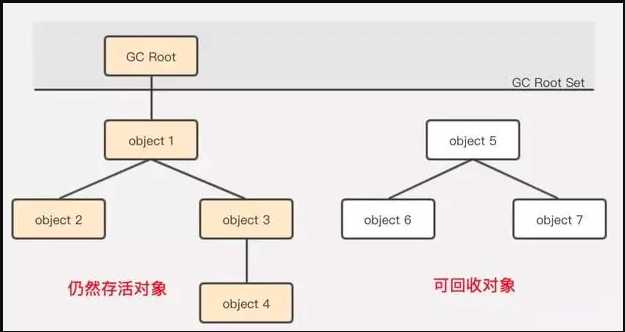
????????从图中我们可以看出,可达性分析算法就可以解决对象之间循环依赖的问题,右边的对象因为没在GC ROOT所在的引用链上,所以JVM判定是可以被回收的。可达性分析算法也引申了另外一个问题,就是内存中的哪些对象可以被作为"GC ROOT"根节点?在Java中,可以被作为GC ROOT的对象包括以下几种:
????????????????(1) 栈帧中局部变量表引用的对象,也就是我们所new一个对象,然后将这个new出来的对象赋值给一个变量,这个变量可以被作为"GC ROOT"根节点
????????????????(2) 方法区中类静态属性引用的对象,类中声明的静态成员变量变量
????????????????(3) 方法区只常量引用的对象,用final修饰的成员变量
????无论是引用计数算法还是可达性分析算法,都牵涉到了对象的引用,而在JDK1.2以后,Java又将引用分为了4种,分别是强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)
????????强引用:强引用也是我们最熟悉的,在代码中最常见的。类似"Object obj = new Object()"这类的引用,这要强引用还存在,这个对象就不会被垃圾回收给回收掉。如果我们想要该对象被回收的话,可以将obj = null,切断变量obj与对象Object之间的强引用,这时对象就可以被垃圾回收
????????软引用:软引用跟强引用有点不同,看一段软引用的使用场景:
SoftReference<Object> softName = new SoftReference<>(new Object());
????????????????JDK给我们提供SoftReference对象来使用软引用,JVM垃圾回收发现此类对象时,这要内存充足的情况下,对象Object就不会被回收掉。在内存不足的情况下,软引用引用的Object对象就会被垃圾回收掉
????????弱引用:使用弱引用的对象拥有的生命周期更加的短,来看一段弱引用的使用场景:
WeakReference<Object> weakName = new WeakReference<Object>(new Object());
????????????????JDK给我们提供了WeakReference对象来使用弱引用,弱引用跟软引用的区别就是:JVM GC时,不管内存够不够,这要发现此类弱引用对象,对象Object对象就会被回收
????????虚引用:虚引用是引用中最弱的一种关系,形同虚设。相当于没被引用一样,也就相当于代码中的obj = null,JVM GC一经发现就会被回收。看一段虚引用的场景:
ReferenceQueue<String> queue = new ReferenceQueue<String>();
PhantomReference<String> pr = new PhantomReference<String>(new String("hello"), queue);
????????????????我们可以看到虚引用是要配合引用队列使用的,如果虚引用pr引用的String("hello")对象被回收掉了,就会将虚引用pr加入到queue队列中,这时我们可以从queue队列中知道pr引用的String("hello")对象被回收掉了
????前面一部分讲的是哪些对象可以被作为垃圾进行回收,确定了对象可以被回收之后,那么就要讲一下具体的垃圾收集了,这里讨论几种常见的垃圾收集算法:标记-清除算法、复制算法、标记-整理算法、分代收集算法
????????标记-清除算法是最基础的算法,大致上可以分为两个阶段:标记、清除两个阶段。首先是标记阶段,标记出所有可以被回收的对象,标记完成后,再进行清除阶段,将所有已经标记的对象进行回收

????????从图中我们可以看到被回收之后,存在大量不连续的内存碎片,会造成一个问题就是如果后面过来一个大对象,因为没有足够大的连续内存进行分配,全是内存碎片,则就会导致分配失败。所有标记-清除算法一个缺点就是:(1)造成大量的内存碎片。还有一个缺点就是:(2) 标记和清除两个阶段的效率并不高
????????为了解决标记-清除算法所带来的内存碎片问题,出现了复制算法。基本思想就是将内存划分为两块大小相等的内存,每次只使用其中的一块,当一块的内存使用完成之后,就会将使用的那块内存存活的对象复制到另外一块未被使用的内存,再把使用过的内存清空,只需移动存活对象的指针
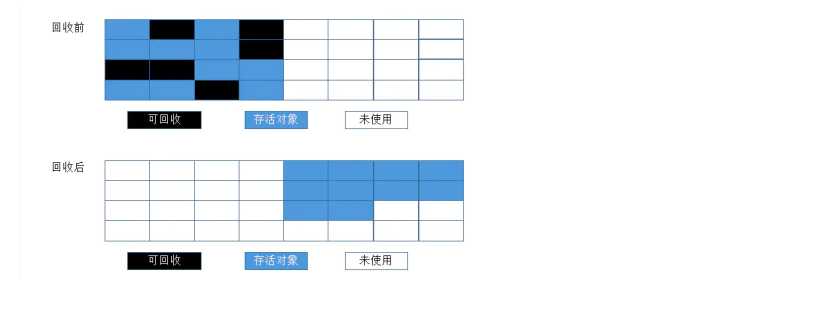
????????从图中我们可以看出右边那部分的内存完全没有被使用到,这就会造成内存空间上的浪费。还有一个问题就是如果存活的对象过多,那么就需要频繁的移动对象的指针,这样会造成效率问题。不过现在的JVM都采用复制算法来回收年轻代,因为年轻代中的对象具有"朝生夕死"的特点,也就是刚创建,说不定过一会这些对象就会马上被回收掉,所以内存大小也并不一定要按复制算法那样平等划分,而年轻代划分的eden:survivor区的比例是8:1:1,每次可以使用的内存是eden和survivor from区,这样造成的内存空间浪费的比例就只有10%了。又因为年轻代中的对象生命周期比较短,所以指针移动时,大部分的对象已经被回收,需要移动的指针也并不多。
????????复制算法所遗留下来的问题:(1) 内存空间的浪费 (2) 存活对象比较多的话,需要频繁的移动指针,效率不高。所以复制算法并不适用于老年代。而针对老年代的特点,有人提出了另外一种算法:标记-整理算法。标记-整理算法跟标记-清除算法有点类似,也是分为两个阶段,但是后续步骤不是直接对可回收对象进行清理,而是让存活的对象都向一端进行移动
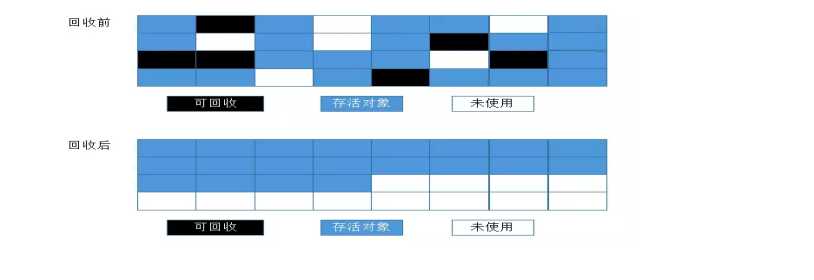
????????从图中我们可以看出标记-整理算法解决了标记-清除算法会产生的内存碎片的问题,但是也还是存在指针频繁移动的缺点,但是也解决了复制算法所造成的内存浪费的缺点
????????分代收集算法其实并不算是一种思想和理论,它只是融合了前面三种算法的思想,根据不同特区对象的特点而采用最适当的收集算法。前面我们讲过新生代中的对象具有"朝生夕死"的特点,所以选用复制算法,只需要让出少量的内存空间就可以完成收集。而老年代中的对象因为对象的存活率比较高,那么可以采用"标记-清理"或者"标记-整理"算法来进行回收
????前面讲的垃圾收集算法只是内存回收的理论,而垃圾收集器则是垃圾收集算法的具体实现,到现在一共出现了7种作用于不同分代的收集器,而不同的收集器之间可以进行组合使用
????????Serial收集器是出现最早的收集器,是单线程的垃圾收集器,在执行GC时,只会有一个线程去进行垃圾回收,用户线程被暂停,直到GC被执行完,这就造成了"Stop The World",也就是进行GC时,用户线程必须暂停,如果这样就会影响我们的程序效率
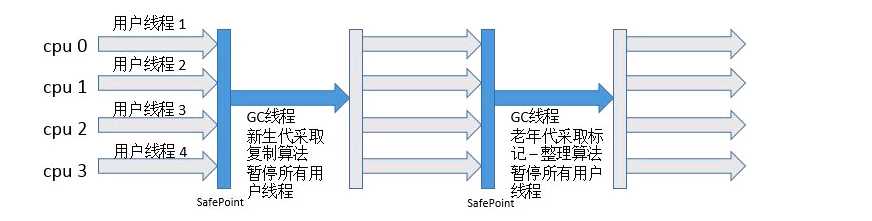
????????我们可以看到它是一种新生代的收集算法,并且采用的是复制算法
????????ParNew收集器跟Serial收集器区别就是:ParNew收集器会采用多线程去进行垃圾回收,这就充分可以利用CPU,ParNew收集器还有一个特点就是:除了Serial收集器外,只有ParNew收集器可以跟CMS收集器(后面会提到)一起组合使用
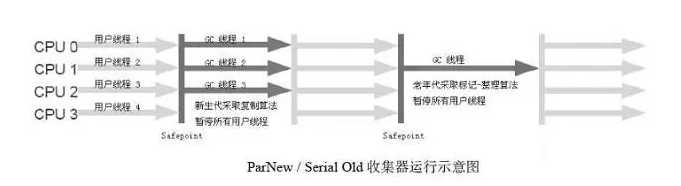
????????从图中我们可以看到ParNew也是一款年轻代收集器,进行垃圾回收时,还是会暂停用户线程,是多线程回收的,采用的也是复制算法
????????Parallel Scavenge也是一款多线程版本的垃圾收集器,也是对年轻代进行回收的,采用的也是复制算法。但是Parallel Scavenge收集器更加的关注可控制的吞吐量,所谓的吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)。
????????Parallel Scavenge收集器提供了两个参数来控制吞吐量,一个是最大垃圾收集停顿时间-XX:MaxGCPauseMillis参数,还有一个就是设置吞吐量大小的-XX:GCTimeRatio参数。
????????这时可能会觉得我们将最大垃圾收集停顿时间-XX:MaxGCPauseMillis参数设置的越小不就越好吗?答案是否定的,GC停顿时间缩短是以牺牲吞吐量和新生代空间换来的,系统会把新生代调小一点,回收300M大小的内存空间肯定要比回收500M的内存要快,因为你的内存变小的,装的对象就小的,所以会频繁的造成GC,以前每10秒才回收一次,一次回收停顿100毫秒,现在变成每5秒回收一次,一次回收停顿70毫秒,虽然停顿时间下降了,但是吞吐量也下降了
????????参数-XX:GCTimeRatio的设置垃圾收集时间占总时间的比率,相当于吞吐量的倒数,如果将此参数设置为19,那么允许的最大GC时间就占总时间的5%(即 1 / (1 + 19)) , 默认值为99,就是允许最大1%(即1 / (1 + 99))的垃圾收集时间
????????Parallel Scavenge收集器还提供一个参数-XX:+UseAdaptiveSizePolicy自适应的调节策略,如果我们设置了此参数,那么我们无须指定新生代的大小、Eden与Survivor区的比例、晋升老年代对象年龄等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整参数以达到最合适的停顿时间或者最大的吞吐量。如果我们使用Parallel Scavenge收集器时,我们只需关注MaxGCPauseMillis或GCTimeRatio参数,设置一个要优化到的目标,具体的优化调节细节可以交给Parallel Scavenge收集器去实现
????????跟Serial收集器一样,单线程的。跟Serial收集器不同的是,Serial Old收集器是作用在老年代中的,采用的是"标记-整理"算法
????????Parallel Old收集器是Parallel Scavenge收集器的老年代版本,作用于老年代中,采用"标记-整理"算法。在JDK1.6之前,Parallel Scavenge收集器只能配合Serial Old收集器一起使用,由于Serial Old收集器采用单线程效率不高,所以出现了Parallel Old收集器来配合Parallel Scavenge收集器一起使用,如果比较关注吞吐量和CPU资源的情况下可以采用这种组合
????????CMS收集器关注的点是尽可能的缩短垃圾收集时用户线程停顿的时间,希望停顿时间最短,这样用户线程执行越快。CMS收集器作用于老年代,采用的是"标记-清除"算法。CMS收集器运行的整个过程分为4个阶段:
????????1. 初始标记
????????2.并发标记
????????3.重新标记
????????4.并发清除
????????在4个阶段中,只有初始标记和重新标记是需要暂停用户线程的,我们可以这样记并发标记和并发清除是并发的,所以不需要暂停用户线程。这样用户线程就没必要在整个GC阶段全部暂停,缩短了用户线程的暂停时间
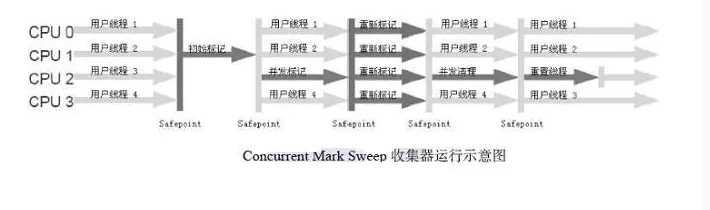
????????虽然CMS收集器可以降低用户线程停顿时间,但是CMS也有几个缺点,一个是对CPU资源非常敏感,我们可以看到在并发阶段,GC线程和用户线程是一起执行的,这样就会产生一个问题,就会产生CPU资源的抢占,可能会造成线程之间交替运行,反而使效率降低。还有一个问题就是CMS收集器因为是采用"标记-清除"算法去实现的那么就会产生大量的内存空间碎片
????????G1收集器是目前既能回收年轻代,又能回收老年代的收集器,无须跟其他收集器进行组合使用,针对不同的代,保留了分代收集的特点,也就是针对不同的代采用不同的收集算法。G1收集器跟CMS的"标记-清除"算法不同,G1收集器采用的是不会产生内存碎片的"标记-整理"算法。G1相对于CMS收集器还有一大特点就是可预测的停顿,G1和CMS共同的关注点都是降低用户线程停顿时间,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒
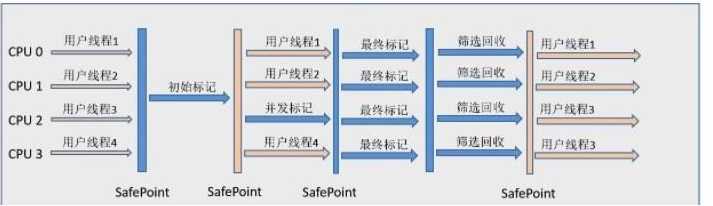
????????G1收集器运行的大致可以划分为4个步骤:
????????1.初始标记
????????2.并发标记
????????3.最终标记
????????4.筛选回收
????????下面来看一张各种收集器之间的组合使用的关系图:
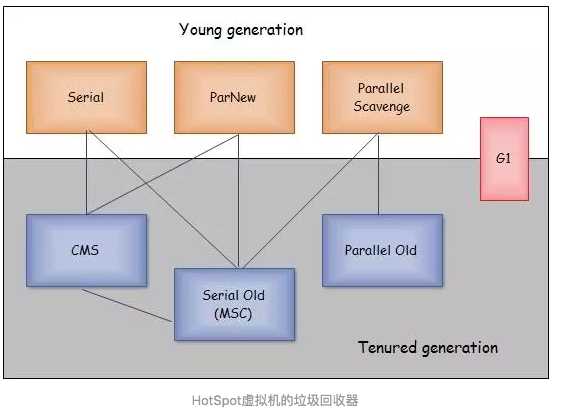
????????我们可以看到:
????????CMS可以跟Serial、ParNew组合使用,而Serial Old是CMS在老年代的后背方案
????????Serial Old可以跟Serial、ParNew、Parallel Scavenge组合使用
????????Parallel Old只可以跟Parallel Scavenge组合使用
????????而G1收集器则不需要任何组合,自己可以完成对年轻代和老年代的回收
????JVM调优总的来说就是优化Full GC的执行时间和执行次数,让Full GC尽可能的少发生,因为发生Full GC时,会造成用户线程暂停,执行时间长。导致Full GC的出现就会老年代的空间不足,这时,可以通过下面几点来进行优化:
????1. 一般来说,当survivor区容量不够时,就会将一些对象放到老年代中,可以进行设置合理的eden区,survivor区及比例大小,可以让对象尽可能的留在年轻代,可以使用-Xmn设置年轻代的大小
????2.对于占用内存比较大的对象,一般会优先选择在老年代上分配内存,这时我们可以设置参数让一些大对象也分配在年轻代中,我们设置参数-XX:PetenureSizeThreshold=1000000,单位为B,标明对象大小如果超过这个数值时在老年代上分配内存,否则还是在年轻代上进行分配
????3.年轻对象在eden区时,每进行一次GC时,如果对象还活着,则这个对象的分代年龄就会+1,一但达到默认值15,就会被放到老年代中,这时我们可以设置参数-XX:MaxTenuringThreshold比较大的阈值,让对象尽可能的停留在年轻代被回收掉
????4.设置最小堆和最大堆:-Xmx和-Xms稳定的堆大小堆垃圾回收是有利的,我们应该将最大堆和最小堆设置成一样的,这样系统在运行时堆大小是恒定的,可以防止每次进行GC后,又得重新分配最小堆和最大堆。稳定的堆大小可以防止一个内存抖动的现象
????5.通过增大吞吐量提高系统性能,可以通过设置并行垃圾回收收集器。(1)-XX:+UseParallelGC:年轻代使用并行垃圾回收收集器。这是一个关注吞吐量的收集器,可以尽可能的减少垃圾回收时间。(2)-XX:+UseParallelOldGC:设置老年代使用并行垃圾回收收集器
????当然,JVM调优并不止这几点,我只是例举了几点常见的优化场景来讲解,JVM提供了许多的JVM参数来供我们进行设置,具体的参数设置还是要根据生产环境出现的问题进行具体的设置
????前面大概讲了下判断对象是否可以被回收的算法,垃圾回收算法,具体实现垃圾回收算法垃圾收集器,例举了他们的一些不同点。最后针对JVM调优例举了一些点,可以对JVM的启动设置参数
标签:阈值 情况下 内存不足 tom 搜索 清空 semi reference 模型
原文地址:https://www.cnblogs.com/semi-sub/p/13062796.html