标签:分布式 聚集 reg 产生 硬件加速 pac 助理 dimen src
分布式深度学习DDL解析
给一个庞大的GPU集群,在实际的应用中,现有的大数据调度器会导致长队列延迟和低的性能,该文章提出了Tiresias,即一个GPU集群的调度器,专门适应分布式深度学习任务,该调度器能够有效率的调度并且合适地放置深度学习任务以减少他们的任务完成时间(JCT(Job Completion Time)),一个深度学习任务执行的时间通常是不可预知的,该文章提出两种调度算法,基于局部信息的离散化二维Gittins索引(Discretized Two Dimensional Gittins index)以及离散化二维LAS,对信息不可知并且能够降低平均的JCT,在实验中JCT能够快5.5倍,相比于基于Apache YARN的资源管理
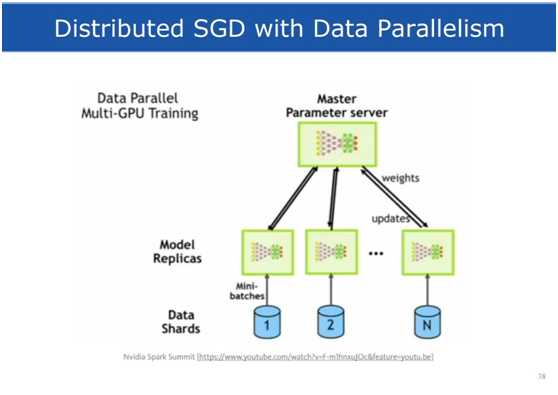
我们关注数据的并行化,数据的并行化是目前流行的分布式深度学习框架的公共部分。
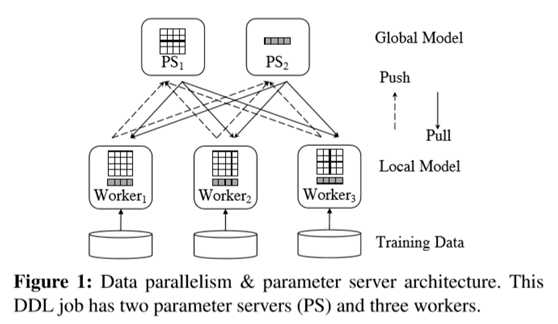
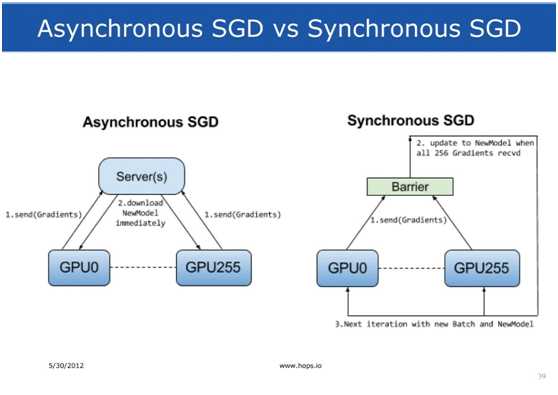
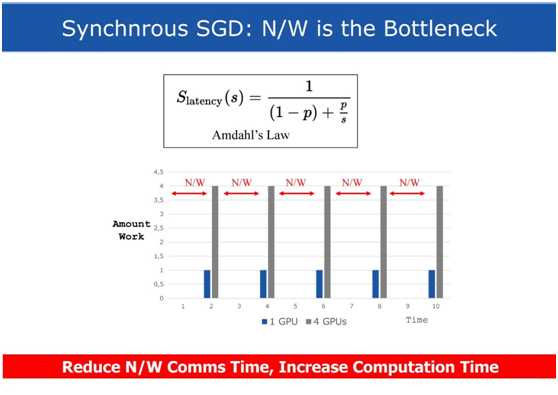
如上图所示,每一个Worker有一个GPU,运行本地的深度学习模型副本,训练集被划分成等大小的部分分配给Worker们,所有的任务同步训练,一个被观察到的事实是这样的架构能够更快的收敛,相比于异步的分布式训练。
固定时间的迭代
深度学习训练是按迭代的方式工作的,在每一个轮次,worker要做一次前向和反向的计算,接着worker将本地的结果互相更新深度学习模型,称之为模型聚集(Model
Aggregation),由于每一个迭代的计算时间都是差不多的,故迭代的时间是高度可预测的。
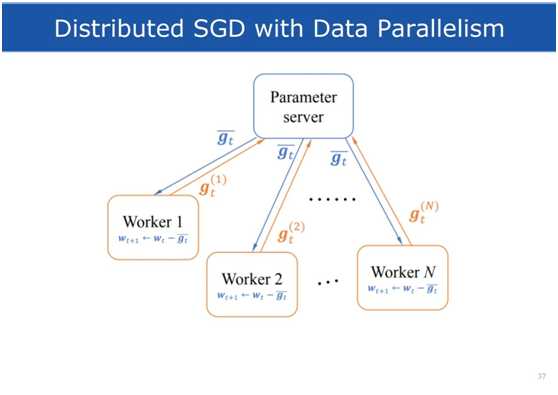
参数服务器架构
参数服务器,简称PS(Parameter
Server),这种架构是最流行的模型聚集的方法,参数服务器掌握主要的深度学习模型副本,使用从所有worker那里得到的本地结果来更新模型,然后worker在每个迭代的一开始拉回参数来更新本地的模型,一个深度学习任务可以有多个参数服务器。
测试和错误的探索
为了得到一个高质量的模型,需要对超参数的各种组合进行探索,称为超参数调优(hyperparameter-tuning),用户可以用AutoML等搜索工具来进行高效的探索。在AutoML中,许多带着不同超参数设置的深度学习任务被生成来训练相同的任务,其中的大多数由于随机的误差或者低质量的提升会被消除。利用一开始测试阶段的反馈,AutoML能够搜索新的参数配置以及产生大量新的任务,当然其中只有少数拥有较高的质量。
深度学习与计算系统结合是现在业界发展的趋势。Logical Clocks的CEO Jim Dowling讲述了分布式深度学习最新技术发展,以及其Hosworks开源平台。
二.分布式深度学习DDL

人工智能的需求在过去十年中显著增长,很大程度是深度学习的进步。这种增长是由深度(机器)学习技术的进步和利用硬件加速的能力推动的。然而,为了提高预测的质量和使机器学习解决方案在更复杂的应用中可行,需要大量的训练数据。尽管小型机器学习模型可以用适量的数据进行训练,但用于训练较大模型(如神经网络)的输入随着参数的数量呈指数增长。由于对处理训练数据的需求已经超过了计算机器计算能力的增长,因此需要将机器学习工作量分散到多台机器上,并将集中式系统转变为分布式系统。这些分布式系统提出了新的挑战,首先是训练过程的有效并行化和一致模型的创建。
分布式深度学习有很多好处——使用更多的GPU更快地训练模型,在许多GPU上并行超参数调优,并行消融研究以帮助理解深度神经网络的行为和性能。随着Spark 3.0的出现,GPU开始转向执行器,使用PySpark的分布式深度学习现在成为可能。然而,PySpark给迭代模型开发带来了挑战——从开发机器(笔记本电脑)开始,然后重新编写它们以运行在基于集群的环境中。
本讲座概述了分布式深度学习的技术,并提供了可用系统的概述,从而对该领域当前的最新技术进行了广泛的概述。
Jim Dowling是 Logical Clocks公司的首席执行官,也是KTH皇家理工学院的副教授。他是开源的Hopsworks平台的首席架构师,这是一个横向可扩展的机器学习数据平台。

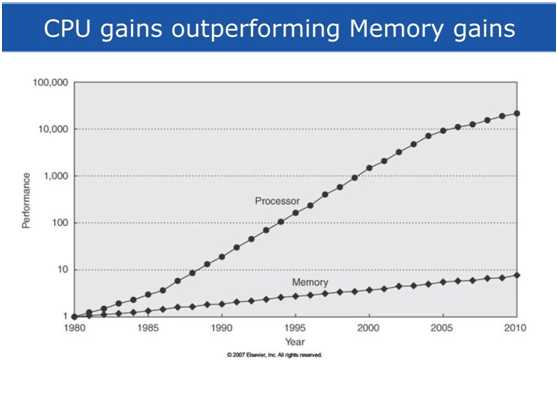
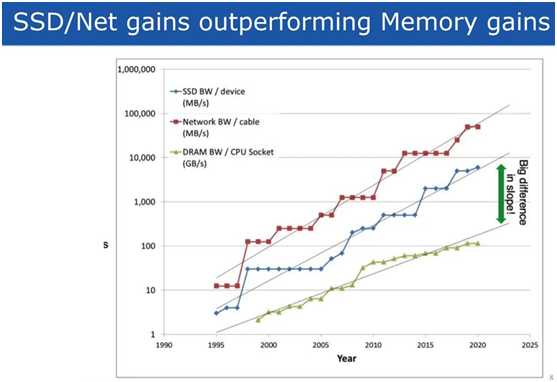

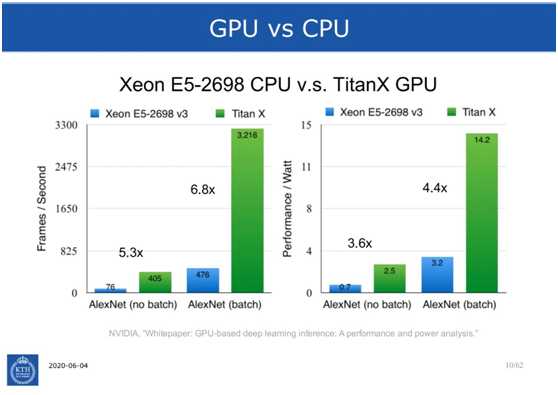
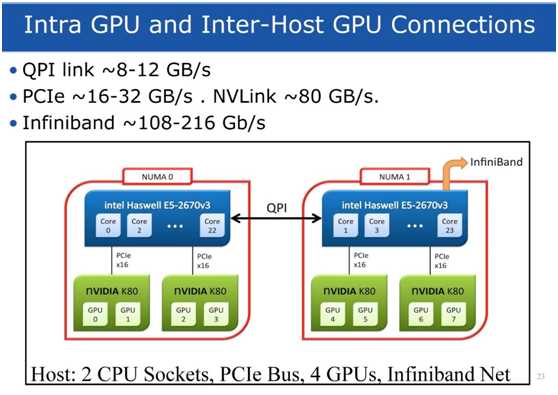
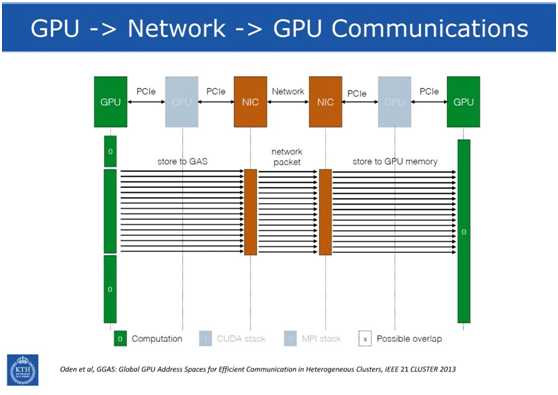
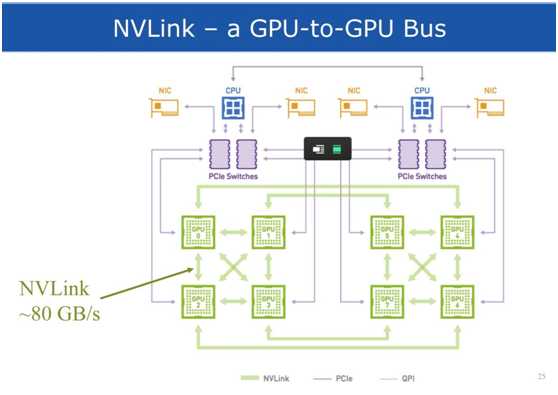






标签:分布式 聚集 reg 产生 硬件加速 pac 助理 dimen src
原文地址:https://www.cnblogs.com/wujianming-110117/p/13070160.html