标签:learn 样本 打开 检查 分数 strip tar get numpy
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?】
· 防止过拟合的方法:
(1)增加样本量(适用任何模型)。
(2)如果数据稀疏,使用L1正则,其他情况,使用L2。
L1正则,通过增大正则项导致更多参数为0,参数系数化降低模型复杂度,从而抵抗过拟合。
L2正则,通过使得参数都趋于0,变得很小,降低模型的抖动,从而抵抗过拟合。
(3)通过特征选择,剔除一些不重要的特征,从而降低模型复杂度。
(4)减少使用过度复杂的特征构造工程,保持原特征
(5)检查业务逻辑,判断特征有效性,如是否在用结果预测结果等。
(6)逻辑回归特有的防止过拟合方法:进行离散化处理,所有特征都离散化。
· 正则化防止过拟合的原理:
(1)L2正则(也叫权重衰减),通过约束参数的范数使系数不要太大,可以在一定程度上减少过拟合情况。
(2)L1正则,在L2的基础上,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
【2.用logiftic回归来进行实践操作,数据不限。】
从氙气病预测病马死亡率
(1)划分数据集
1 from sklearn.linear_model import LogisticRegression 2 from sklearn.metrics import accuracy_score 3 import numpy as np 4 import matplotlib.pyplot as plt 5 6 frTrain = open(‘./data/horseColicTraining.txt‘) # 打开训练集 7 frTrain.close() 8 frTest = open(‘./data/horseColicTest.txt‘) # 打开测试集 9 frTest.close() 10 11 training_set = [] 12 training_labels = [] 13 testing_set = [] 14 testing_labels = [] 15 # 解析训练集中的数据特征和Labels 16 # training_set 中存储训练数据集的特征,training_labels 存储训练数据集的样本对应的分类标签 17 for line in frTrain.readlines(): 18 curr_line = line.strip().split(‘\t‘) 19 line_array = [] 20 for i in range(len(curr_line)): 21 line_array.append(float(curr_line[i])) 22 training_set.append(line_array) 23 training_labels.append(float(curr_line[-1])) 24 25 # 测试集同理 26 for line in frTest.readlines(): 27 curr_line = line.strip().split(‘\t‘) 28 line_array = [] 29 for i in range(len(curr_line)): 30 line_array.append(float(curr_line[i])) 31 testing_set.append(line_array) 32 testing_labels.append(float(curr_line[-1])) 33 34 35 # 划分为训练集和测试集 36 X_train, X_test, y_train, y_test = training_set, testing_set, training_labels, testing_labels
(2)构建模型
1 model = LogisticRegression() 2 model.fit(X_train, y_train) 3 pre = model.predict(X_test)
(3)模型预测
1 # 打印准确率 2 print(‘正确率:‘, accuracy_score(y_test, pre)) 3 # 截距/权重:model.intercept_/ model.coef_

(4)可视化
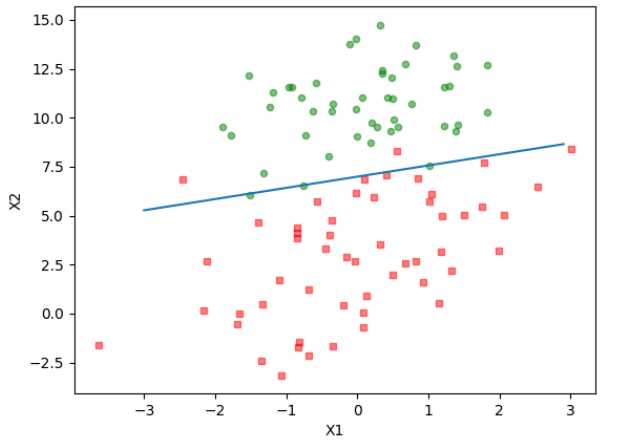
1 # 截距/权重:model.intercept_/ model.coef_ 2 # column_stack 将两个数组/矩阵按列合并,transpose 数组转换为矩阵 3 weights = np.column_stack((model.intercept_, model.coef_)).transpose() 4 5 n = np.shape(X_train)[0] 6 7 X_train = np.mat(X_train) # 转化为矩阵 8 9 xcord1 = [] 10 ycord1 = [] 11 xcord2 = [] 12 ycord2 = [] 13 for i in range(n): 14 if int(y_train[i]) == 1: 15 xcord1.append(X_train[i, 0]) # 生存 16 ycord1.append(X_train[i, 1]) 17 else: 18 xcord2.append(X_train[i, 0]) # 死亡 19 ycord2.append(X_train[i, 1]) 20 fig = plt.figure() 21 ax = fig.add_subplot(111) 22 ax.scatter(xcord1, ycord1, s=30, c=‘red‘, marker=‘s‘) 23 ax.scatter(xcord2, ycord2, s=30, c=‘green‘) 24 x_ = np.arange(-3.0, 3.0, 0.1) 25 y_ = (-weights[0] - weights[1] * x_) / weights[2] 26 ax.plot(x_, y_) 27 plt.xlabel(‘x1‘) 28 plt.ylabel(‘x2‘) 29 plt.show()
标签:learn 样本 打开 检查 分数 strip tar get numpy
原文地址:https://www.cnblogs.com/WEJACKSI/p/13070346.html