标签:love dfs 修改 down 第一个 monit 共享 出现 image
将宕机的master下线哨兵简介哨兵(sentinel)是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的master并将所有slave连接到新的master
哨兵的作用
- 监控
不断的检查master和slave是否正常运行
master存活检测,master和slave运行情况检测
- 通知(提醒)
当被监控的服务器出现问题时,向其他(哨兵间,客户端)发送通知
- 自动故障转移
断开master和slave连接,选取一个slave作为master,将其他slave连接到新的master,并告知客户端的服务器地址
注意:
哨兵也是一台redis服务器,只是不提供数据服务
通常哨兵配置数量为单数
配置哨兵
环境:
为了快速完操实验操作,这里采用了单机多实例的方式
[root@CombCloud-2020110836 conf]# pwd
/opt/redis-5.0.9/conf
[root@CombCloud-2020110836 conf]# cat redis-6379.conf
port 6379
daemonize no
dir "/data/redis/data"
dbfilename "dump-6379.rdb"
rdbcompression yes
rdbchecksum yes
save 10 2
appendonly yes
appendfsync always
appendfilename "appendonly-6379.aof"
bind 127.0.0.1
[root@CombCloud-2020110836 conf]# cat redis-6380.conf
port 6380
daemonize no
dir "/data/redis/data"
replicaof 127.0.0.1 6379
[root@CombCloud-2020110836 conf]# cat redis-6381.conf
port 6381
daemonize no
dir "/data/redis/data"
replicaof 127.0.0.1 6379
[root@CombCloud-2020110836 conf]# cat sentindel-26379.conf
port 26379
daemonize no
pidfile /var/run/redis-sentinel.pid
logfile ""
dir /data/redis/data
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
[root@CombCloud-2020110836 conf]# cat sentindel-26380.conf
port 26380
daemonize no
pidfile "/var/run/redis-sentinel.pid"
logfile ""
dir "/data/redis/data"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
[root@CombCloud-2020110836 conf]# cat sentindel-26381.conf
port 26381
daemonize no
pidfile "/var/run/redis-sentinel.pid"
logfile ""
dir "/data/redis/data"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
先启动Mast
哨兵搭建
[root@CombCloud-2020110836 redis-5.0.9]# pwd
/opt/redis-5.0.9
[root@CombCloud-2020110836 redis-5.0.9]# cat sentinel.conf | egrep -v ‘^$|^#‘
port 26379
daemonize no
pidfile /var/run/redis-sentinel.pid
logfile ""
dir /tmp
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
[root@CombCloud-2020110836 redis-5.0.9]# #mymaster名字可以随便起,连接的Master名字可以自定义, 连接服务器,2是代表如果有两台服务器认定master已死,则宣传master死记,通知设置哨兵数量的一半加1,所以哨兵数量必须为奇数
sentinel monitor mymaster 127.0.0.1 6379 2
#三十秒连接不上Master,则判断定master已死
sentinel down-after-milliseconds mymaster 30000
#新的master上任一次有多少个开始同步
sentinel parallel-syncs mymaster 1
#三分钟同步没完成算超时
sentinel failover-timeout mymaster 180000
#先启动master再启动slave,再启动哨兵
1、启动master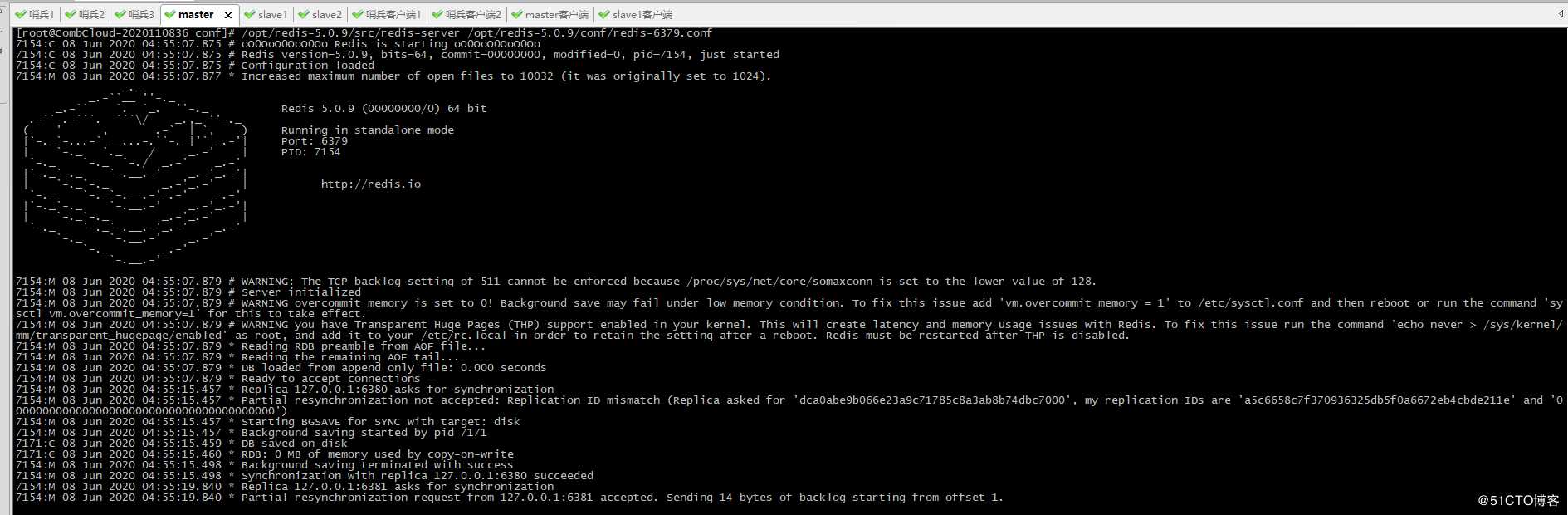
2、启动slave1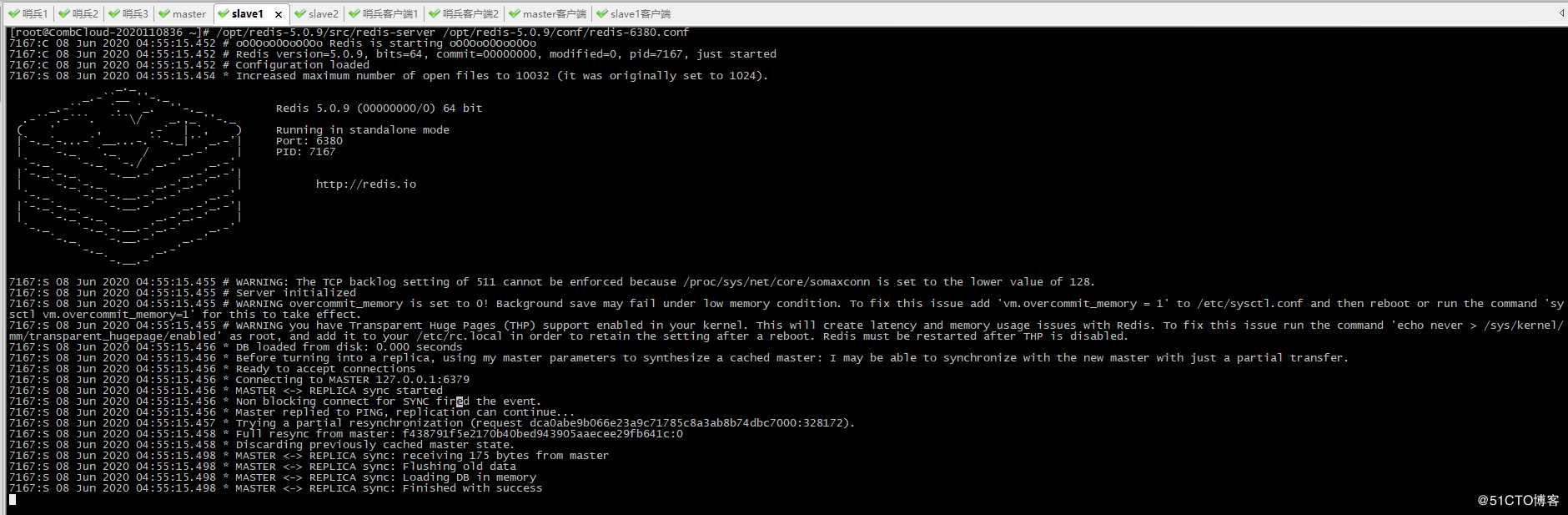
3、启动slave2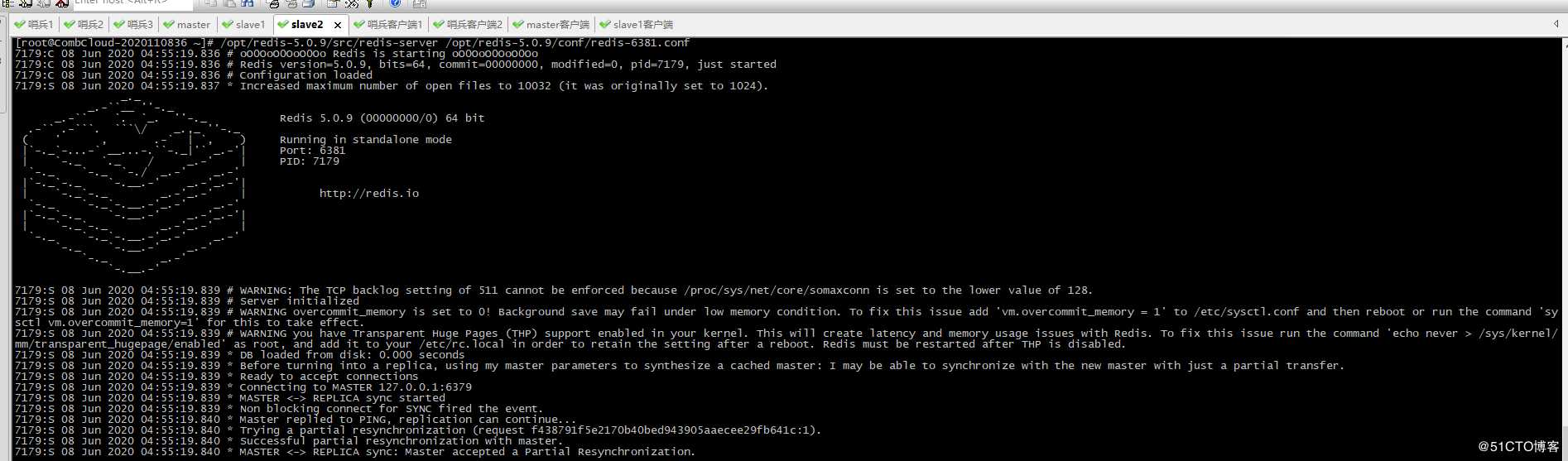
4、启动第一个哨兵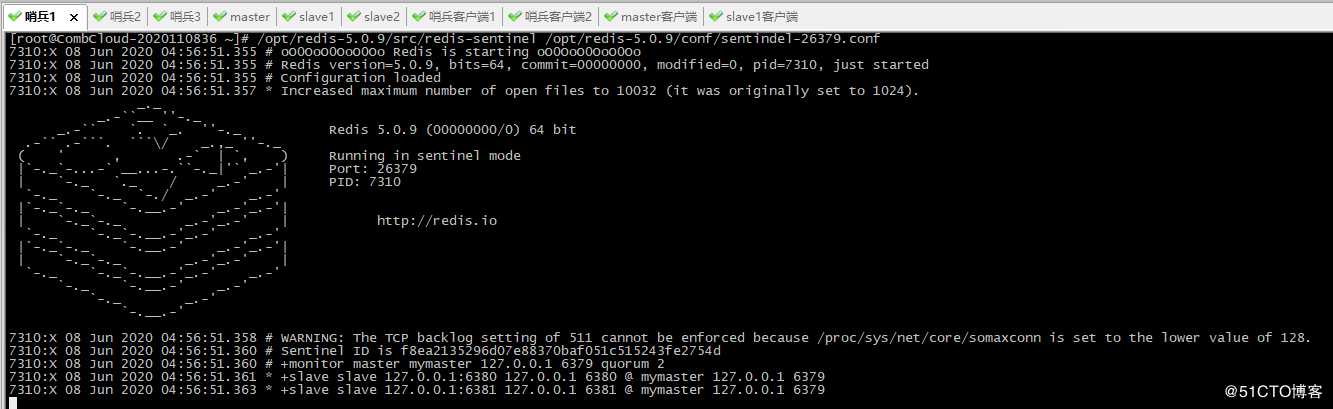
可以看到6380及6381在连接master主6379端口
7310:X 08 Jun 2020 04:56:51.361 +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
7310:X 08 Jun 2020 04:56:51.363 +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
哨兵1客户端配置文件发生变化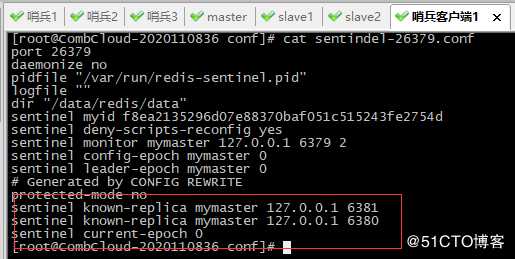
5、启动第二个哨兵
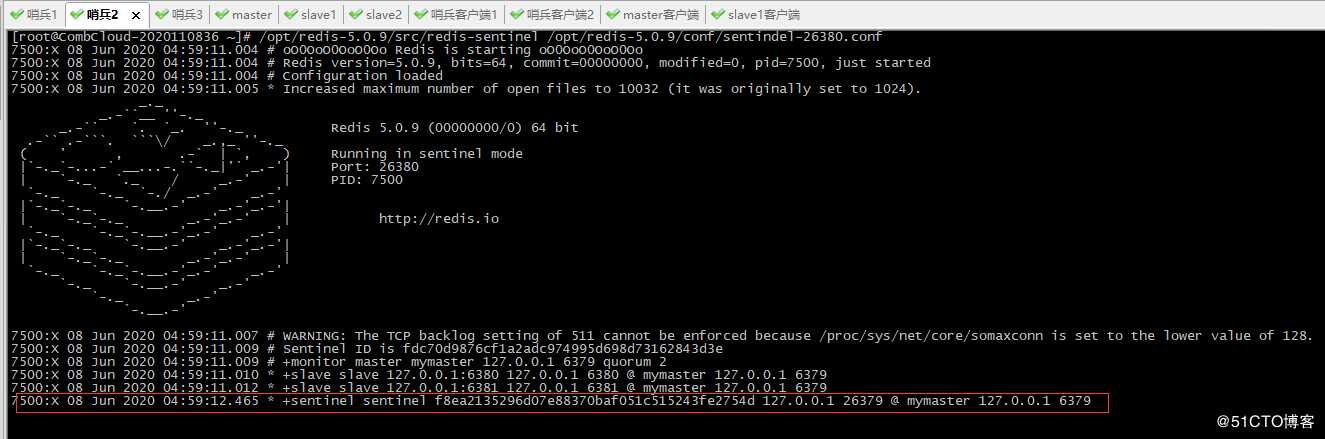
可以看到26379即第一个哨兵在监控6379master
6、启动第三个哨兵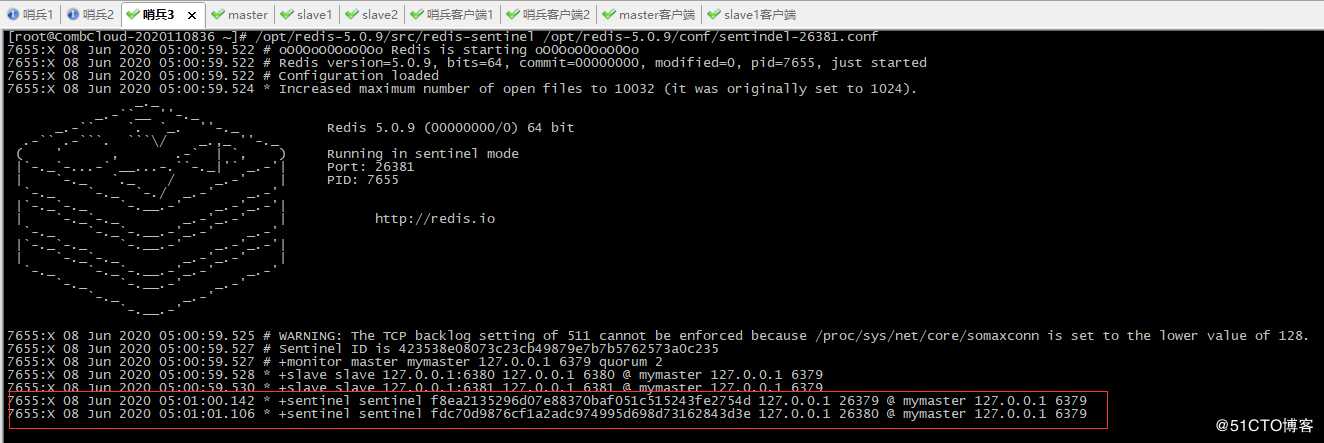
可以看到26379及26380在监控6379端口
7、此时再次查看三个哨兵配置文件发生变化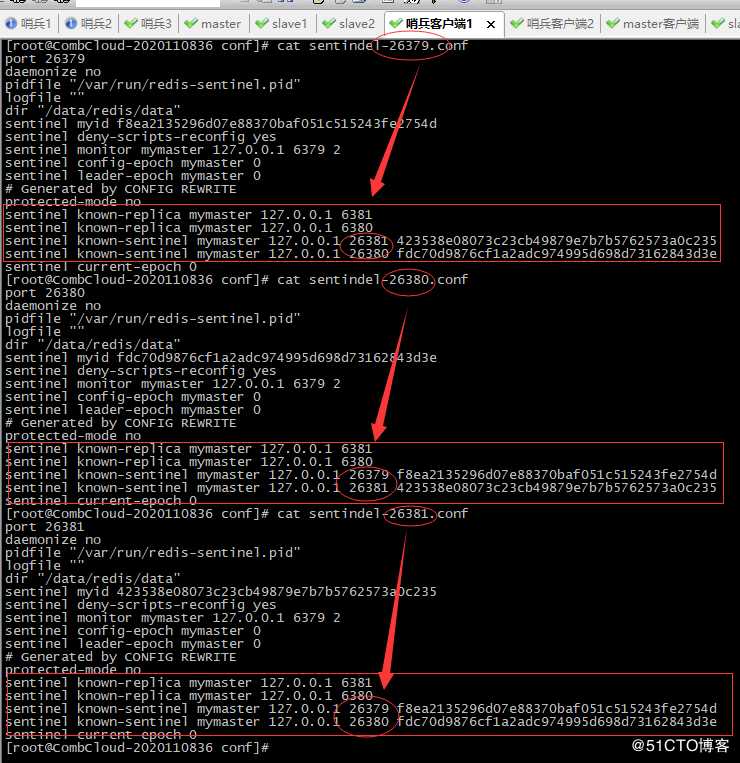
26379配置文件可以发现从库有6380和6381,及哨兵监控26380和26381
8、查看监听端口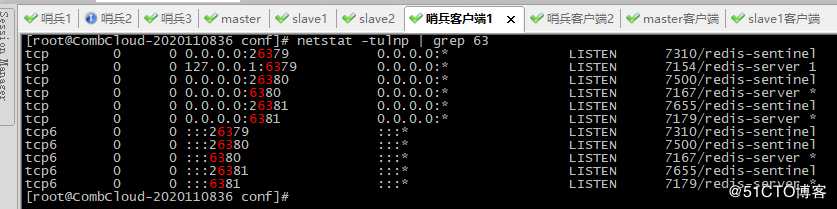
9、关闭master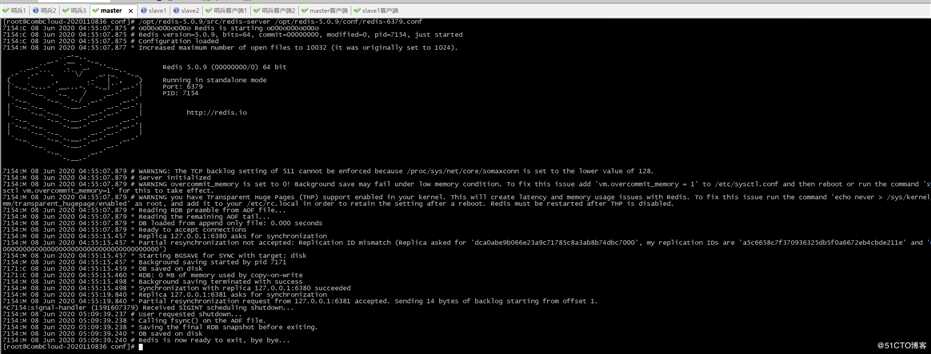
10、随便找一台哨兵日志输出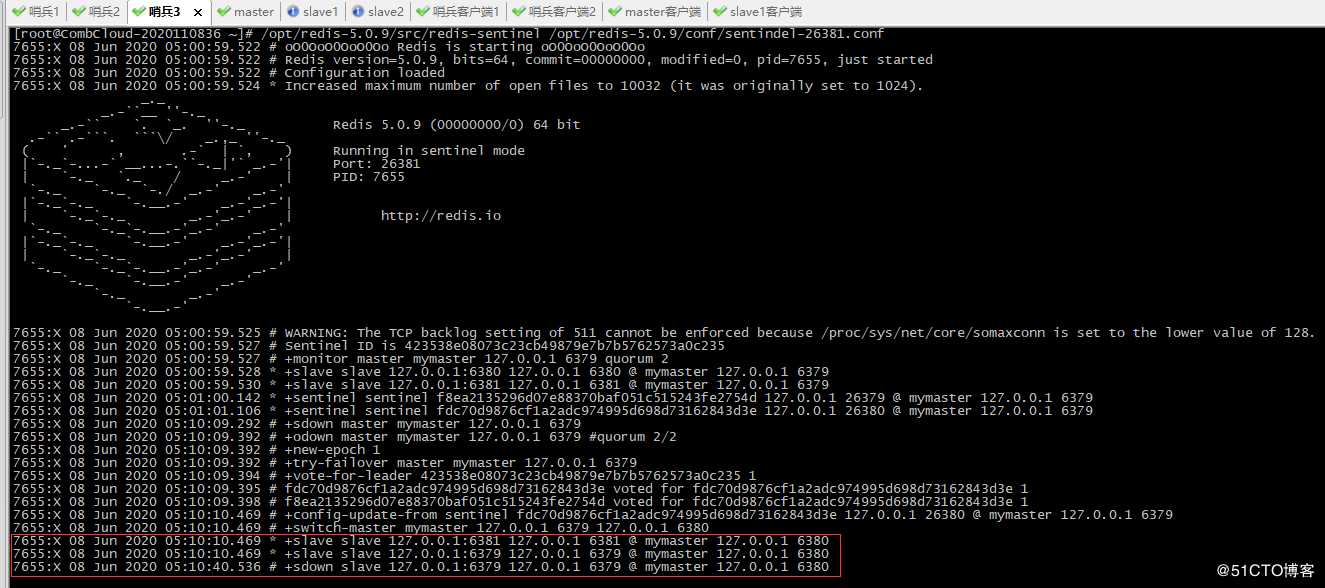
从日志最后三行可以看到
6380实例的redis已被选为Master,移除故障实例6379
11、查看6379,6380,6381配置文件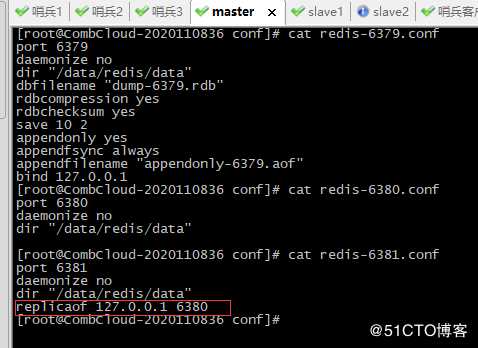
可看到redis6380配置文件已删除slaveof,而6381配置文件指定的主为6380
12、重新启动6379的master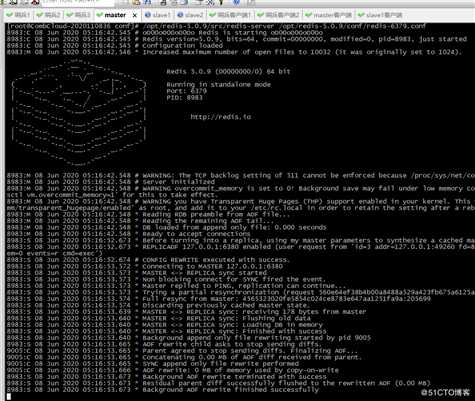
查看哨兵已把这台主机从新加入监控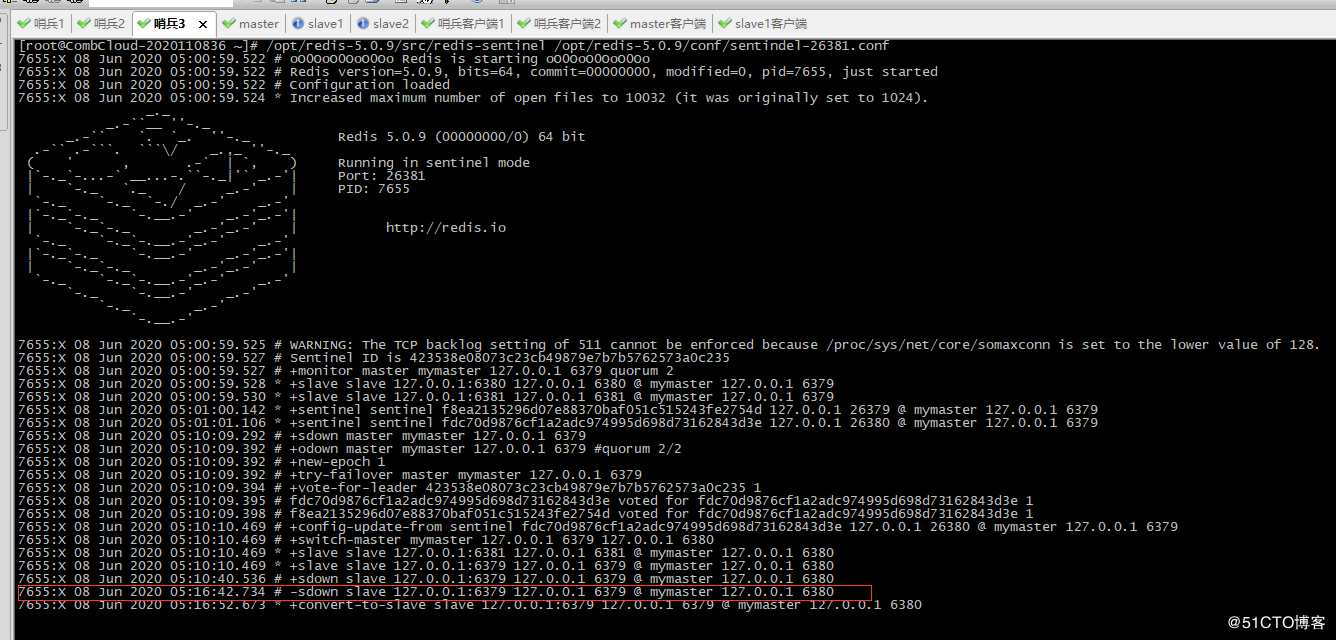
13、查看配置6379配置文件,该实例从新加入了集群成为了slave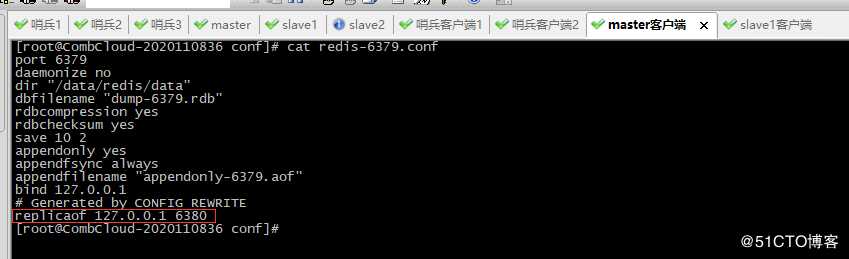
集群搭建及主从故障切换过程演示完成
哨兵工作原理
三个阶段概述
阶段一:监控阶段
用于同步各个节点的状态信息
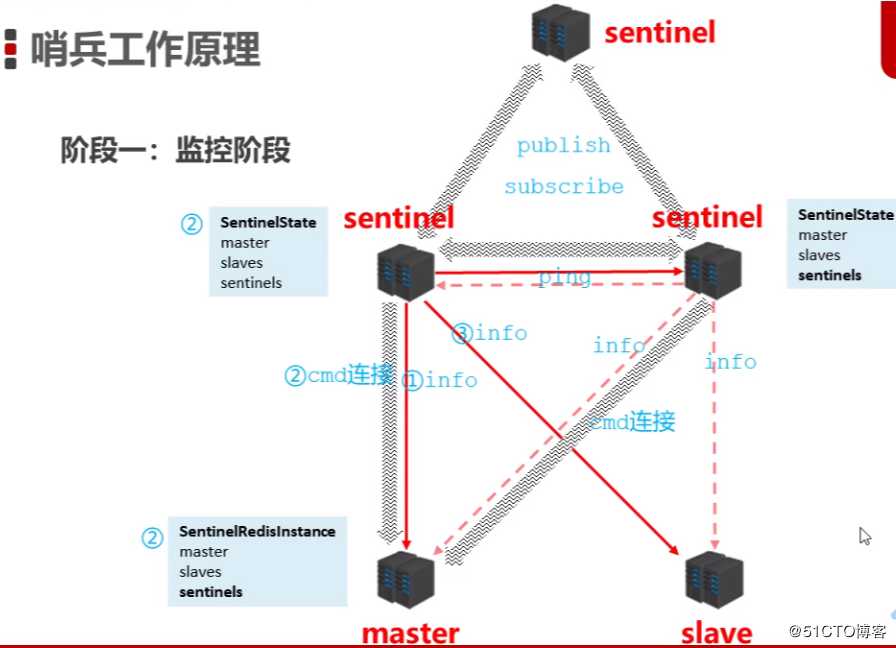
原理解释:
1、哨兵先通过info获取master的各种状态(runid,role)信息,保存所有的哨兵状态(sentinestate,master,slaves,sentinels)
2、sentinel通过cmd连接master进行命令交换,通过命令连接获取工作状态
3、master保存所有redis实例的信息(sentineredislnstance,master,slave,sentinels)
4、哨兵通过info获取slave的各种状态(runid,role,master_host,,master_port,offset)信息
5、哨兵通过cmd连接slave进行命令交换
6、sentinel集群通过发布订阅进行信息共享,通过ping查看对方有没有存活
阶段二:通知阶段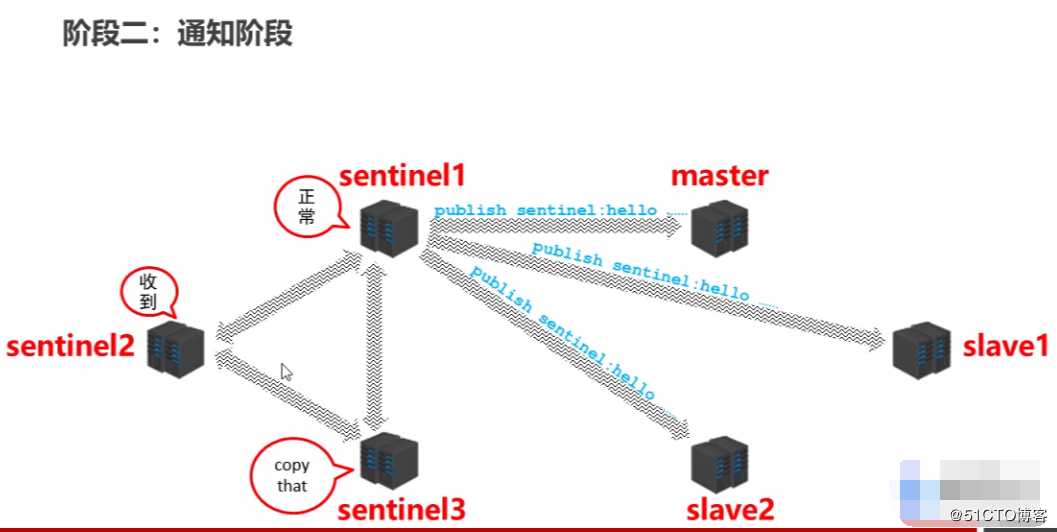
原理解释:
任意一台sentinel通过cmd命令连接获取master和slave的状态,对master和slave发布消息hello,拿到对服务器响应的信息后,会再在几个sentinel频道里面进行信息传播
阶段三:故障转移阶段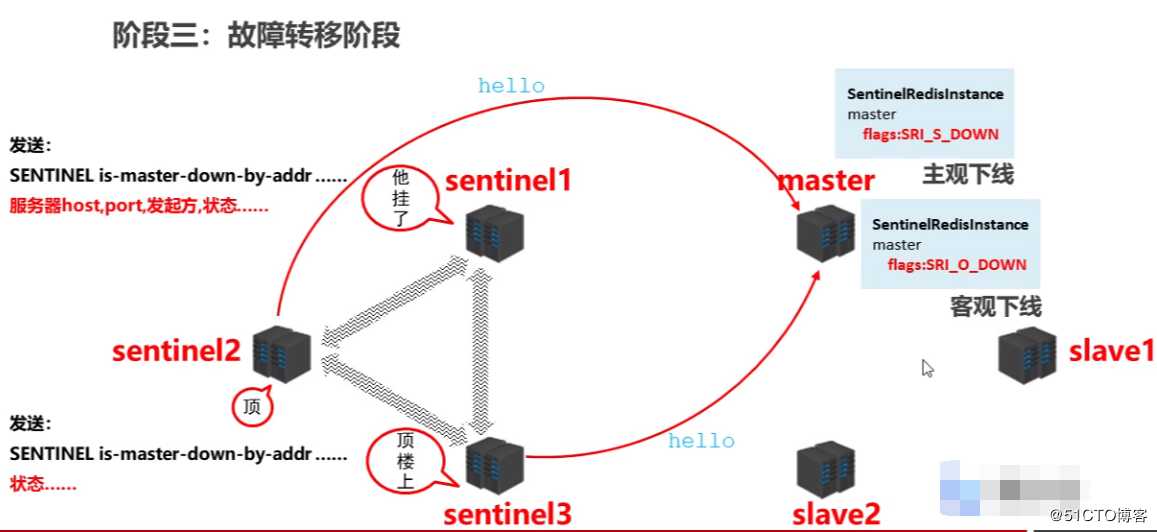
1、任意一台sentinel去对master主机发送hello,经过在配置的指定时间发送多次master不回复,sentinel认为master已死亡,给标记状态为flags:SRL_S_DOWN,此为第一个哨兵发现死亡,为主观下线
2、sentinel在sentinel频道发送is-master-down-by-addr告知master已死亡
3、其他sentinel去对Master发送hello消息,经确认发现在master确实已死亡,此时master状态为flags:SRL_O_DOWN,此为客观下线,即配置文件里配置的只要认为有2人或以上认同master已下线,则为客观下线
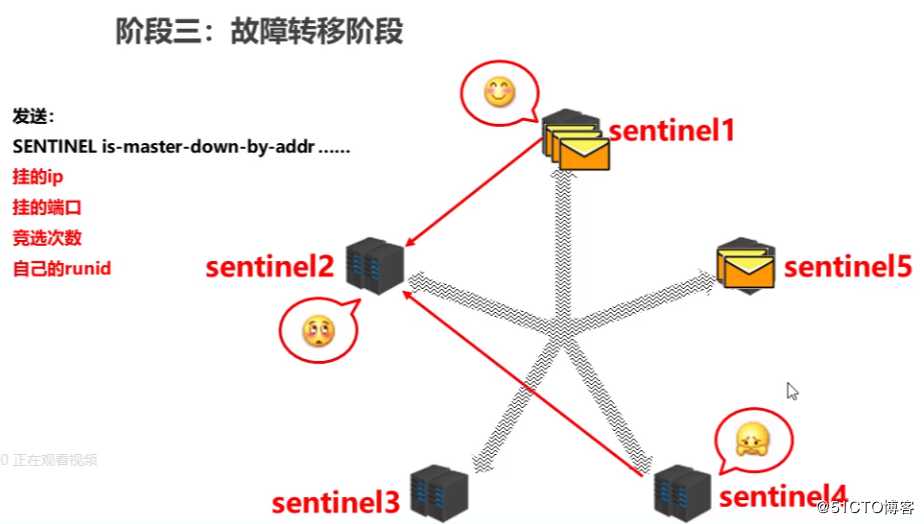
各sentinel通过发送挂的ip,挂的端口,竟选次数,自已的runid,进行参加竟选投票,先发出来要投票的sentinel,被后面的setninel收到,则投他一票,票数多的通过竟选成为选择新master的权利者
标签:love dfs 修改 down 第一个 monit 共享 出现 image
原文地址:https://blog.51cto.com/yht1990/2502563