标签:手工 读取数据 结果 streaming exe nap ring 存储 保存
一、概述
Savepoint 是检查点的一种特殊实现,底层实现其实也是使用 Checkpoint 的机制。
Savepoint 是用户以手工命令的方式触发 Checkpoint,并将结果持久化到指定的存储路径
中,其主要目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维
或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实
现从端到端的 Exactly-Once 语义保证。
1)配置 Savepoints 的存储路径
在 flink-conf.yaml 中配置 SavePoint 存储的位置,设置后,如果要创建指定 Job 的 SavePoint,
可以不用在手动执行命令时指定 SavePoint 的位置。
state.savepoints.dir: hdfs:/hadoop101:9000/savepoints
2)在代码中设置算子ID
为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐通过手动给算子赋予 ID,
这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。
而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改时很敏感的。因此,强烈建议手动设置 ID。
package com.apple.flink.savepoints import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment object TestSavepoints { def main(args: Array[String]): Unit = { val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ //读取数据到DataStream val stream = streamEnv.socketTextStream("hadoop101", 8888).uid("mySource-001") stream.flatMap(_.split(" ")) .uid("flapMap-001") .map((_, 1)) .uid("map=001") .keyBy(0) .sum(1) .uid("sum-001") .print() //启动流计算 streamEnv.execute("wc") } }
3)触发 SavePoint
//先启动Job [root@hadoop101 bin]# ./flink run -c com.bjsxt.flink.state.TestSavepoints -d /home/Flink-Demo-1.0-SNAPSHOT.jar //再取消Job ,触发SavePoint [root@hadoop101 bin]# ./flink savepoint 6ecb8cfda5a5200016ca6b01260b94ce
[root@hadoop101 bin]# ./flink cancel 6ecb8cfda5a5200016ca6b01260b94ce
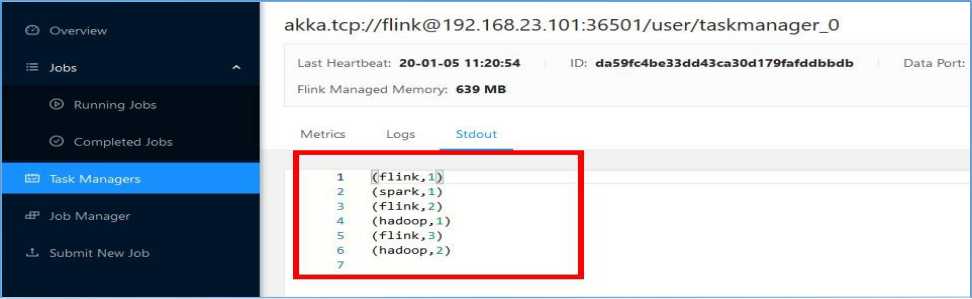

4)从 SavePoint 启动 Job
[root@hadoop101 bin]# ./flink run -s \
hdfs://hadoop101:9000/savepoints/savepoint-6ecb8c-e56ccb88576a \
-c com.bjsxt.flink.state.TestSavepoints \
-d /home/Flink-Demo-1.0-SNAPSHOT.jar
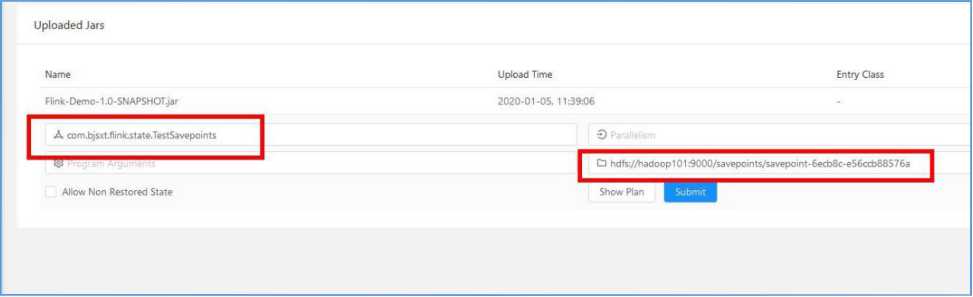
也可以通过 Web UI 启动 Job:
标签:手工 读取数据 结果 streaming exe nap ring 存储 保存
原文地址:https://www.cnblogs.com/alen-apple/p/13072227.html