标签:控制器 其他 mamicode 物理 规模 领导 全面 协调器 发送消息
为什么会有ZooKeeper我们知道要写一个分布式应用是非常困难的,主要原因就是局部故障。一个消息通过网络在两个节点之间传递时,网络如果发生故障,发送方并不知道接收方是否接收到了这个消息。有可能是收到消息以后发生了网络故障,也有可能是没有收到消息,又或者可能接收方的进程死了。发送方唯一的确认方法就是再次连接发送消息,并向他进行询问。这就是局部故障:根本不知道操作是否失败。因此,大部分分布式应用需要一个主控、协调控制器来管理物理分布的子进程。所以大部分应用需要开发私有的协调程序,协调程序的反复编写浪费时间,这个时候就需要一个通用的、伸缩性好的协调器。就是因为这样的场景,ZooKeeper应运而生,ZooKeeper的设计目的,就是为了减轻分布式应用程序所承担的协调任务。
ZooKeeper常用的应用场景
01 / 分布式协调
分布式协调简单说就是有人对ZooKeeper中的数据做了监听,如果修改了ZooKeeper中被监听的数据,ZooKeeper反过来会告诉给发起监听的人数据的变更。比如在Kafka的设计中,Kafka的一个节点在ZooKeeper中创建了一个数据,Kafka的策略是谁创建了这个数据谁就是Kafka集群的主节点,其余的节点都会去监听这个数据。如果主节点宕机了,这ZooKeeper对应的数据就会发生变更,既而监听这个数据的其余节点就会感知到主节点宕机了,然后重新进行选举。
02 / 元数据管理
很多分布式的程序需要集中式的管理自己的元数据,这个时候ZooKeeper就是一个很好的选择。比如Kafka,Storm等分布式的工具就会把集群里核心的元数据存放在ZooKeeper中。
03 / 高可用
很多分布式的项目都是主从式的架构,正常情况下集群里有一个是主节点,其余的都是从节点。但是如果只有一个主节点的话,程序就会有单点故障问题,那么这个时候就需要部署多个主节点实现高可用了,利用ZooKeeper从多个主节点中选出一个作为master,其余的作为StandBy。比如鼎鼎大名的HDFS就是靠ZooKeeper实现的高可用。
04 / 分布式锁
在企业里面很多的项目需要分布式锁,我们可以使用ZooKeeper搞分布式锁,不过这儿大家要注意一点,ZooKeeper确实是可以搞分布式锁的,但是ZooKeeper不支持太高的并发,也就是说如果是高并发的情况下,分布式锁用ZooKeeper可能也不太适合,如果在高并发的情况下建议大家使用Redis去搞分布式锁,但是并发不太高的情况下用ZooKeeper搞分布式锁是比较方便的,也有很多人确实是这么使用的。
ZooKeeper核心原理
01 / ZooKeeper集群架构
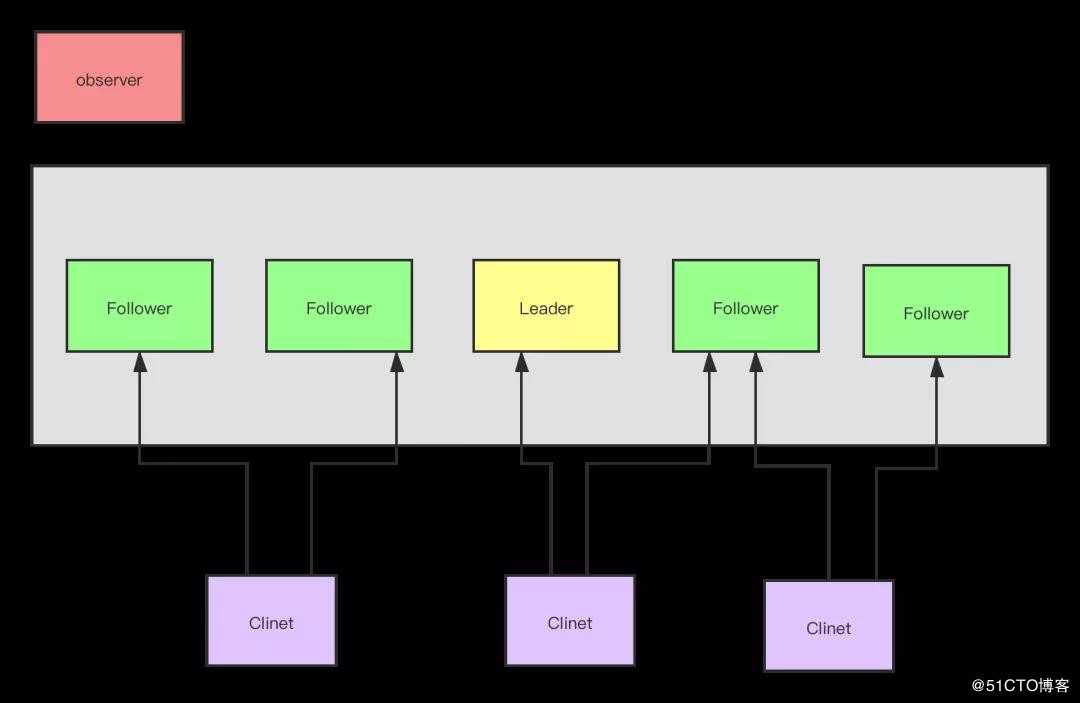
在ZooKeeper集群当中,集群中的服务器角色分为leader和learner,learner又分为observer和follower,具体功能如下:
0x01、leader(领导者)
为客户端提供读和写的功能,负责投票的发起和决议,集群里面只有leader才能接受写的服务。
0x02、follower(跟随者)
为客户端提供读服务,如果是写的服务则转发给leader。在选举过程中进行投票。
0x03、observer(观察者)
为客户端提供读服务,如果是写服务就转发个leader。不参与leader的选举投票。也不参与写的过半原则机制。在不影响写的前提下,提高集群读的性能,此角色于zookeeper3.3系列新增的角色。
0x04、client(客户端)
连接zookeeper集群的使用者,请求的发起者,独立于zookeeper集群的角色。
02 / ZooKeeper读写机制
在ZooKeeper的选举中,如果过半的节点都选一个节点为leader的话,那么这个节点就会是leader节点,也就是因为这个原因,ZooKeeper集群,只要有过半的节点是存活的,那么这个ZooKeeper就可以正常的提供服务。比如有5个ZooKeeper节点,其中有2个节点宕机了,这个时候还有3个节点存活,存活个数超过半数,此时集群还是正常提供服务,所以ZooKeeper集群本生是没有高可用问题的。又因为存活的判断依据是超过半数,所以我们一般搭建ZooKeeper集群的时候,都使用奇数台,这样会比较节约机器,比如我们安装一个6台的ZooKeeper集群,如果宕机了3台就会导致集群不可用,因为这个时候存活的节点数没有超过半数了,所以6台和5台的效果是一样的,我们用5台比较合适。
对应一个ZooKeeper集群,我们可能有多个客户端,客户端能任意连接其中一台ZooKeeper节点,但是所有的客户端都只能往leader节点上面去写数据,所有的客户端能从所有的节点上面读取数据。如果有客户端连接的是follower节点,然后往follower上发送了写数据的请求,这个时候follower就会把这个写请求转发给leader节点处理。leader接受到写请求就会往其他节点(包括自己)同步数据,如果过半的节点接受到消息后发送回来ack消息,那么leader节点就对这条消息进行commit,commit后该消息就对用户可见了。因为需要过半的节点发送ack后,leader才对消息进行commit,这个时候会有一个问题,如果集群越大,那么等待过半节点发送回来ack消息这个过程就需要越久,也就是说节点越多虽然会增加集群的读性能,但是会影响到集群的写性能,所以我们一般建议ZooKeeper的集群规模在3到5个节点左右。为了解决这个问题,后来的ZooKeeper中增加了一个observer 的角色,这个节点不参与投票,只是负责同步数据。比如我们leader写数据需要过半的节点发送ack响应,这个observer节点是不参与过半的数量统计的。它只是负责从leader同步数据,然后提供给客户端读取,所以引入这个角色目的就是为了增加集群读的性能,然后不影响集群的写性能。用户搭建集群的时候可以自己设置该角色。
03 / Zookeeper 特点
0x01、一致性
client客户端无论连接到集群中的哪个节点,读到的数据都是一样的
0x02、实时性
ZooKeeper保证客户端在一定的时间间隔内获得结果,包括成功和失败,但是由于网络延迟原因,ZooKeeper不能保证两台客户端同时得到刚更新的消息。如果都需要最新的消息需要调用sync()接口。
0x03、原子性
leader在同步数据的时候,同步过程保证事务性,要么都成功,要么都失败。
0x04、顺序性
一台服务器上如果消息a在消息b前发布,那么所有的server上的消息a都是在消息b前发布的。
04 / Zookeeper数据一致性保证
刚刚我们看到了ZooKeeper有多个特点,但是我相信多个特点中,大家最好奇都就是Zookeeper是如何保证数据一致性的。ZooKeeper保证数据一致性用的是ZAB协议。通过这个协议来进行ZooKeeper集群间的数据同步,保证数据的一致性。
0x01、两阶段提交+过半写机制
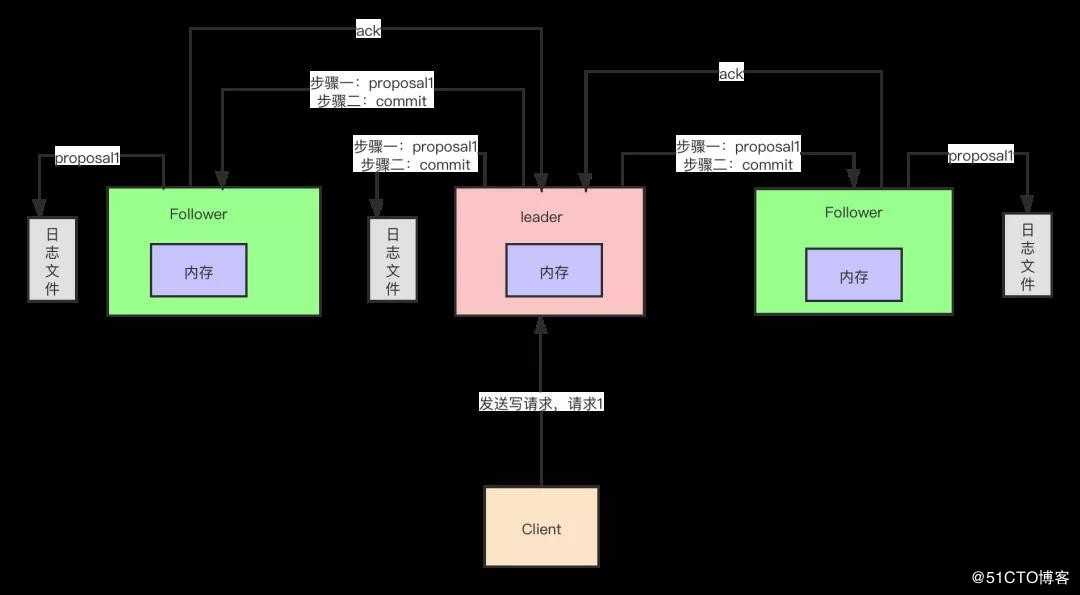
ZooKeeper写数据的机制是客户端把写请求发送到leader节点上(如果发送的是follower节点,follower节点会把写请求转发到leader节点),leader节点会把数据通过proposal请求发送到所有节点(包括自己),所有到节点接受到数据以后都会写到自己到本地磁盘上面,写好了以后会发送一个ack请求给leader,leader只要接受到过半的节点发送ack响应回来,就会发送commit消息给各个节点,各个节点就会把消息放入到内存中(放内存是为了保证高性能),该消息就会用户可见了。那么这个时候,如果ZooKeeper要想保证数据一致性,就需要考虑如下两个情况,情况一:leader执行commit了,还没来得及给follower发送commit的时候,leader宕机了,这个时候如何保证消息一致性?情况二:客户端把消息写到leader了,但是leader还没发送proposal消息给其他节点,这个时候leader宕机了,leader宕机后恢复的时候此消息又该如何处理?
0x02、ZAB的崩溃恢复机制
针对情况一,当leader宕机以后,ZooKeeper会选举出来新的leader,新的leader启动以后要到磁盘上面去检查是否存在没有commit的消息,如果存在,就继续检查看其他follower有没有对这条消息进行了commit,如果有过半节点对这条消息进行了ack,但是没有commit,那么新对leader要完成commit的操作。
0x03、ZAB恢复中删除数据机制
针对情况二,客户端把消息写到leader了,但是leader还没发送portal消息给其他节点,这个时候leader宕机了,这个时候对于用户来说,这条消息是写失败的。假设过了一段时间以后leader节点又恢复了,不过这个时候角色就变为了follower了,它在检查自己磁盘的时候会发现自己有一条消息没有进行commit,此时就会检测消息的编号,消息是有编号的,由高32位和低32位组成,高32位是用来体现是否发生过leader切换的,低32位就是展示消息的顺序的。这个时候当前的节点就会根据高32位知道目前leader已经切换过了,所以就把当前的消息删除,然后从新的leader同步数据,这样保证了数据一致性。
最后
各位同学,ZooKeeper是我们学习架构的过程当中,非常非常重要的一个知识点,我们今天只是从其中一些角度去分析的ZooKeeper,我们后面会有很多文章从不同角度深入全面的剖析ZooKeeper,帮助大家掌握ZooKeeper,欢迎大家持续关注。
领取更多免费技术资料及视频
标签:控制器 其他 mamicode 物理 规模 领导 全面 协调器 发送消息
原文地址:https://blog.51cto.com/jssforever/2502977