标签:ide 出现 logs 调用 添加 时间 介绍 标记 表示
在前面两篇文章介绍了下载器中间件的使用,这篇文章将会介绍爬虫中间件(Spider Middleware)的使用。
爬虫中间件的用法与下载器中间件非常相似,只是它们的作用对象不同。下载器中间件的作用对象是请求request和返回response;爬虫中间件的作用对象是爬虫,更具体地来说,就是写在spiders文件夹下面的各个文件。它们的关系,在Scrapy的数据流图上可以很好地区分开来,如下图所示。
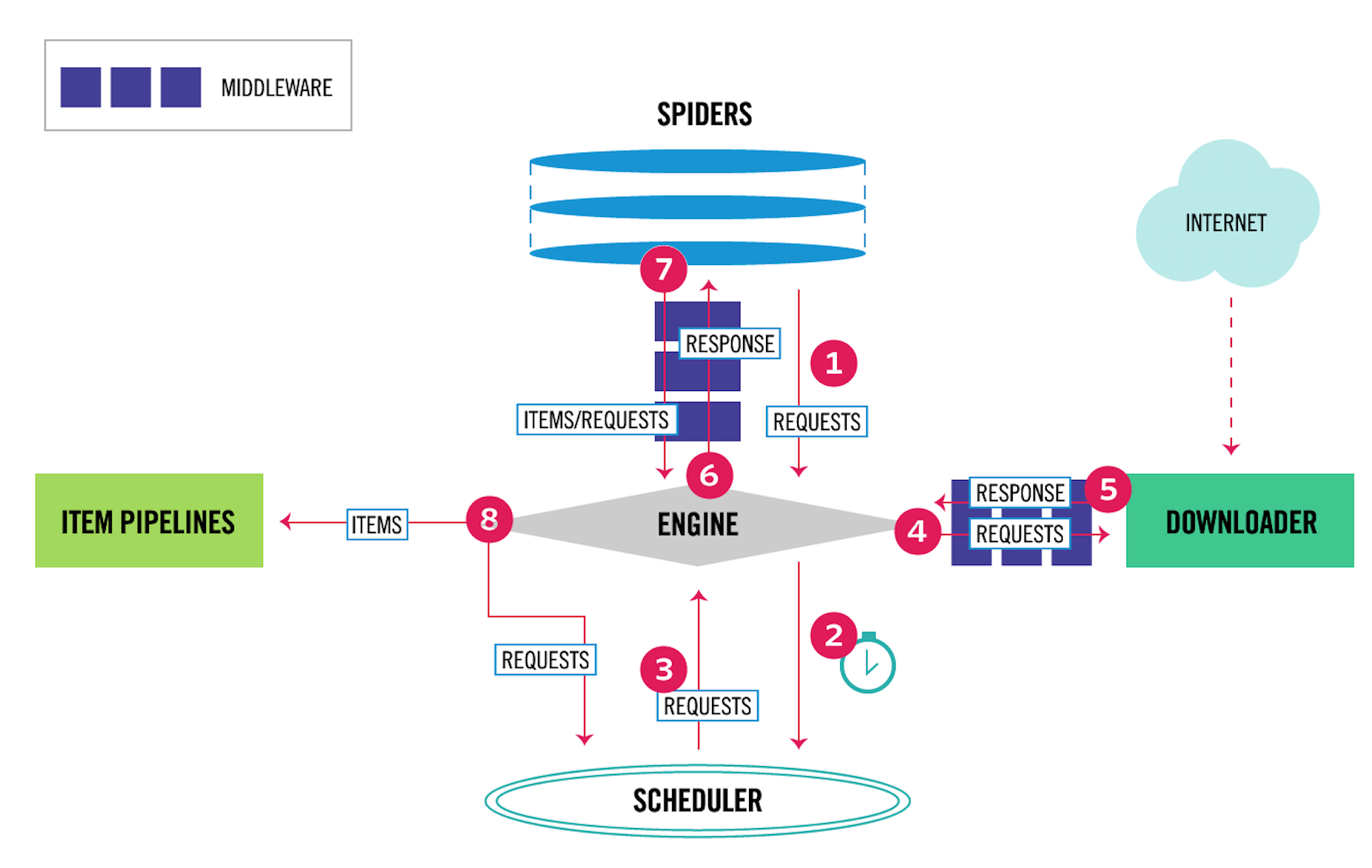
其中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。Exception的时候,爬虫中间件的process_spider_exception()方法被调用。parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
在爬虫中间件里面可以处理爬虫本身的异常。例如编写一个爬虫,爬取UA练习页面http://exercise.kingname.info/exercise_middleware_ua ,故意在爬虫中制造一个异常,如图12-26所示。
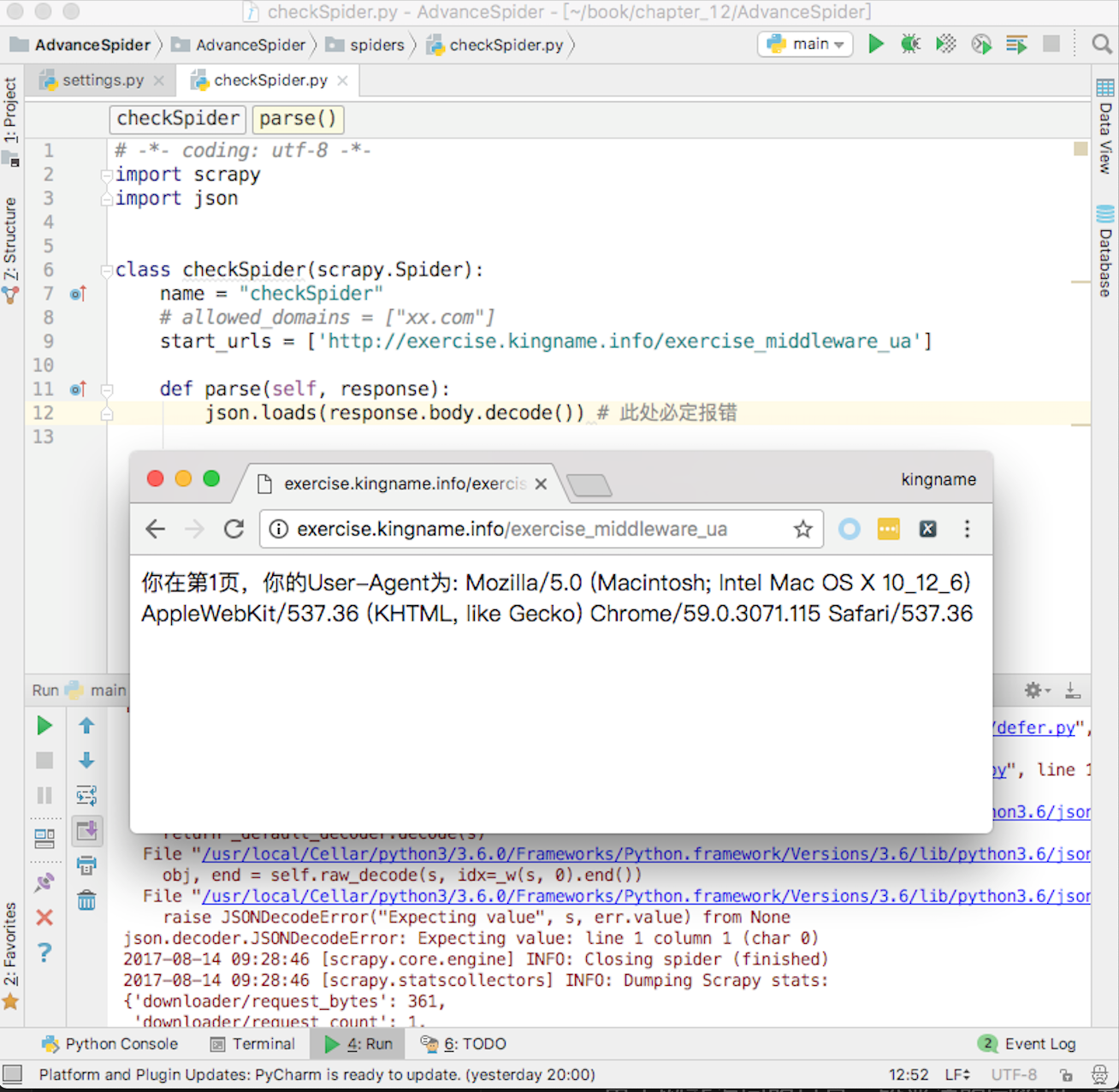
由于网站返回的只是一段普通的字符串,并不是JSON格式的字符串,因此使用JSON去解析,就一定会导致报错。这种报错和下载器中间件里面遇到的报错不一样。下载器中间件里面的报错一般是由于外部原因引起的,和代码层面无关。而现在的这种报错是由于代码本身的问题导致的,是代码写得不够周全引起的。
为了解决这个问题,除了仔细检查代码、考虑各种情况外,还可以通过开发爬虫中间件来跳过或者处理这种报错。在middlewares.py中编写一个类:
class ExceptionCheckSpider(object):
def process_spider_exception(self, response, exception, spider):
print(f‘返回的内容是:{response.body.decode()}\n报错原因:{type(exception)}‘)
return None
这个类仅仅起到记录Log的作用。在使用JSON解析网站返回内容出错的时候,将网站返回的内容打印出来。
process_spider_exception()这个方法,它可以返回None,也可以运行yield item语句或者像爬虫的代码一样,使用yield scrapy.Request()发起新的请求。如果运行了yield item或者yield scrapy.Request(),程序就会绕过爬虫里面原有的代码。
例如,对于有异常的请求,不需要进行重试,但是需要记录是哪一个请求出现了异常,此时就可以在爬虫中间件里面检测异常,然后生成一个只包含标记的item。还是以抓取http://exercise.kingname.info/exercise_middleware_retry.html这个练习页的内容为例,但是这一次不进行重试,只记录哪一页出现了问题。先看爬虫的代码,这一次在meta中把页数带上,如下图所示。

爬虫里面如果发现了参数错误,就使用raise这个关键字人工抛出一个自定义的异常。在实际爬虫开发中,读者也可以在某些地方故意不使用try ... except捕获异常,而是让异常直接抛出。例如XPath匹配处理的结果,直接读里面的值,不用先判断列表是否为空。这样如果列表为空,就会被抛出一个IndexError,于是就能让爬虫的流程进入到爬虫中间件的process_spider_exception()中。
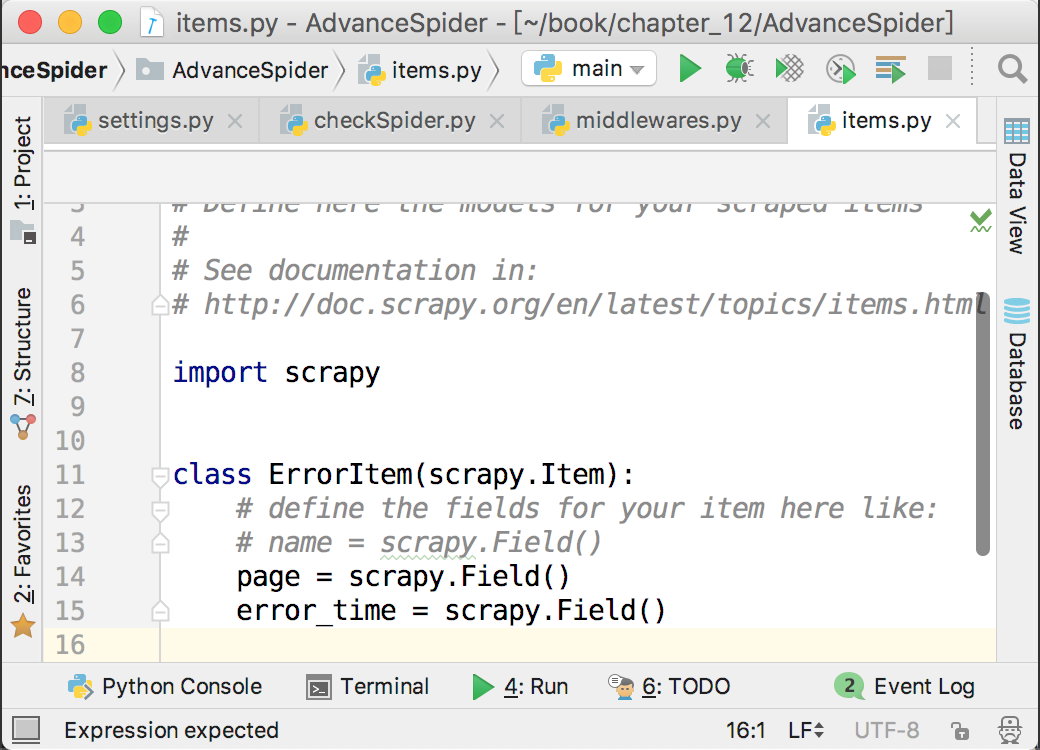
在items.py里面创建了一个ErrorItem来记录哪一页出现了问题,如下图所示。
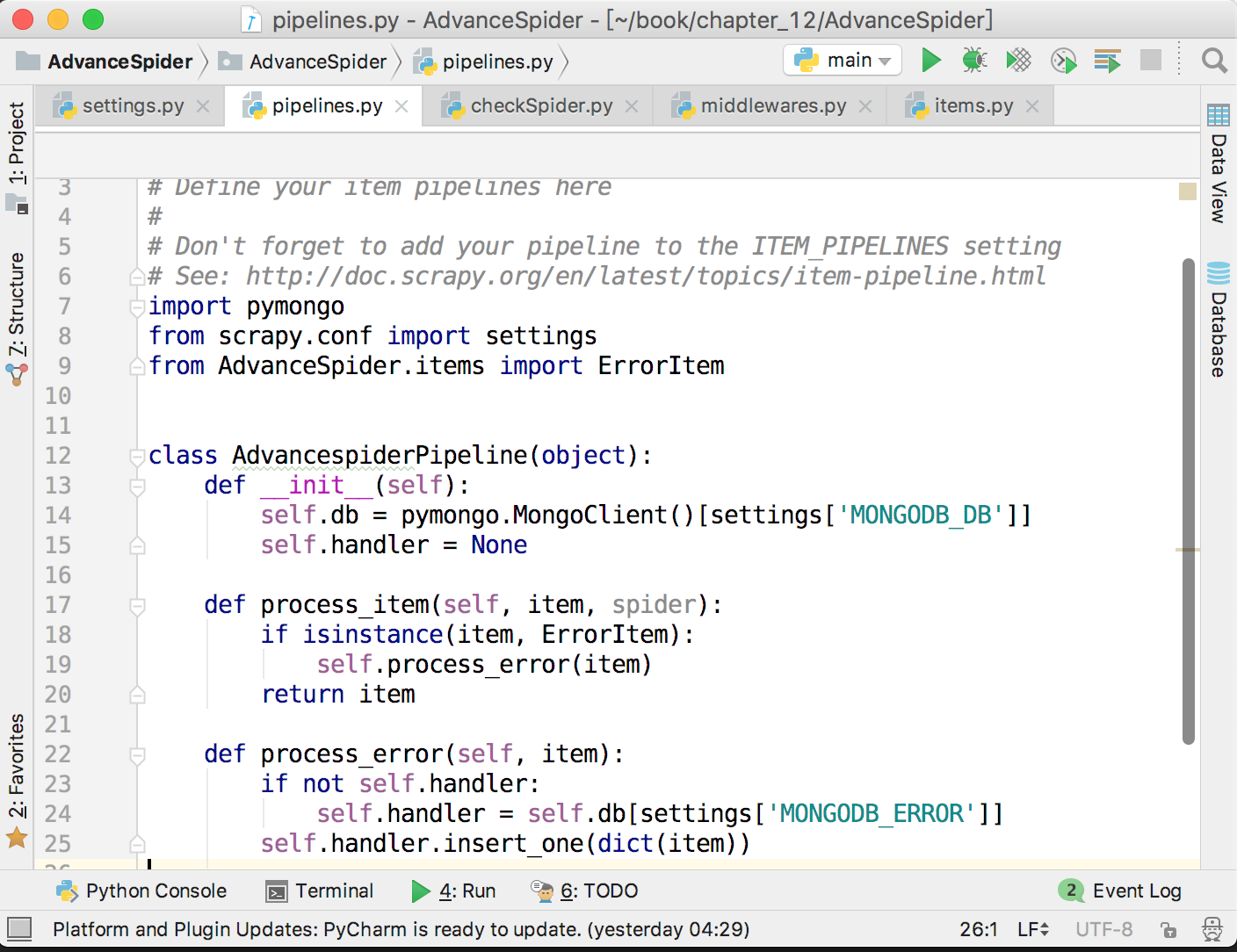
接下来,在爬虫中间件中将出错的页面和当前时间存放到ErrorItem里面,并提交给pipeline,保存到MongoDB中,如下图所示。
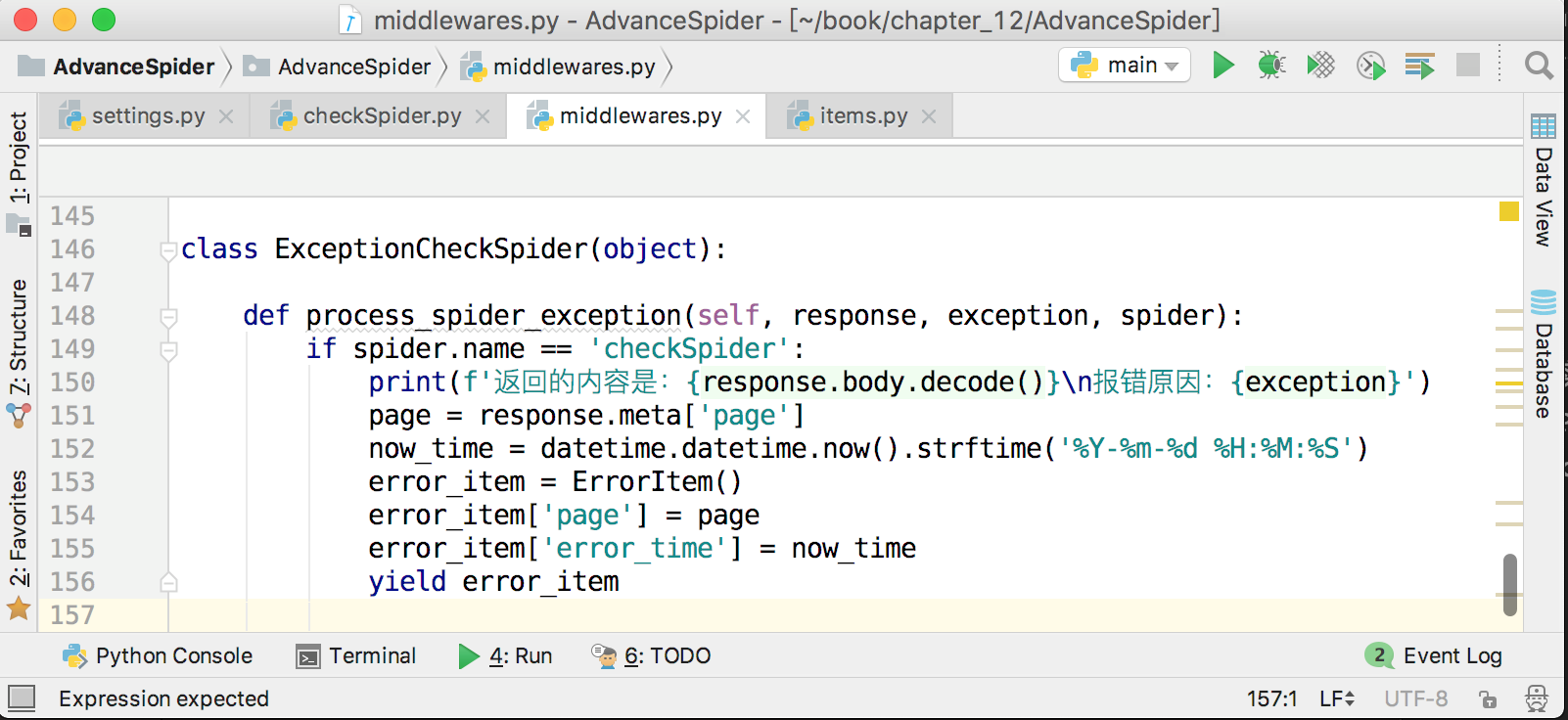
这样就实现了记录错误页数的功能,方便在后面对错误原因进行分析。由于这里会把item提交给pipeline,所以不要忘记在settings.py里面打开pipeline,并配置好MongoDB。储存错误页数到MongoDB的代码如下图所示。
爬虫中间件的激活方式与下载器中间件非常相似,在settings.py中,在下载器中间件配置项的上面就是爬虫中间件的配置项,它默认也是被注释了的,解除注释,并把自定义的爬虫中间件添加进去即可,如下图所示。
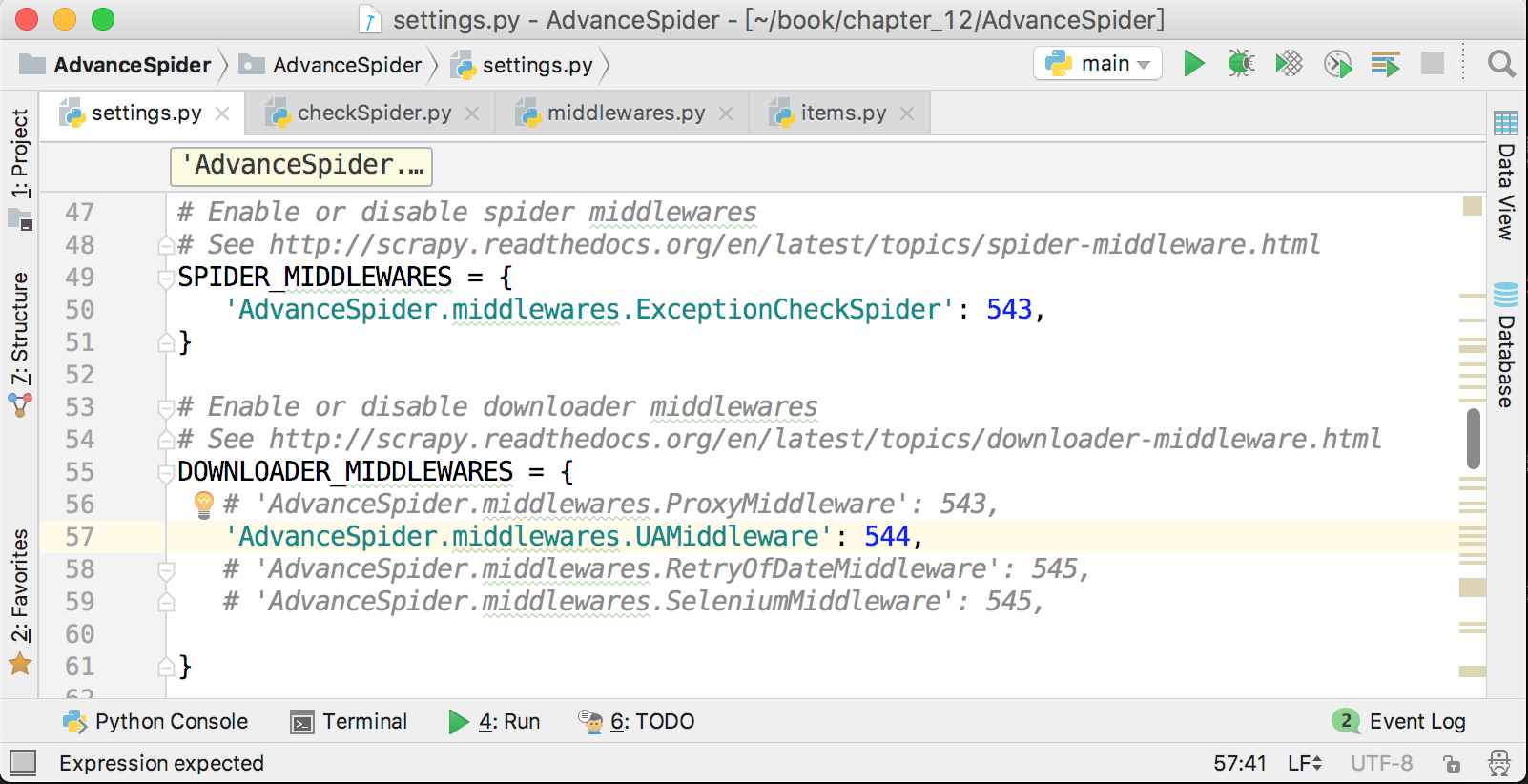
Scrapy也有几个自带的爬虫中间件,它们的名字和顺序如下图所示。

下载器中间件的数字越小越接近Scrapy引擎,数字越大越接近爬虫。如果不能确定自己的自定义中间件应该靠近哪个方向,那么就在500~700之间选择最为妥当。
在爬虫中间件里面还有两个不太常用的方法,分别为process_spider_input(response, spider)和process_spider_output(response, result, spider)。其中,process_spider_input(response, spider)在下载器中间件处理完成后,马上要进入某个回调函数parse_xxx()前调用。process_spider_output(response, result, output)是在爬虫运行yield item或者yield scrapy.Request()的时候调用。在这个方法处理完成以后,数据如果是item,就会被交给pipeline;如果是请求,就会被交给调度器,然后下载器中间件才会开始运行。所以在这个方法里面可以进一步对item或者请求做一些修改。这个方法的参数result就是爬虫爬出来的item或者scrapy.Request()。由于yield得到的是一个生成器,生成器是可以迭代的,所以result也是可以迭代的,可以使用for循环来把它展开。
def process_spider_output(response, result, spider):
for item in result:
if isinstance(item, scrapy.Item):
# 这里可以对即将被提交给pipeline的item进行各种操作
print(f‘item将会被提交给pipeline‘)
yield item
或者对请求进行监控和修改:
def process_spider_output(response, result, spider):
for request in result:
if not isinstance(request, scrapy.Item):
# 这里可以对请求进行各种修改
print(‘现在还可以对请求对象进行修改。。。。‘)
request.meta[‘request_start_time‘] = time.time()
yield request标签:ide 出现 logs 调用 添加 时间 介绍 标记 表示
原文地址:https://www.cnblogs.com/lincappu/p/13098810.html