标签:postgres postgresq user 请求 cto dir 需要 而且 等等
Pgpool-II 模式初步浅析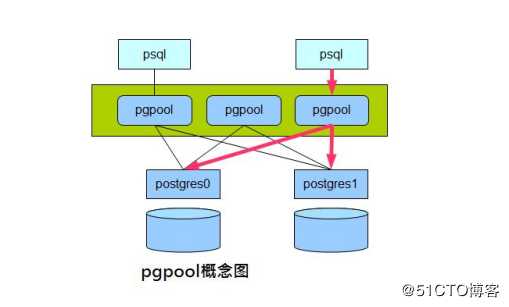
简单通俗的来讲,pgpool-II 是一个位于 PostgreSQL 服务器和 PostgreSQL 数据库客户端之间的中间件。pgpool-II主要提供负载均衡、连接池、复制、并行查询等等功能。Pgpool-ll可以运行在linux、solaris、FreeBSD以及基本上所有的类UNIX架构的平台。不支持Windows系统。
2.Pgpool-ll提供以下几种模式:
1)连接池模式
在连接池模式中,所有在原始模式中的功能以及连接池功能都可以使用连接池模,pgpool-ll保持已经连接到PostgreSql的服务器连接,通过使用相同参数连接重用,减少连接开销,增加系统总体吞吐量。使用连接池模式需要配置max_pool参数。
2)复制模式
通过管理连接多个PostgreSql服务器,使在两台及以上更多的后端节点中建立一个备份节点。要启用数据库复制功能,需要设置?pgpool.conf?文件中的?replication_mode?为 true。
replication_mode = true (pgpool-II 发送一份接收到的查询的拷贝到所有的数据库节点)
load_balance_mode = true(pgpool-II在数据库节点之间分发 SELECT 查询)
3)并行模式
为了在 pgpool-II 中启用并行查询,你必须设置另一个叫做“系统数据库”的数据库。主要目的是存储用户定义的用来确定数据将包含到哪个数据库中的规则,及使用 dblink 将从数据库节点发回的数据合并。
parallel_mode = true (启用并行查询功能)
仅仅设置?paralle_mode?为 true 不会自动启动并行查询。pgpool-II 需要系统数据库和用于分发数据到数据库节点的规则。而且系统数据库使用的 dblink 需要连接到 pgpool-II。因此需要设置?listen_addresses?以便 pgpool-II 接受这些连接。
listen_addresses = ‘*‘
PS:你可以同时拥有分区表和复制表。但是一个表不能同时被分区和复制。
4)主/备模式
依赖其他的复制,如snoly和流复制,但pgpool能把客户端的sql请求根据sql是查询还是修改发送到备库或主库。同时数据库节点信息需要设置,如备份相关hostname、port、directory、weight等,如果流复制直接配置recovery.conf。
primary_conninfo = ‘user=postgres application_name=192.168.1.116 \host=192.168.1.115 port=5432 sslmode=disable sslcompression=1‘
? pgpool-II 认为基于流复制启用了热备,也就是说备库是以只读方式打开的。在使用流复制的主/备模式中,如果主节点或者备节点失效,pgpool-II 可以被设置为触发一个故障切换。节点可以被自动断开而不需要进行更多设置。 当进行流复制的时候,备节点检查一个“触发文件”的存在,一旦发现它,则备节点停止持续的恢复并进入读写模式。通过使用这种功能,我们可以使备数据库在主节点失效的时候进行替换。
关于流复制的详细介绍篇幅有限,可以查看官网文档。
标签:postgres postgresq user 请求 cto dir 需要 而且 等等
原文地址:https://blog.51cto.com/10901766/2503989