标签:爬取 roc esc 对象 random python3 请求头 范围 future
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。Scrapy 使用了Twisted[‘tw?st?d]异步网络框架
文档地址:https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/commands.html
pip install Scrapy
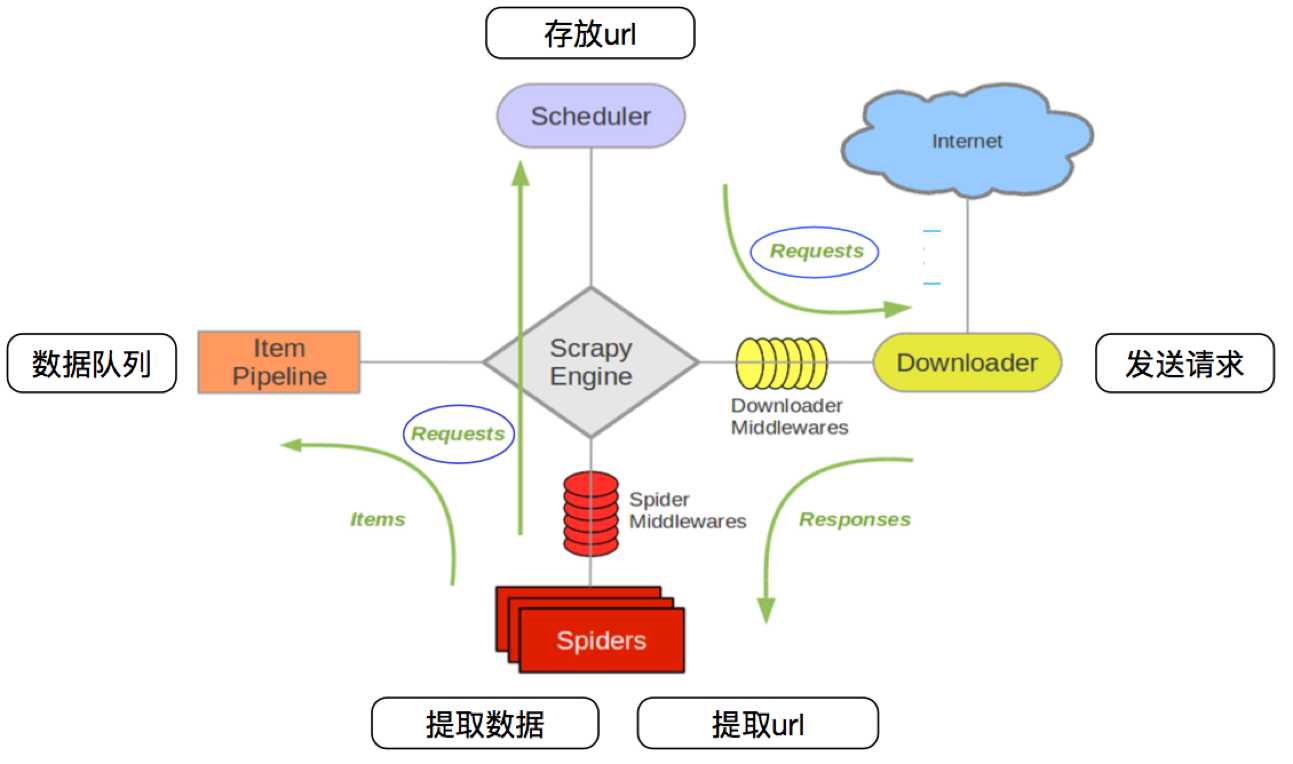
其流程可以描述如下:
注意:
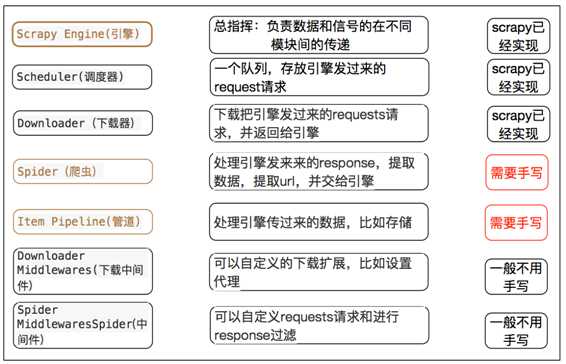
# 命令: scrapy startproject +<项目名字> #示例: scrapy startproject myspider
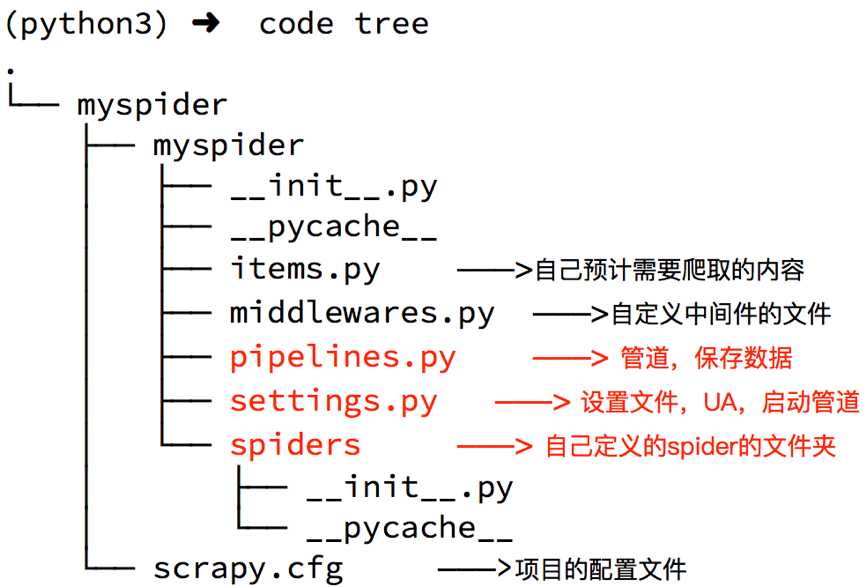
生成的目录和文件结果如下:
首先进入创建的项目目录里面的spiders目录,然后执行下面的命令创建爬虫
# 命令: scrapy genspider +<爬虫名字> + <允许爬取的域名> # 示例: scrapy genspider itcast itcast.cn

完善spider即通过方法进行数据的提取等操作
# -*- coding: utf-8 -*- import scrapy class ItcastSpider(scrapy.Spider): name = ‘itcast‘ # 爬虫名 [爬虫启动时,使用scrapy crawl itcast] allowed_domains = [‘itcast.cn‘] # 允许爬取的范围,防止爬虫爬到其他网站 start_urls = [‘http://www.itcast.cn/channel/teacher.shtml‘] # 爬虫最开始抓取的url地址 def parse(self, response): # 数据提取方法,处理start_url地址中的响应,接受下载中间件传过来的response响应 # 先分组,再进行数据的提取 li_list = response.xpath(‘//div[@class="tea_con"]/div/ul/li‘) for li in li_list: item = {} item[‘name‘] = li.xpath(‘.//h3/text()‘).extract_first() item[‘title‘] = li.xpath(‘.//h4/text()‘).extract_first() item[‘desc‘] = li.xpath(‘.//p/text()‘).extract_first() print(item) yield item # 将数据传给pipeline
注意:
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法extract() 返回一个包含有字符串的列表extract_first() 返回列表中的第一个字符串,列表为空没有返回None为什么要使用yield?
注意:
BaseItem, Request, dict, None

pipeline在settings中能够开启多个,为什么需要开启多个?
pipeline使用注意点
return item,否则后一个pipeline取到的数据为None值# 进去爬虫项目目录,执行以下命令 scrapy crawl "爬虫名"
对于要提取如下图中所有页面上的数据该怎么办?

回顾requests模块是如何实现翻页请求的:
思路:
使用方法
在获取到url地址之后,可以通过scrapy.Request(url,callback)得到一个request对象,通过yield关键字就可以把这个request对象交给引擎
# scrapy.Request的参数介绍 scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False]) # 括号中的参数为可选参数 # callback:表示当前的url的响应交给哪个函数去处理 # meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如# 下载延迟,请求深度等 # dont_filter:默认会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
# -*- coding: utf-8 -*- import re from copy import deepcopy import scrapy class SnSpider(scrapy.Spider): name = ‘sn‘ allowed_domains = [‘suning.com‘] start_urls = [‘https://book.suning.com/‘] def parse(self, response): # 解析数据 pass # 获取下一页url地址 next_part_url = "" yield scrapy.Request(next_part_url, callback=self.parse_book_list, meta={"item": deepcopy(item)}) # scrapy.Request()能构建一个request对象,同时指定提取数据的callback函数 def parse_next_list(self, response): # 处理下一页的数据提取
3. 添加User-Agent
同时可以再在setting中设置User-Agent:
USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36‘
定义Item的原因
定义item即提前规划好哪些字段需要抓取,scrapy.Field()仅仅是提前占坑,通过item.py能够让别人清楚自己的爬虫是在抓取什么,同时定义好哪些字段是需要抓取的,没有定义的字段不能使用,防止手2
定义Item

3. 使用Item
Item使用之前需要先导入并且实例化,之后的使用方法和使用字典相同
from yangguang.items import YangguangItem item = YangguangItem() #实例化
为了让我们自己希望输出到终端的内容能容易看一些,我们可以在setting中设置log级别
在setting中添加一行(全部大写):LOG_LEVEL = "WARNING”
默认终端显示的是debug级别的log信息
每次程序启动后,默认情况下,终端都会出现很多的debug信息,那么下面我们来简单认识下这些信息

为什么项目中需要配置文件
配置文件中的变量使用方法
settings.py中的重点字段和内涵
# USER_AGENT 设置ua # ROBOTSTXT_OBEY 是否遵守robots协议,默认是遵守 # CONCURRENT_REQUESTS 设置并发请求的数量,默认是16个 # DOWNLOAD_DELAY 下载延迟,默认无延迟 # COOKIES_ENABLED 是否开启cookie,即每次请求带上前一次的cookie,默认是开启的 # DEFAULT_REQUEST_HEADERS 设置默认请求头 # SPIDER_MIDDLEWARES 爬虫中间件,设置过程和管道相同 # DOWNLOADER_MIDDLEWARES 下载中间件
open_spider和close_spider 的方法在管道中,除了必须定义process_item之外,还可以定义两个方法:
open_spider(spider) :能够在爬虫开启的时候执行一次close_spider(spider) :能够在爬虫关闭的时候执行一次所以,上述方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
下面的代码分别以操作文件和mongodb为例展示方法的使用:


回顾之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址上面,这个过程能更简单一些么?
思路:
对应的crawlspider就可以实现上述需求,匹配满足条件的url地址,才发送给引擎,同时能够指定callback函数
scrapy genspider –t crawl itcast itcast.cn
spider中默认生成的内容如下,其中重点在rules中
LinkExtractor,callback和followLinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理follow:表示进过连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会class Itcast1Spider(CrawlSpider): name = ‘itcast1‘ allowed_domains = [‘itcast.cn‘] start_urls = [‘http://itcast.cn/‘] rules = ( Rule(LinkExtractor(allow=r‘Items/‘), callback=‘parse_item‘, follow=True), ) def parse_item(self, response): i = {} #使用xpath进行数据的提取或者url地址的提取 return i
指定两个正则规则,匹配url
rules = (
Rule(LinkExtractor(allow=r‘position_detail.php\?id=\d+&keywords=&tid=0&lid=0‘), callback=‘parse_item‘),
Rule(LinkExtractor(allow=r‘position.php\?&start=\d+#a‘), follow=True),
)
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class TcSpider(CrawlSpider): name = ‘tc‘ allowed_domains = [‘tencent.com‘] start_urls = [‘https://hr.tencent.com/position.php‘] rules = ( Rule(LinkExtractor(allow=r‘position_detail.php\?id=\d+&keywords=&tid=0&lid=0‘), callback=‘parse_item‘), Rule(LinkExtractor(allow=r‘position.php\?&start=\d+#a‘), follow=True), ) def parse_item(self, response): item = {} # i[‘domain_id‘] = response.xpath(‘//input[@id="sid"]/@value‘).extract() # i[‘name‘] = response.xpath(‘//div[@id="name"]‘).extract() # i[‘description‘] = response.xpath(‘//div[@id="description"]‘).extract() item["title"] = response.xpath("//td[@id=‘sharetitle‘]/text()").extract_first() # 提取标题 item[‘duty‘] = response.xpath("//div[text()=‘工作职责:‘]/following-sibling::ul[1]/li/text()").extract() item[‘require‘] = response.xpath("//div[text()=‘工作要求:‘]/following-sibling::ul[1]/li/text()").extract() print(item)


使用方法:
编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启
Downloader Middlewares默认的方法:
process_request(self, request, spider):
当每个request通过下载中间件时,该方法被调用。
返回None值:继续请求
返回Response对象:不在请求,把response返回给引擎
返回Request对象:把request对象交给调度器进行后续的请求
- 当下载器完成http请求,传递响应给引擎的时候调用 - 返回Resposne:交给process_response来处理 - 返回Request对象:交给调取器继续请求
3. 定义实现随机User-Agent的下载中间件
class UserAgentMiddleware(object): def process_request(self,request,spider): agent = random.choice(agents) request.headers[‘User-Agent‘] = agent
4. 定义实现随机使用代理的下载中间件
class ProxyMiddleware(object): def process_request(self,request,spider): proxy = random.choice(proxies) request.meta[‘proxy‘] = proxy
requests是如何模拟登陆的?
selenium是如何模拟登陆的?
scrapy来说,有两个方法模拟登陆:
1、直接携带cookie
2、找到发送post请求的url地址,带上信息,发送请求
携带cookie进行模拟登陆应用场景:
scrapy的start_requests方法的学习
scrapy中start_url是通过start_requests来进行处理的,其实现代码如下
def start_requests(self): cls = self.__class__ if method_is_overridden(cls, Spider, ‘make_requests_from_url‘): warnings.warn( "Spider.make_requests_from_url method is deprecated; it " "won‘t be called in future Scrapy releases. Please " "override Spider.start_requests method instead (see %s.%s)." % ( cls.__module__, cls.__name__ ), ) for url in self.start_urls: yield self.make_requests_from_url(url) else: for url in self.start_urls: yield Request(url, dont_filter=True)
所以对应的,如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie
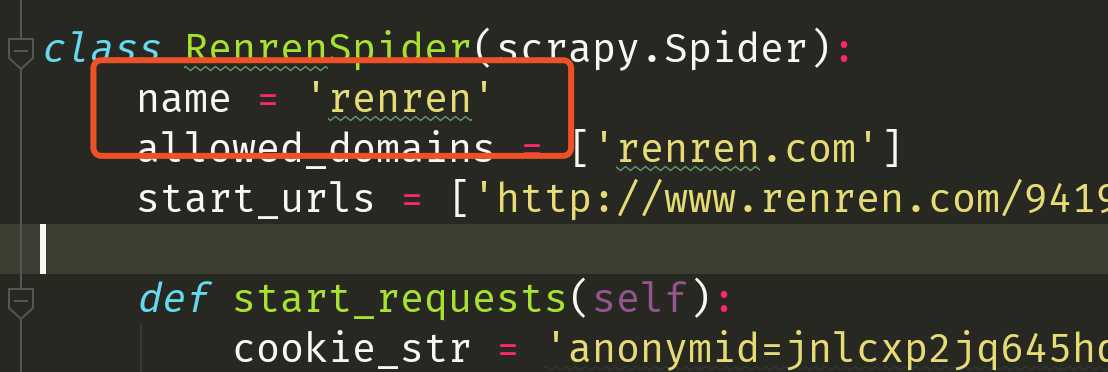
3. 实现携带cookie登录人人网,例如:
注意:scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookie
import scrapy import re class RenrenSpider(scrapy.Spider): name = ‘renren‘ allowed_domains = [‘renren.com‘] start_urls = [‘http://www.renren.com/941954027/profile‘] def start_requests(self): cookie_str = "cookie_str" cookie_dict = {i.split("=")[0]:i.split("=")[1] for i in cookie_str.split("; ")} yield scrapy.Request( self.start_urls[0], callback=self.parse, cookies=cookie_dict, # headers={"Cookie":cookie_str} ) def parse(self, response): ret = re.findall("新用户287",response.text) print(ret) yield scrapy.Request( "http://www.renren.com/941954027/profile?v=info_timeline", callback=self.parse_detail ) def parse_detail(self,response): ret = re.findall("新用户287",response.text) print(ret)
4. 在settings中开启cookie_debug
在settings.py中通过设置COOKIES_DEBUG=TRUE 能够在终端看到cookie的传递传递过程

scrapy中发送post请求的方法 通过scrapy.FormRequest能够发送post请求,同时需要添加fromdata参数作为请求体,以及callback
使用scrapy模拟登陆github
思路分析
找到post的url地址
点击登录按钮进行抓包,然后定位url地址为https://github.com/session
找到请求体的规律
分析post请求的请求体,其中包含的参数均在前一次的响应中
验证是否登录成功
通过请求个人主页,观察是否包含用户名
#spider/github.py # -*- coding: utf-8 -*- import scrapy import re class GithubSpider(scrapy.Spider): name = ‘github‘ allowed_domains = [‘github.com‘] start_urls = [‘https://github.com/login‘] def parse(self, response): authenticity_token = response.xpath("//input[@name=‘authenticity_token‘]/@value").extract_first() utf8 = response.xpath("//input[@name=‘utf8‘]/@value").extract_first() commit = response.xpath("//input[@name=‘commit‘]/@value").extract_first() yield scrapy.FormRequest( "https://github.com/session", formdata={ "authenticity_token":authenticity_token, "utf8":utf8, "commit":commit, "login":"noobpythoner", "password":"***" }, callback=self.parse_login ) def parse_login(self,response): ret = re.findall("noobpythoner",response.text,re.I) print(ret)
标签:爬取 roc esc 对象 random python3 请求头 范围 future
原文地址:https://www.cnblogs.com/caijunchao/p/13118299.html