标签:TBase 集成 理论 图结构 探讨 背景 云上 部分 pass
3D目标检测(CVPR2020:Lidar)
LiDAR-Based Online 3D Video Object Detection With Graph-Based Message Passing and Spatiotemporal Transformer Attention
论文地址:
源码地址:https://github.com/yinjunbo/3DVID
摘要
现有的基于LiDAR的三维目标检测大多集中在单帧检测上,而忽略了连续点云帧的时空信息。本文提出了一种基于点云序列的端到端在线三维视频目标检测方法。该模型包括空间特征编码组件和时空特征聚合组件。在前一部分中,提出了一种新的支柱消息传递网络(PMPNet)对每个离散点云帧进行编码。该方法通过迭代消息传递,自适应地从相邻节点中收集柱节点的信息,有效地扩大了柱特征的接收范围。在后一部分中,提出了一个注意的时空变换器GRU(AST-GRU)来聚合时空信息,这增强了传统的ConvGRU的注意记忆选通机制。AST-GRU包含一个空间变换器注意(STA)模块和一个时间变换器注意(TTA)模块,分别强调前景对象和对齐动态对象。实验结果表明,所提出的三维视频目标检测器在大规模nuScenes基准上达到了最先进的性能。
一.基本理论与创新点
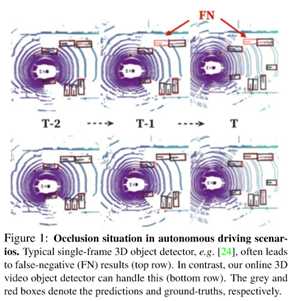
基于激光雷达的三维目标检测在自主驾驶、机器人导航和虚拟/增强现实等广泛应用中发挥着重要作用[11,46]。目前大多数3D目标检测方法(42、58、6、62、24)都遵循单帧检测模式,而在点云视频中进行检测的很少。点云视频被定义为点云帧的时间序列。例如,在nuScenes数据集[4]中,使用现代32束激光雷达传感器每秒可以捕获20个点云帧。由于点云的稀疏性,单帧检测可能会受到一些限制。特别是,遮挡、长距离和非均匀采样不可避免地发生在某一帧上,其中单帧目标检测器无法处理这些情况,从而导致性能恶化,如图1所示。然而,点云视频包含了丰富的前景对象时空信息,可以对其进行探索以提高检测性能。构建三维视频目标检测器的主要问题是如何对连续点云帧的时空特征表示进行建模。本文提出将基于图形的空间特征编码组件与注意感知的时空特征聚合组件相结合,实现连续点云帧的视频相干捕获,从而为基于激光雷达的三维视频目标检测提供端到端的在线解决方案。
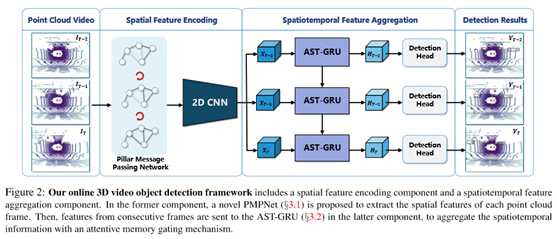
流行的单帧三维目标检测器往往首先将点云离散为体素或柱状网格[62、56、24],然后使用卷积神经网络(CNN)堆栈提取点云特征。这种方法结合了现有二维或三维cnn的成功,通常比基于点的方法获得更好的计算效率[42,37]。因此,在空间特征编码组件中,也遵循这个范例为每个输入帧提取特征。然而,这些方法的一个潜在问题在于,只关注局部聚集的特征,即使用点网[39]为单独的体素或柱体提取特征,如[62]和[24]。为了进一步扩大接受域,必须重复应用跨步或池操作,这将导致空间信息的丢失。为了解决这一问题,提出了一种新的基于图的网络,称为支柱消息传递网络(PMPNet),将非空支柱视为图节点,并通过聚合来自其邻居的消息来自适应地扩大节点的接收域。PMPNet通过对k-NN图的迭代推理,可以挖掘离散点云框架中不同柱网之间丰富的几何关系。这有效地鼓励了一个框架内不同空间区域之间的信息交换。
在获得每个输入帧的空间特征后,将这些特征集合到时空特征聚合组件中。由于ConvGRU[1]在2D视频理解领域显示出了很好的性能,建议使用一个专注的时空转换器GRU(AST-GRU),通过使用专注的内存选通机制捕获连续点云帧的依赖关系,将ConvGRU扩展到3D领域。具体来说,在考虑基于激光雷达的自动驾驶场景中的三维视频目标检测时,存在两个潜在的限制。首先,在鸟瞰图中,大多数前景对象(如汽车和行人)占据较小的区域,背景噪声不可避免地以一个循环单元计算新的内存。因此,建议利用空间变换注意(STA)模块(一个源自[48,53]的内部注意)来抑制背景噪声,并通过用上下文信息对每个像素进行关注来强调前景对象。其次,当更新递归单元中的存储器时,两个输入(即旧存储器和新输入)的空间特征没有很好地对齐。特别是,尽管可以使用ego姿势信息精确地将静态对象跨帧对齐,但动态对象的大运动却没有对齐,这将影响新内存的质量。为了解决这一问题,提出了一个时间变换注意(TTA)模块,该模块利用时间交互注意机制自适应地捕获连续帧中的对象运动。这将更好地利用修改后的可变形卷积层[65,64]。与vanilla ConvGRU相比,AST-GRU能够更好地处理时空特征,产生更可靠的新内存。
综上所述,提出了一种新的基于激光雷达的在线三维视频目标检测器,利用了以往的长期信息来提高检测性能。在模型中,引入了一种新的PMPNet,通过基于迭代图的消息传递,自适应地扩大离散点clod帧中支柱节点的接收场。然后将输出的序列特征聚合到AST-GRU中,利用注意记忆选通机制挖掘点云视频的丰富一致性。大量的评估表明,3D视频目标检测器在大规模nuScenes基准上相对于单帧检测器取得了更好的性能。
二.相关研究
基于激光雷达的三维目标检测
现有的三维目标检测方法大致可分为三类:基于激光雷达的方法[42、58、62、24、61、56]、基于图像的方法[22、54、26、34、25]和基于多传感器融合的方法[5、29、30、21、38]。在这里,主要关注基于激光雷达的方法,因为对不同的光照和天气条件不太敏感。其中,一个类别[62、57、24]通常将点云离散为规则网格(例如体素或柱),然后利用2D或3D cnn进行特征提取。另一个类别[42,58,6]使用点网络++[39]这样的点特征抽取器直接从原始点云学习三维表示。在具有大规模点云的场景中直接应用基于点的检测器通常是不切实际的,因为往往对每个点执行特征提取。例如,nuScenes数据集[4]中的一个关键帧包含300000个点云,这些点云在0.5秒内被10个非关键帧激光雷达扫描加密。使用这样的比例在点云上操作将导致非平凡的计算成本和内存需求。相比之下,基于体素的方法可以解决这种困难,因为对点数不太敏感。Zhou等人[62]首先将端到端CNN应用于基于体素的3D对象检测。提出用一个体素特征编码(VFE)层来描述每个体素,并利用级联的3D和2dcnn来提取深层特征。然后利用区域建议网络(RPN)得到最终的检测结果。之后,朗等人[24]进一步扩展[62],将点云投影到鸟瞰图上,并用柱特征网络(PFN)对每个离散化网格(命名柱)进行编码。
VFE层和PFN在生成网格级表示时都只考虑单独的体素或柱体,忽略了较大空间区域的信息交换。相反,PMPNet通过基于图的消息传递从全局的角度对支柱特征进行编码,从而促进了具有非局部属性的表示。此外,这些单帧三维目标检测器只能逐帧处理点云数据,缺乏对时间信息的挖掘。尽管[33]在点云序列上应用了时态3D ConvNet,但在对时态域的特征进行降采样时遇到了特征折叠问题。而且,不能处理具有多帧标签的长期序列。AST-GRU采用一种专注的存储选通机制来捕捉长期的时间信息,这可以充分挖掘点云视频中的时空一致性。
图形神经网络
图神经网络(GNN)是由Gori等人首次提出的。[13] 为图结构数据的内在关系建模。然后斯卡塞利等人[41]扩展到不同类型的图。然后,根据不同的消息传播策略,从两个方向对GNNs进行了探讨。第一组[28、19、60、36、40]使用选通机制使信息能够在图形中传播。例如,Li等人[28]利用递归神经网络来描述每个图节点的状态。然后,Gilmer等人[12] 推广了一种将图形推理描述为参数化消息传递网络的框架。另一组[3,15,9,17,27]将卷积网络集成到图域中,称为图卷积神经网络(GCNNs),通过图卷积层的堆栈更新节点特征。由于图形的强大表达能力,GNNs在许多领域都取得了很好的结果[9,10,51,2,52]。PMPNet属于第一组,使用门控消息传递策略捕获支柱特征,用于构建每个点云框架的空间表示。
三.网络结构
PMPNet
PMPNet是一个端到端的可微模型,通过用神经网络参数化所有函数来实现。
主干模块
如文献[62]所述,利用2D骨干网进一步提取由三个完全卷积层组成的RW×H×L的特征。每个块被定义为一个元组(S,Z,C)。所有块都有Z×Z卷积核,输出通道数为C。每个块的第一层以步长S操作,而其层以步长1操作。每个块的输出特征通过上采样层调整到相同的分辨率,然后连接在一起以合并来自不同特征级别的语义信息。
AST-GRU模块
在STA模块中,公式11和公式13中的所有线性函数都是1×1卷积层。在TTA模块中,规则卷积层、可变形卷积层和ConvGRU都有3×3大小的可学习核。
四.实验测试
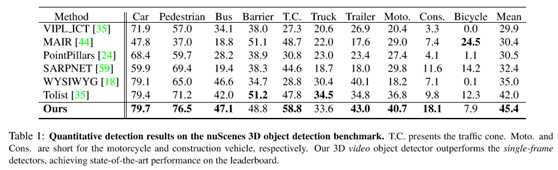
在表1中给出了算法和其最新方法在nuScenes基准上的性能比较。PointPillars[24]、SARPNET[59]、WYSIWYG[18]和Tolist[35]都是基于体素的单帧3D对象检测器。特别是,PointPillars被用作模型的基线。WYSIWYG是最近的一种算法,使用体素化的可见性贴图扩展了点柱。
三维视频目标检测器在很大程度上优于这些方法。特别是,将Ficial PointPillars算法改进了15%。请注意,nuScenes数据集中存在严重的类不平衡问题。文[63]中的方法设计了一种类数据扩充算法。进一步结合这些技术可以提高模型的性能。但是,着重于研究点云视频的时空一致性,而处理类不平衡问题并不是本文的目的。此外,在图5中进一步展示了一些定性结果。除了图1中的遮挡情况外,还提出了另一种检测距离较远的车(右上角的车)的情况,其点云特别稀疏,这对单帧检测器来说是非常具有挑战性的。再次,3D视频目标检测器利用注意力集中的时间信息有效地检测出远处的汽车。
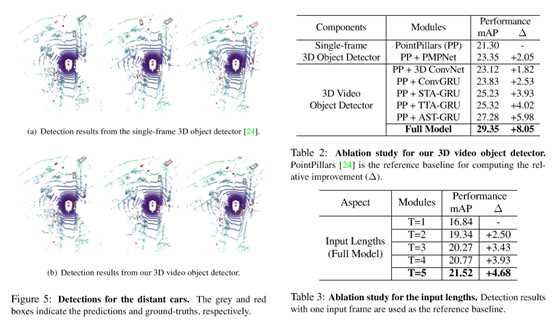
在这一部分中,将研究算法中每个模块的有效性。由于nuScenes中的训练样本是KITTI中的7倍(28130对3712),因此在整个数据集上训练多个模型是非常重要的。因此,使用一个mini训练组进行验证。包含约3500个从原始训练组均匀取样的样本。此外,在模型中,PointPillars[24]被用作基线检测器。首先,在空间特征编码组件中评估PMPNet,用PMPNet替换PointPillars中的PFN。如表2所示,将基线提高了2.05%。其次,通过将时空特征聚合组件(ConvGRU、STA-GRU和TTA-GRU)中的各个模块添加到点柱中,验证了的能力。
可以看到,所有这些模块都比单帧检测器取得了更好的性能。此外,还将AST-GRU与其视频目标检测器进行了比较。由于nuScenes中的每个关键帧都包含由前10个非关键帧扫描合并的点云,因此在合并的关键帧上训练的点柱基线可以被视为最简单的视频对象检测器。AST-GRU提高了5.98%。然后,通过实现文[33]中的后期特征融合模块,将ASTGRU与基于时态3D ConvNet的方法进行了比较。临时3D ConvNet在训练过程中只能访问一个关键帧标签(0.5s),聚集更多的标签反而会降低性能。从表2可以看出,基于3D ConvNetbased的方法比PointPillars基线高出1.82%。
相比之下,AST-GRU进一步优于4.16%,这说明了长期时间信息的重要性。最后,采用PMPNet的全模型取得了最佳的性能。最后,分析了输入序列长度的影响。由于每个关键帧都包含大量会增加内存需求的点云,因此在进行此实验时不使用非关键帧扫描中的点云。不同输入长度的实验结果如表3所示。实验结果表明,利用已有的长期时间信息(2.5s)可以获得更好的三维目标检测性能。
标签:TBase 集成 理论 图结构 探讨 背景 云上 部分 pass
原文地址:https://www.cnblogs.com/wujianming-110117/p/13123610.html