标签:nta red contains modules comm start text contain **kwargs
Scrapy是一个常用的爬虫框架,可以提升爬虫的效率,从而更好的实现爬虫。Scrapy是一个为了抓取网页数据、提取结构性数据而编写的应用框架,该框架是封装的,包含request(异步调度和处理)、下载器(多线程的Downloader)、解析器(selector)和twisted(异步处理)等。
第一步:
安装Scrapy框架:
pip install scrapy
第二步:
创建一个Scarpy爬虫项目:
以stockstar为例:
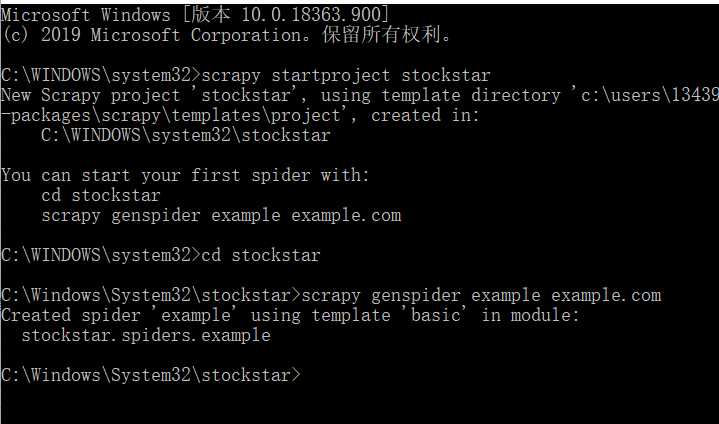
在cmd中输入:
scrapy startproject stockstar
然后按照提示输入:
You can start your first spider with:
cd stockstar
scrapy genspider example example.com
然后在相应的位置找到文件,例如在 C:\WINDOWS\system32\stockstar中
第三步:
定义一个item容器,item容器是存储爬取数据的容器,其使用方法与Python字典类似。它提供额外的保护机制以避免拼写错误导致的未定义字段错误。
首先需要对所要抓取的网页数据进行分析,定义所爬取记录的数据结构。相应的items.py程序如下所示:(爬取股票代码和股票简称)
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
class StockstarItemLoader(ItemLoader):
#自定义itemloader
default_output_processor = TakeFirst()
class StockstarItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field() # 股票代码
abbr = scrapy.Field() # 股票简称
第四步:
定义settings文件进行基本爬虫设置,在相应的settings.py文件中定义可显示中文的JSON Lines Exporter,并设置爬取间隔为0.25s。
# -*- coding: utf-8 -*-
# Scrapy settings for stockstar project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
from scrapy.exporters import JsonLinesItemExporter
# 默认显示的中文是阅读性较差的Unicode字符
# 需要定义子类显示出原来的字符集(将父类的ensure_ascii属性设置为False即可)
class CustomJsonLinesItemExporter(JsonLinesItemExporter):
def __init__(self, file, **kwargs):
super(CustomJsonLinesItemExporter, self).__init__(file, ensure_ascii=False, **kwargs)
# 启用新定义的Exporter类
FEED_EXPORTERS = {
‘json‘: ‘stockstar.settings.CustomJsonLinesItemExporter‘,
}
BOT_NAME = ‘stockstar‘
SPIDER_MODULES = [‘stockstar.spiders‘]
NEWSPIDER_MODULE = ‘stockstar.spiders‘
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = ‘stockstar (+http://www.yourdomain.com)‘
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.25
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,
# ‘Accept-Language‘: ‘en‘,
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# ‘stockstar.middlewares.StockstarSpiderMiddleware‘: 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# ‘stockstar.middlewares.MyCustomDownloaderMiddleware‘: 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# ‘scrapy.extensions.telnet.TelnetConsole‘: None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# ITEM_PIPELINES = {
# ‘stockstar.pipelines.StockstarPipeline‘: 300,
# }
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = ‘httpcache‘
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘
第五步:
编写爬虫逻辑。在spiders/stock.py文件下,定义爬虫逻辑。
# -*- coding: utf-8 -*-
import scrapy
from items import StockstarItem, StockstarItemLoader
class StockSpider(scrapy.Spider):
name = ‘stock‘
allowed_domains = [‘quote.stockstar.com‘]
start_urls = [‘http://quote.stockstar.com/stock/ranklist_a_3_1_1.html‘]
def parse(self, response):
page = int(response.url.split("_")[-1].split(".")[0])
item_nodes = response.css(‘#datalist tr‘)
for item_node in item_nodes:
item_loader = StockstarItemLoader(item=StockstarItem(), selector=item_node)
item_loader.add_css("code", "td:nth-child(1) a::text")
item_loader.add_css("abbr", "td:nth-child(2) a::text")
yield stock_item
if item_nodes:
next_page = page + 1
next_url = response.url.replace("{0}.html".format(page), "{0}.html".format(next_page))
yield scrapy.Request(url=next_url, callback=self.parse)
第六步:
代码调试,在stockstar文件下新建一个main.py
from scrapy.cmdline import execute execute(["scrapy", "crawl", "stock", "-o", "items.json"])
运行main.py可以得知,如下结果:

数据爬取成果,并且保存到一个.json文件中。
标签:nta red contains modules comm start text contain **kwargs
原文地址:https://www.cnblogs.com/zhuozige/p/13126341.html