标签:lamp add str tor mamicode line 之间 optimizer ack
1.深度学习框架

pytorch与其他框架的比较

pytorch的学习方法:
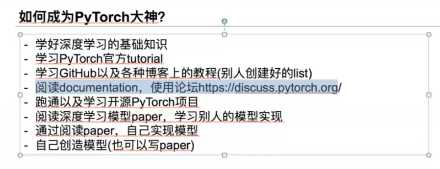
课程安排:

PyTorch是一个基于Python的科学计算库,它有以下特点:
2.tensor的运算
Tensor类似与NumPy的ndarray,唯一的区别是Tensor可以在GPU上加速运算。
(1)加法
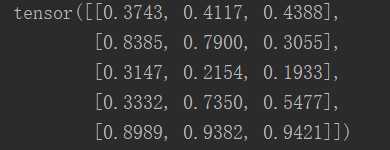
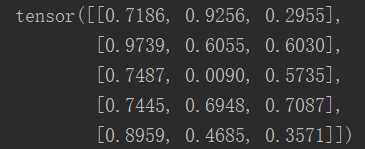
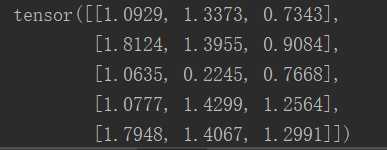
x = torch.rand(5,3) y = torch.rand(5,3) z=x+y print(x) print(y) print(z)
效果图:
(2)Torch Tensor和NumPy array会共享内存,所以改变其中一项也会改变另一项。
把Torch Tensor转变成NumPy Array
# Torch Tensor和NumPy array会共享内存,所以改变其中一项也会改变另一项。 # 把Torch Tensor转变成NumPy Array a = torch.ones(5) b = a.numpy() print(a) print(b) b[1] = 2 print(a)
效果图:
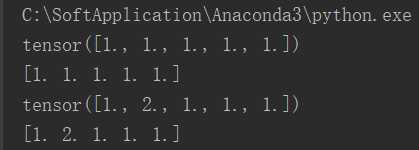
(3)在Torch Tensor和NumPy array之间相互转化非常容易。
# 把NumPy ndarray转成Torch Tensor a = np.ones(5) b = torch.from_numpy(a) np.add(a, 1, out=a) print(a) print(b)
效果图:
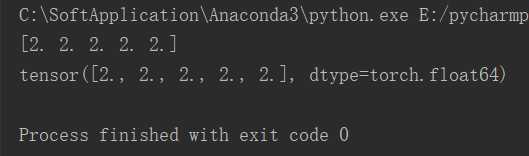
3.利用Pytorch的nn库来构建神经网络
这次我们使用PyTorch中nn这个库来构建网络。 用PyTorch autograd来构建计算图和计算gradients, 然后PyTorch会帮我们自动计算gradient。
import torch.nn as nn import torch N, D_in, H, D_out = 64, 1000, 100, 10 # 随机创建一些训练数据 x = torch.randn(N, D_in) y = torch.randn(N, D_out) model = torch.nn.Sequential( torch.nn.Linear(D_in, H, bias=False), # w_1 * x + b_1 torch.nn.ReLU(), torch.nn.Linear(H, D_out, bias=False), ) torch.nn.init.normal_(model[0].weight) torch.nn.init.normal_(model[2].weight) # model = model.cuda() loss_fn = nn.MSELoss(reduction=‘sum‘) learning_rate = 1e-6 for it in range(500): # Forward pass y_pred = model(x) # model.forward() # compute loss loss = loss_fn(y_pred, y) # computation graph print(it, loss.item()) # Backward pass loss.backward() # update weights of w1 and w2 with torch.no_grad(): for param in model.parameters(): # param (tensor, grad) param -= learning_rate * param.grad model.zero_grad()
效果图:
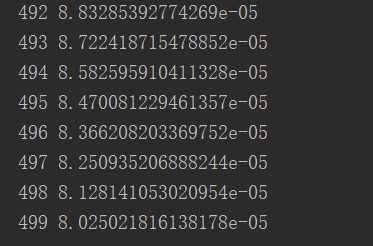
4.自定义nn modules
我们可以定义一个模型,这个模型继承自nn.Module类。如果需要定义一个比Sequential模型更加复杂的模型,就需要定义nn.Module模型。
import torch.nn as nn import torch N, D_in, H, D_out = 64, 1000, 100, 10 # 随机创建一些训练数据 x = torch.randn(N, D_in) y = torch.randn(N, D_out) # 自定义模型,定义一个类继承torch.nn.Module class TwoLayerNet(torch.nn.Module): def __init__(self, D_in, H, D_out): super(TwoLayerNet, self).__init__() # define the model architecture self.linear1 = torch.nn.Linear(D_in, H, bias=False) self.linear2 = torch.nn.Linear(H, D_out, bias=False) def forward(self, x): y_pred = self.linear2(self.linear1(x).clamp(min=0)) return y_pred model = TwoLayerNet(D_in, H, D_out) # 定义损失函数 loss_fn = nn.MSELoss(reduction=‘sum‘) learning_rate = 1e-4 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) for it in range(500): # Forward pass y_pred = model(x) # model.forward() # compute loss loss = loss_fn(y_pred, y) # computation graph print(it, loss.item()) optimizer.zero_grad() # Backward pass loss.backward() # update model parameters optimizer.step()
标签:lamp add str tor mamicode line 之间 optimizer ack
原文地址:https://www.cnblogs.com/luckyplj/p/13131838.html