标签:line 客户 巴黎 out 临时 一个 disco app more
未来一段时间开发的项目或者需求会大量使用到Redis,趁着这段时间业务并不太繁忙,抽点时间预习和复习Redis的相关内容。刚好看到博客下面的UV和PV统计,想到了最近看书里面提到的HyperLogLog数据类型,于是花点时间分析一下它的使用方式和使用场景(暂时不探究HyperLogLog的实现原理)。Redis中HyperLogLog数据类型是Redid 2.8.9引入的,使用的时候确保Redis版本>= 2.8.9。
基数计数(cardinality counting),通常用来统计一个集合中不重复的元素个数。一个很常见的例子就是统计某个文章的UV(Unique Visitor,独立访客,一般可以理解为客户端IP)。大数据量背景下,要实现基数计数,多数情况下不会选择存储全量的基数集合的元素,因为可以计算出存储的内存成本,假设一个每个被统计的元素的平均大小为32bit,那么如果统计一亿个数据,占用的内存大小为:
32 * 100000000 / 8 / 1024 / 1024 ≈ 381M。如果有多个集合,并且允许计算多个集合的合并计数结果,那么这个操作带来的复杂度可能是毁灭性的。因此,不会使用Bitmap、Tree或者HashSet等数据结构直接存储计数元素集合的方式进行计数,而是在不追求绝对准确计数结果的前提之下,使用基数计数的概率算法进行计数,目前常见的有概率算法以下三种:
Linear Counting(LC)。LogLog Counting(LLC)。HyperLogLog Counting(HLL)。所以,HyperLogLog其实是一种基数计数概率算法,并不是Redis特有的,Redis基于C语言实现了HyperLogLog并且提供了相关命令API入口。
Redis的作者Antirez为了纪念Philippe Flajolet对组合数学和基数计算算法分析的研究,所以在设计HyperLogLog命令的时候使用了Philippe Flajolet姓名的英文首字母PF作为前缀。也就是说,Philippe Flajolet博士是HLL算法的重大贡献者,但是他其实并不是Redis中HyperLogLog数据类型的开发者。遗憾的是Philippe Flajolet博士于2011年3月22日因病在巴黎辞世。这个是Philippe Flajolet博士的维基百科照片:

Redis提供的HyperLogLog数据类型的特征:
HyperLogLog Counting(HLL)实现,只做基数计算,不会保存元数据。HyperLogLog每个KEY最多占用12K的内存空间,可以计算接近2^64个不同元素的基数,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数基数个数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,转变成稠密矩阵之后才会占用12K的内存空间。Standard Error)为0.81%的近似值,当数据量不大的时候,得到的结果也可能是一个准确值。内存占用小(每个KEY最高占用12K)是HyperLogLog的最大优势,而它存在两个相对明显的限制:
Redis提供的HyperLogLog数据类型一共有三个命令API:PFADD、PFCOUNT和PFMERGE。
PFADD命令参数如下:
PFADD key element [element …]
支持此命令的Redis版本是:>= 2.8.9
时间复杂度:每添加一个元素的复杂度为O(1)
element添加到键为key的HyperLogLog数据结构中。PFADD命令的执行流程如下:
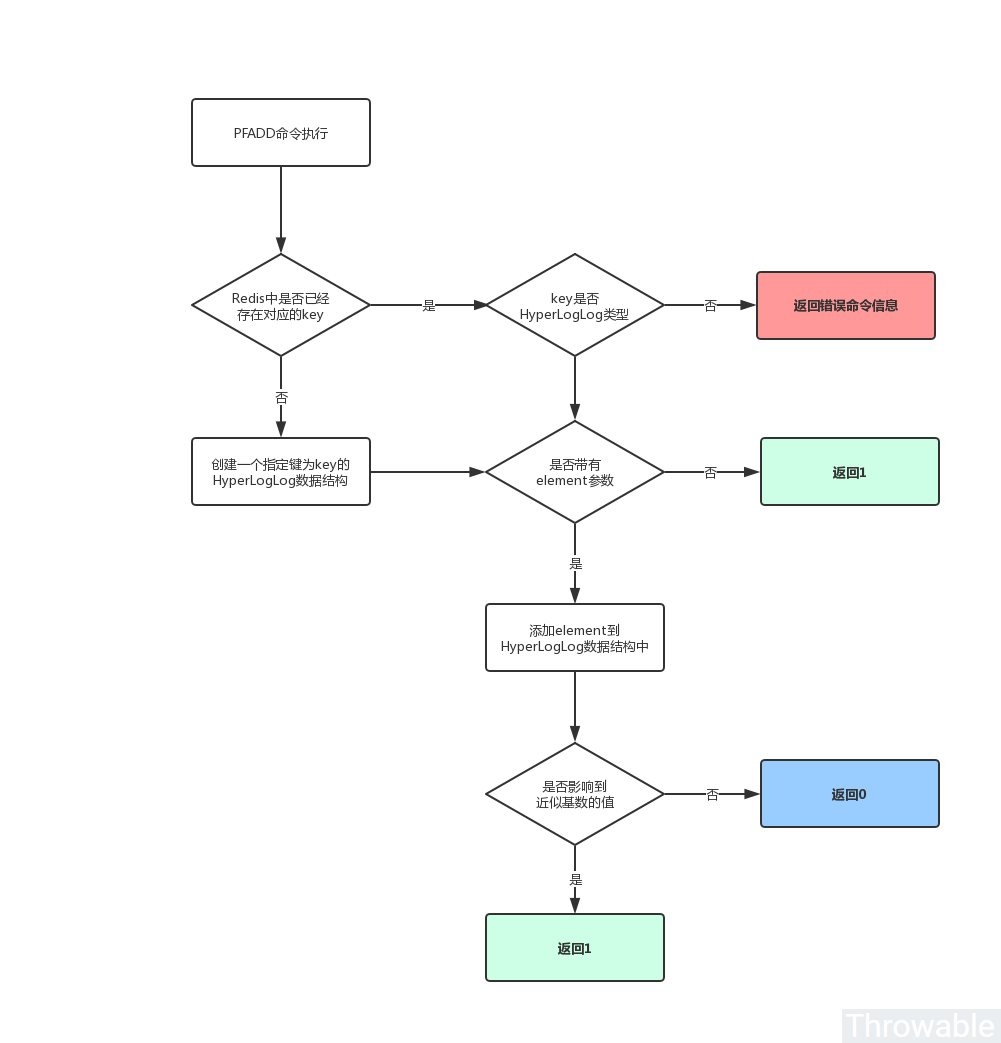
PFADD命令的使用方式如下:
127.0.0.1:6379> PFADD food apple fish
(integer) 1
127.0.0.1:6379> PFADD food apple
(integer) 0
127.0.0.1:6379> PFADD throwable
(integer) 1
127.0.0.1:6379> SET name doge
OK
127.0.0.1:6379> PFADD name throwable
(error) WRONGTYPE Key is not a valid HyperLogLog string value.
虽然HyperLogLog数据结构本质是一个字符串,但是不能在String类型的KEY使用HyperLogLog的相关命令。
PFCOUNT命令参数如下:
PFCOUNT key [key …]
支持此命令的Redis版本是:>= 2.8.9
时间复杂度:返回单个HyperLogLog的基数计数值的复杂度为O(1),平均常数时间比较低。当参数为多个key的时候,复杂度为O(N),N为key的个数。
PFCOUNT命令使用单个key的时候,返回储存在给定键的HyperLogLog数据结构的近似基数,如果键不存在, 则返回0。PFCOUNT命令使用多个key的时候,返回储存在给定的所有HyperLogLog数据结构的并集的近似基数,也就是会把所有的HyperLogLog数据结构合并到一个临时的HyperLogLog数据结构,然后计算出近似基数。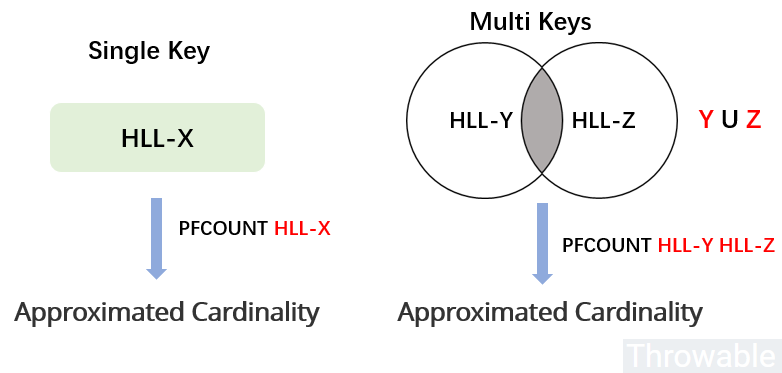
PFCOUNT命令的使用方式如下:
127.0.0.1:6379> PFADD POST:1 ip-1 ip-2
(integer) 1
127.0.0.1:6379> PFADD POST:2 ip-2 ip-3 ip-4
(integer) 1
127.0.0.1:6379> PFCOUNT POST:1
(integer) 2
127.0.0.1:6379> PFCOUNT POST:1 POST:2
(integer) 4
127.0.0.1:6379> PFCOUNT NOT_EXIST_KEY
(integer) 0
PFMERGE命令参数如下:
PFMERGE destkey sourcekey [sourcekey ...]
支持此命令的Redis版本是:>= 2.8.9
时间复杂度:O(N),其中N为被合并的HyperLogLog数据结构的数量,此命令的常数时间比较高
HyperLogLog数据结构合并为一个新的键为destkey的HyperLogLog数据结构,合并后的HyperLogLog的基数接近于所有输入HyperLogLog的可见集合(Observed Set)的并集的基数。OK。PFMERGE命令的使用方式如下
127.0.0.1:6379> PFADD POST:1 ip-1 ip-2
(integer) 1
127.0.0.1:6379> PFADD POST:2 ip-2 ip-3 ip-4
(integer) 1
127.0.0.1:6379> PFMERGE POST:1-2 POST:1 POST:2
OK
127.0.0.1:6379> PFCOUNT POST:1-2
(integer) 4
假设现在有个简单的场景,就是统计博客文章的UV,要求UV的计数不需要准确,也不需要保存客户端的IP数据。下面就这个场景,使用HyperLogLog做一个简单的方案和编码实施。
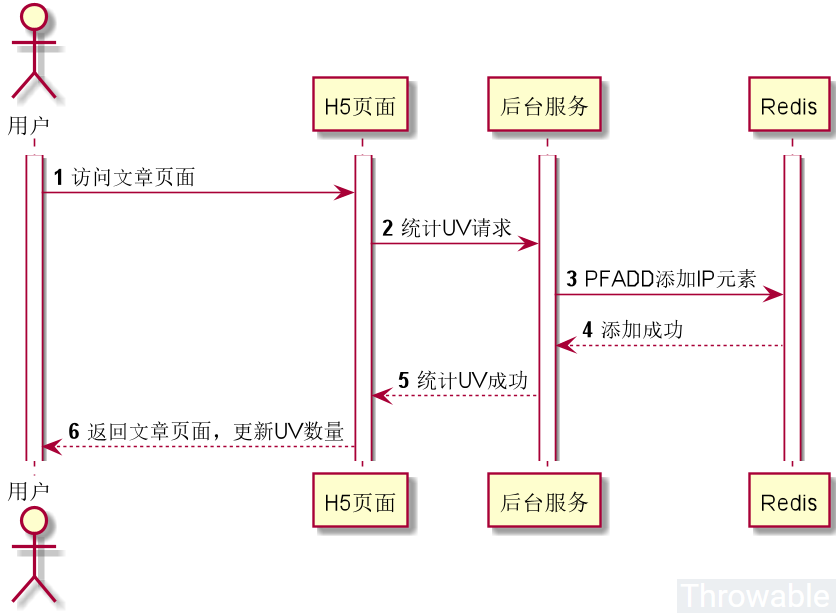
这个流程可能步骤的先后顺序可能会有所调整,但是要做的操作是基本不变的。先简单假设,文章的内容和统计数据都是后台服务返回的,两个接口是分开设计。引入Redis的高级客户端Lettuce依赖:
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>5.2.1.RELEASE</version>
</dependency>
编码如下:
public class UvTest {
private static RedisCommands<String, String> COMMANDS;
@BeforeClass
public static void beforeClass() throws Exception {
// 初始化Redis客户端
RedisURI uri = RedisURI.builder().withHost("localhost").withPort(6379).build();
RedisClient redisClient = RedisClient.create(uri);
StatefulRedisConnection<String, String> connect = redisClient.connect();
COMMANDS = connect.sync();
}
@Data
public static class PostDetail {
private Long id;
private String content;
}
private PostDetail selectPostDetail(Long id) {
PostDetail detail = new PostDetail();
detail.setContent("content");
detail.setId(id);
return detail;
}
private PostDetail getPostDetail(String clientIp, Long postId) {
PostDetail detail = selectPostDetail(postId);
String key = "puv:" + postId;
COMMANDS.pfadd(key, clientIp);
return detail;
}
private Long getPostUv(Long postId) {
String key = "puv:" + postId;
return COMMANDS.pfcount(key);
}
@Test
public void testViewPost() throws Exception {
Long postId = 1L;
getPostDetail("111.111.111.111", postId);
getPostDetail("111.111.111.222", postId);
getPostDetail("111.111.111.333", postId);
getPostDetail("111.111.111.444", postId);
System.out.println(String.format("The uv count of post [%d] is %d", postId, getPostUv(postId)));
}
}
输出结果:
The uv count of post [1] is 4
可以适当使用更多数量的不同客户端IP调用getPostDetail(),然后统计一下误差。
如果想要准确统计UV,则需要注意几个点:
假设在不考虑内存成本的前提下,我们依然可以使用Redis做准确和实时的UV统计,简单就可以使用Set数据类型,增加UV只需要使用SADD命令,统计UV只需要使用SCARD命令(时间复杂度为O(1),可以放心使用)。举例:
127.0.0.1:6379> SADD puv:1 ip-1 ip-2
(integer) 2
127.0.0.1:6379> SADD puv:1 ip-3 ip-4
(integer) 2
127.0.0.1:6379> SCARD puv:1
(integer) 4
如果这些统计数据仅仅是用户端展示,那么可以采用异步设计:

在体量小的时候,上面的所有应用的功能可以在同一个服务中完成,消息队列可以用线程池的异步方案替代。
这篇文章只是简单介绍了HyperLogLog的使用和统计UV的使用场景。总的来说就是:在(1)原始数据量巨大,(2)内存占用要求尽可能小,(3)允许计数存在一定误差并且(4)不要求存放元数据的场景下,可以优先考虑使用HyperLogLog进行计数。
参考资料:
(本文完 c-3-d e-a-20191117)
标签:line 客户 巴黎 out 临时 一个 disco app more
原文地址:https://www.cnblogs.com/throwable/p/13138554.html