标签:template pen sqlite数据库 loading roc 读取 key memcach 两种
# 1.需求分析
架构师+产品经理+开发者组长
在跟客户谈需求之前,会大致先了解客户的需求,然后自己先设计一套比较好写方案
在跟客户沟通交流中引导客户往我们之前想好的方案上面靠
形成一个初步的方案
# 2.项目设计
架构师干的活
编程语言选择
框架选择
数据库选择
主库:MySQL,postgreSQL,...
缓存数据库:redis、mongodb、memcache...
功能划分
将整个项目划分成几个功能模块
找组长开会
给每个组分发任务
项目报价
技术这块需要多少人,多少天(一个程序员一天1500~2000计算(大致))
产品经理公司层面 再加点钱
公司财务签字确认
公司老板签字确认
产品经理去跟客户沟通
后续需要加功能 继续加钱
# 3.分组开发
组长找组员开会,安排各自功能模块
我们其实就是在架构师设计好的框架里面填写代码而已(码畜)
我们在写代码的时候 写完需要自己先测试是否有bug
如果是一些显而易见的bug,你没有避免而是直接交给了测试部门测出来
那你可能就需要被扣绩效了(一定要跟测试小姐姐搞好关系)
薪资组成 15K(合理合规合法的避税)
底薪 10K
绩效 3K
岗位津贴 1K
生活补贴 1K
# 4.测试
测试部门测试你的代码
压力测试
...
# 5.交付上线
1.交给对方的运维人员
2.直接上线到我们的服务器上 收取维护费用
3.其他...
"""
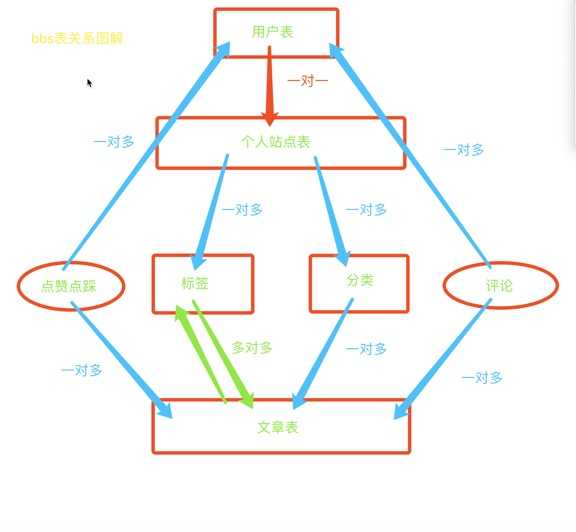
一个项目中最最最重要的不是业务逻辑的书写
而是前期的表设计,只要将表设计好了,后续的功能书写才会一帆风顺
bbs表设计
1.用户表
继承AbstractUser
扩展
phone 电话号码
avatar 用户头像
pip install Pillow
前端动态改变展示:
给图片设置change事件
文本阅读器对象(FileReader()、readAsDataURL(file_obj))
修改图片src属性
create_time 创建时间
外键字段
一对一个人站点表
2.个人站点表
site_name 站点名称
site_title 站点标题
site_theme 站点样式
3.文章标签表
name 标签名
外键字段
一对多个人站点
4.文章分类表
name 分类名
外键字段
一对多个人站点
5.文章表
title 文章标题
desc 文章简介
content 文章内容
create_time 发布时间
数据库字段设计优化(******)
(虽然下述的三个字段可以从其他表里面跨表查询计算得出,但是频繁跨表效率)
up_num 点赞数
down_num 点踩数
comment_num 评论数
外键字段
一对多个人站点
多对多文章标签
一对多文章分类
6.点赞点踩表
记录哪个用户给哪篇文章点了赞还是点了踩
user ForeignKey(to="User")
article ForeignKey(to="Article")
is_up BooleanField()
1 1 1
1 2 1
1 3 0
2 1 1
7.文章评论表
记录哪个用户给哪篇文章写了哪些评论内容
user ForeignKey(to="User")
article ForeignKey(to="Article")
content CharField()
comment_time DateField()
# 自关联
parent ForeignKey(to="Comment",null=True)
# ORM专门提供的自关联写法
parent ForeignKey(to="self",null=True)
id user_id article_id parent_id
1 1 1
2 2 1 1
根评论子评论的概念
根评论就是直接评论当前发布的内容的
子评论是评论别人的评论
1.PHP是世界上最牛逼的语言
1.1 python才是最牛逼的
1.2 java才是
根评论与子评论是一对多的关系
"""
"""
由于django自带的sqlite数据库对日期不敏感,所以我们换成MySQL
"""
from django.db import models
# Create your models here.
"""
先写普通字段
之后再写外键字段
"""
from django.contrib.auth.models import AbstractUser
class UserInfo(AbstractUser):
phone = models.BigIntegerField(verbose_name=‘手机号‘,null=True)
# 头像
avatar = models.FileField(upload_to=‘avatar/‘,default=‘avatar/default.png‘,verbose_name=‘用户头像‘)
"""
给avatar字段传文件对象 该文件会自动存储到avatar文件下 然后avatar字段只保存文件路径avatar/default.png
"""
create_time = models.DateField(auto_now_add=True)
blog = models.OneToOneField(to=‘Blog‘,null=True)
class Blog(models.Model):
site_name = models.CharField(verbose_name=‘站点名称‘,max_length=32)
site_title = models.CharField(verbose_name=‘站点标题‘,max_length=32)
# 简单模拟 带你认识样式内部原理的操作
site_theme = models.CharField(verbose_name=‘站点样式‘,max_length=64) # 存css/js的文件路径
class Category(models.Model):
name = models.CharField(verbose_name=‘文章分类‘,max_length=32)
blog = models.ForeignKey(to=‘Blog‘,null=True)
class Tag(models.Model):
name = models.CharField(verbose_name=‘文章标签‘,max_length=32)
blog = models.ForeignKey(to=‘Blog‘, null=True)
class Article(models.Model):
title = models.CharField(verbose_name=‘文章标题‘,max_length=64)
desc = models.CharField(verbose_name=‘文章简介‘,max_length=255)
# 文章内容有很多 一般情况下都是使用TextField
content = models.TextField(verbose_name=‘文章内容‘)
create_time = models.DateField(auto_now_add=True)
# 数据库字段设计优化
up_num = models.BigIntegerField(verbose_name=‘点赞数‘,default=0)
down_num = models.BigIntegerField(verbose_name=‘点踩数‘,default=0)
comment_num = models.BigIntegerField(verbose_name=‘评论数‘,default=0)
# 外键字段
blog = models.ForeignKey(to=‘Blog‘, null=True)
category = models.ForeignKey(to=‘Category‘,null=True)
tags = models.ManyToManyField(to=‘Tag‘,
through=‘Article2Tag‘,
through_fields=(‘article‘,‘tag‘)
)
class Article2Tag(models.Model):
article = models.ForeignKey(to=‘Article‘)
tag = models.ForeignKey(to=‘Tag‘)
class UpAndDown(models.Model):
user = models.ForeignKey(to=‘UserInfo‘)
article = models.ForeignKey(to=‘Article‘)
is_up = models.BooleanField() # 传布尔值 存0/1
class Comment(models.Model):
user = models.ForeignKey(to=‘UserInfo‘)
article = models.ForeignKey(to=‘Article‘)
content = models.CharField(verbose_name=‘评论内容‘,max_length=255)
comment_time = models.DateTimeField(verbose_name=‘评论时间‘,auto_now_add=True)
# 自关联
parent = models.ForeignKey(to=‘self‘,null=True) # 有些评论就是根评论
"""
我们之前是直接在views.py中书写的forms组件代码
但是为了接耦合 应该将所有的forms组件代码单独写到一个地方
如果你的项目至始至终只用到一个forms组件那么你可以直接建一个py文件书写即可
myforms.py
但是如果你的项目需要使用多个forms组件,那么你可以创建一个文件夹在文件夹内根据
forms组件功能的不同创建不同的py文件
myforms文件夹
regform.py
loginform.py
userform.py
orderform.py
...
"""
def register(request):
form_obj = MyRegForm()
if request.method == ‘POST‘:
back_dic = {"code": 1000, ‘msg‘: ‘‘}
# 校验数据是否合法
form_obj = MyRegForm(request.POST)
# 判断数据是否合法
if form_obj.is_valid():
# print(form_obj.cleaned_data) # {‘username‘: ‘jason‘, ‘password‘: ‘123‘, ‘confirm_password‘: ‘123‘, ‘email‘: ‘123@qq.com‘}
clean_data = form_obj.cleaned_data # 将校验通过的数据字典赋值给一个变量
# 将字典里面的confirm_password键值对删除
clean_data.pop(‘confirm_password‘) # {‘username‘: ‘jason‘, ‘password‘: ‘123‘, ‘email‘: ‘123@qq.com‘}
# 用户头像
file_obj = request.FILES.get(‘avatar‘)
"""针对用户头像一定要判断是否传值 不能直接添加到字典里面去"""
if file_obj:
clean_data[‘avatar‘] = file_obj
# 直接操作数据库保存数据
models.UserInfo.objects.create_user(**clean_data)
back_dic[‘url‘] = ‘/login/‘
else:
back_dic[‘code‘] = 2000
back_dic[‘msg‘] = form_obj.errors
return JsonResponse(back_dic)
return render(request,‘register.html‘,locals())
<script>
$("#myfile").change(function () {
// 文件阅读器对象
// 1 先生成一个文件阅读器对象
let myFileReaderObj = new FileReader();
// 2 获取用户上传的头像文件
let fileObj = $(this)[0].files[0];
// 3 将文件对象交给阅读器对象读取
myFileReaderObj.readAsDataURL(fileObj) // 异步操作 IO操作
// 4 利用文件阅读器将文件展示到前端页面 修改src属性
// 等待文件阅读器加载完毕之后再执行
myFileReaderObj.onload = function(){
$(‘#myimg‘).attr(‘src‘,myFileReaderObj.result)
}
})
$(‘#id_commit‘).click(function () {
// 发送ajax请求 我们发送的数据中即包含普通的键值也包含文件
let formDataObj = new FormData();
// 1.添加普通的键值对
{#console.log($(‘#myform‘).serializeArray()) // [{},{},{},{},{}] 只包含普通键值对#}
$.each($(‘#myform‘).serializeArray(),function (index,obj) {
{#console.log(index,obj)#} // obj = {}
formDataObj.append(obj.name,obj.value)
});
// 2.添加文件数据
formDataObj.append(‘avatar‘,$(‘#myfile‘)[0].files[0]);
// 3.发送ajax请求
$.ajax({
url:"",
type:‘post‘,
data:formDataObj,
// 需要指定两个关键性的参数
contentType:false,
processData:false,
success:function (args) {
if (args.code==1000){
// 跳转到登陆页面
window.location.href = args.url
}else{
// 如何将对应的错误提示展示到对应的input框下面
// forms组件渲染的标签的id值都是 id_字段名
$.each(args.msg,function (index,obj) {
{#console.log(index,obj) // username ["用户名不能为空"]#}
let targetId = ‘#id_‘ + index;
$(targetId).next().text(obj[0]).parent().addClass(‘has-error‘)
})
}
}
})
})
// 给所有的input框绑定获取焦点事件
$(‘input‘).focus(function () {
// 将input下面的span标签和input外面的div标签修改内容及属性
$(this).next().text(‘‘).parent().removeClass(‘has-error‘)
})
</script>
# 扩展
"""
一般情况下我们在存储用户文件的时候为了避免文件名冲突的情况
会自己给文件名加一个前缀
uuid
随机字符串
...
"""
"""
img标签的src属性
1.图片路径
2.url
3.图片的二进制数据
我们的计算机上面致所有能够输出各式各样的字体样式
内部其实对应的是一个个.ttf结尾的文件
http://www.zhaozi.cn/ai/2019/fontlist.php?ph=1&classid=32&softsq=%E5%85%8D%E8%B4%B9%E5%95%86%E7%94%A8
"""
"""
图片相关的模块
pip3 install pillow
"""
from PIL import Image,ImageDraw,ImageFont
"""
Image:生成图片
ImageDraw:能够在图片上乱涂乱画
ImageFont:控制字体样式
"""
from io import BytesIO,StringIO
"""
内存管理器模块
BytesIO:临时帮你存储数据 返回的时候数据是二进制
StringIO:临时帮你存储数据 返回的时候数据是字符串
"""
import random
def get_random():
return random.randint(0,255),random.randint(0,255),random.randint(0,255)
def get_code(request):
# 推导步骤1:直接获取后端现成的图片二进制数据发送给前端
# with open(r‘static/img/111.jpg‘,‘rb‘) as f:
# data = f.read()
# return HttpResponse(data)
# 推导步骤2:利用pillow模块动态产生图片
# img_obj = Image.new(‘RGB‘,(430,35),‘green‘)
# img_obj = Image.new(‘RGB‘,(430,35),get_random())
# # 先将图片对象保存起来
# with open(‘xxx.png‘,‘wb‘) as f:
# img_obj.save(f,‘png‘)
# # 再将图片对象读取出来
# with open(‘xxx.png‘,‘rb‘) as f:
# data = f.read()
# return HttpResponse(data)
# 推导步骤3:文件存储繁琐IO操作效率低 借助于内存管理器模块
# img_obj = Image.new(‘RGB‘, (430, 35), get_random())
# io_obj = BytesIO() # 生成一个内存管理器对象 你可以看成是文件句柄
# img_obj.save(io_obj,‘png‘)
# return HttpResponse(io_obj.getvalue()) # 从内存管理器中读取二进制的图片数据返回给前端
# 最终步骤4:写图片验证码
img_obj = Image.new(‘RGB‘, (430, 35), get_random())
img_draw = ImageDraw.Draw(img_obj) # 产生一个画笔对象
img_font = ImageFont.truetype(‘static/font/222.ttf‘,30) # 字体样式 大小
# 随机验证码 五位数的随机验证码 数字 小写字母 大写字母
code = ‘‘
for i in range(5):
random_upper = chr(random.randint(65,90))
random_lower = chr(random.randint(97,122))
random_int = str(random.randint(0,9))
# 从上面三个里面随机选择一个
tmp = random.choice([random_lower,random_upper,random_int])
# 将产生的随机字符串写入到图片上
"""
为什么一个个写而不是生成好了之后再写
因为一个个写能够控制每个字体的间隙 而生成好之后再写的话
间隙就没法控制了
"""
img_draw.text((i*60+60,-2),tmp,get_random(),img_font)
# 拼接随机字符串
code += tmp
print(code)
# 随机验证码在登陆的视图函数里面需要用到 要比对 所以要找地方存起来并且其他视图函数也能拿到
request.session[‘code‘] = code
io_obj = BytesIO()
img_obj.save(io_obj,‘png‘)
return HttpResponse(io_obj.getvalue())
<script>
$("#id_img").click(function () {
// 1 先获取标签之前的src
let oldVal = $(this).attr(‘src‘);
$(this).attr(‘src‘,oldVal += ‘?‘)
})
</script>
def login(request):
if request.method == ‘POST‘:
back_dic = {‘code‘:1000,‘msg‘:‘‘}
username = request.POST.get(‘username‘)
password = request.POST.get(‘password‘)
code = request.POST.get(‘code‘)
# 1 先校验验证码是否正确 自己决定是否忽略 统一转大写或者小写再比较
if request.session.get(‘code‘).upper() == code.upper():
# 2 校验用户名和密码是否正确
user_obj = auth.authenticate(request,username=username,password=password)
if user_obj:
# 保存用户状态
auth.login(request,user_obj)
back_dic[‘url‘] = ‘/home/‘
else:
back_dic[‘code‘] = 2000
back_dic[‘msg‘] = ‘用户名或密码错误‘
else:
back_dic[‘code‘] = 3000
back_dic[‘msg‘] = ‘验证码错误‘
return JsonResponse(back_dic)
return render(request,‘login.html‘)
# 1.动态展示用户名称
{% if request.user.is_authenticated %}
<li><a href="#">{{ request.user.username }}</a></li>
<li class="dropdown">
<a href="#" class="dropdown-toggle" data-toggle="dropdown" role="button" aria-haspopup="true" aria-expanded="false">更多操作 <span class="caret"></span></a>
<ul class="dropdown-menu">
<li><a href="#">修改密码</a></li>
<li><a href="#">修改头像</a></li>
<li><a href="#">后台管理</a></li>
<li role="separator" class="divider"></li>
<li><a href="#">退出登陆</a></li>
</ul>
</li>
{% else %}
<li><a href="{% url ‘reg‘ %}">注册</a></li>
<li><a href="{% url ‘login‘ %}">登陆</a></li>
{% endif %}
# 更多操作
"""
django给你提供了一个可视化的界面用来让你方便的对你的模型表
进行数据的增删改查操作
如果你先想要使用amdin后台管理操作模型表
你需要先注册你的模型表告诉admin你需要操作哪些表
去你的应用下的admin.py中注册你的模型表
from django.contrib import admin
from app01 import models
# Register your models here.
admin.site.register(models.UserInfo)
admin.site.register(models.Blog)
admin.site.register(models.Category)
admin.site.register(models.Tag)
admin.site.register(models.Article)
admin.site.register(models.Article2Tag)
admin.site.register(models.UpAndDown)
admin.site.register(models.Comment)
"""
# admin会给每一个注册了的模型表自动生成增删改查四条url
http://127.0.0.1:8000/admin/app01/userinfo/ 查
http://127.0.0.1:8000/admin/app01/userinfo/add/ 增
http://127.0.0.1:8000/admin/app01/userinfo/1/change/ 改
http://127.0.0.1:8000/admin/app01/userinfo/1/delete/ 删
http://127.0.0.1:8000/admin/app01/blog/ 查
http://127.0.0.1:8000/admin/app01/blog/add/ 增
http://127.0.0.1:8000/admin/app01/blog/1/change/ 改
http://127.0.0.1:8000/admin/app01/blog/1/delete/ 删
"""
关键点就在于urls.py中的第一条自带的url
前期我们需要自己手动苦逼的录入数据,自己克服一下
"""
# 1.数据绑定尤其需要注意的是用户和个人站点不要忘记绑定了
# 2.标签
# 3.标签和文章
千万不要把别人的文章绑定标签
"""
1 网址所使用的静态文件默认放在static文件夹下
2 用户上传的静态文件也应该单独放在某个文件夹下
media配置
该配置可以让用户上传的所有文件都固定存放在某一个指定的文件夹下
# 配置用户上传的文件存储位置
MEDIA_ROOT = os.path.join(BASE_DIR,‘media‘) # 文件名 随你 自己
会自动创建多级目录
如何开设后端指定文件夹资源
首先你需要自己去urls.py书写固定的代码
from django.views.static import serve
from BBS14 import settings
# 暴露后端指定文件夹资源
url(r‘^media/(?P<path>.*)‘,serve,{‘document_root‘:settings.MEDIA_ROOT})
"""
# 如何避免别的网站直接通过本网站的url访问本网站资源
# 简单的防盗
我可以做到请求来的时候先看看当前请求是从哪个网站过来的
如果是本网站那么正常访问
如果是其他网站直接拒绝
请求头里面有一个专门记录请求来自于哪个网址的参数
Referer: http://127.0.0.1:8000/xxx/
# 如何避免
1.要么修改请求头referer
2.直接写爬虫把对方网址的所有资源直接下载到我们自己的服务器上
# 全是每个用户都可以有自己的站点样式
<link rel="stylesheet" href="/media/css/{{ blog.site_theme }}/">
id content create_time month
1 111 2020-11-11 2020-11
2 222 2020-11-12 2020-11
3 333 2020-11-13 2020-11
4 444 2020-11-14 2020-11
5 555 2020-11-15 2020-11
"""
django官网提供的一个orm语法
from django.db.models.functions import TruncMonth
-官方提供
from django.db.models.functions import TruncMonth
Sales.objects
.annotate(month=TruncMonth(‘timestamp‘)) # Truncate to month and add to select list
.values(‘month‘) # Group By month
.annotate(c=Count(‘id‘)) # Select the count of the grouping
.values(‘month‘, ‘c‘) # (might be redundant, haven‘t tested) select month and count
时区问题报错
TIME_ZONE = ‘Asia/Shanghai‘
USE_TZ = True
"""
https://www.cnblogs.com/jason/tag/Python/ 标签
https://www.cnblogs.com/jason/category/850028.html 分类
https://www.cnblogs.com/jason/archive/2016/10.html 日期
https://www.cnblogs.com/jason/tag/1/ 标签
https://www.cnblogs.com/jason/category/1 分类
https://www.cnblogs.com/jason/archive/2020-11/ 日期
def site(request,username,**kwargs):
"""
:param request:
:param username:
:param kwargs: 如果该参数有值 也就意味着需要对article_list做额外的筛选操作
:return:
"""
# 先校验当前用户名对应的个人站点是否存在
user_obj = models.UserInfo.objects.filter(username=username).first()
# 用户如果不存在应该返回一个404页面
if not user_obj:
return render(request,‘errors.html‘)
blog = user_obj.blog
# 查询当前个人站点下的所有的文章
article_list = models.Article.objects.filter(blog=blog) # queryset对象 侧边栏的筛选其实就是对article_list再进一步筛选
if kwargs:
# print(kwargs) # {‘condition‘: ‘tag‘, ‘param‘: ‘1‘}
condition = kwargs.get(‘condition‘)
param = kwargs.get(‘param‘)
# 判断用户到底想按照哪个条件筛选数据
if condition == ‘category‘:
article_list = article_list.filter(category_id=param)
elif condition == ‘tag‘:
article_list = article_list.filter(tags__id=param)
else:
year,month = param.split(‘-‘) # 2020-11 [2020,11]
article_list = article_list.filter(create_time__year=year,create_time__month=month)
# 1 查询当前用户所有的分类及分类下的文章数
category_list = models.Category.objects.filter(blog=blog).annotate(count_num=Count(‘article__pk‘)).values_list(‘name‘,‘count_num‘,‘pk‘)
# print(category_list) # <QuerySet [(‘jason的分类一‘, 2), (‘jason的分类二‘, 1), (‘jason的分类三‘, 1)]>
# 2 查询当前用户所有的标签及标签下的文章数
tag_list = models.Tag.objects.filter(blog=blog).annotate(count_num=Count(‘article__pk‘)).values_list(‘name‘,‘count_num‘,‘pk‘)
# print(tag_list) # <QuerySet [(‘tank的标签一‘, 1), (‘tank的标签二‘, 1), (‘tank的标签三‘, 2)]>
# 3 按照年月统计所有的文章
date_list = models.Article.objects.filter(blog=blog).annotate(month=TruncMonth(‘create_time‘)).values(‘month‘).annotate(count_num=Count(‘pk‘)).values_list(‘month‘,‘count_num‘)
# print(date_list)
return render(request,‘site.html‘,locals())
# url设计
/username/article/1
# 先验证url是否会被其他url顶替
# 文章详情页和个人站点基本一致 所以用模版继承
# 侧边栏的渲染需要传输数据才能渲染 并且该侧边栏在很多页面都需要使用
1.哪个地方用就拷贝需要的代码(不推荐 有点繁琐)
2.将侧边栏制作成inclusion_tag
"""
步骤
1.在应用下创建一个名字必须叫templatetags文件夹
2.在该文件夹内创建一个任意名称的py文件
3.在该py文件内先固定写两行代码
from django import template
register = template.Library()
# 自定义过滤器
# 自定义标签
# 自定义inclusion_tag
"""
# 自定义inclusion_tag
@register.inclusion_tag(‘left_menu.html‘)
def left_menu(username):
# 构造侧边栏需要的数据
user_obj = models.UserInfo.objects.filter(username=username).first()
blog = user_obj.blog
# 1 查询当前用户所有的分类及分类下的文章数
category_list = models.Category.objects.filter(blog=blog).annotate(count_num=Count(‘article__pk‘)).values_list(
‘name‘, ‘count_num‘, ‘pk‘)
# print(category_list) # <QuerySet [(‘jason的分类一‘, 2), (‘jason的分类二‘, 1), (‘jason的分类三‘, 1)]>
# 2 查询当前用户所有的标签及标签下的文章数
tag_list = models.Tag.objects.filter(blog=blog).annotate(count_num=Count(‘article__pk‘)).values_list(‘name‘,
‘count_num‘,
‘pk‘)
# print(tag_list) # <QuerySet [(‘tank的标签一‘, 1), (‘tank的标签二‘, 1), (‘tank的标签三‘, 2)]>
# 3 按照年月统计所有的文章
date_list = models.Article.objects.filter(blog=blog).annotate(month=TruncMonth(‘create_time‘)).values(
‘month‘).annotate(count_num=Count(‘pk‘)).values_list(‘month‘, ‘count_num‘)
# print(date_list)
return locals()
"""
浏览器上你看到的花里胡哨的页面,内部都是HTML(前端)代码
那现在我们的文章内容应该写什么??? >>> html代码
如何拷贝文章
copy outerhtml
1.拷贝文章
2.拷贝点赞点踩
1.拷贝前端点赞点踩图标 只拷了html
2.css也要拷贝
由于有图片防盗链的问题 所以将图片直接下载到本地
课下思考:
前端如何区分用户是点了赞还是点了踩
1.给标签各自绑定一个事件
两个标签对应的代码其实基本一样,仅仅是是否点赞点踩这一个参数不一样而已
2.二合一
给两个标签绑定一个事件
// 给所有的action类绑定事件
$(‘.action‘).click(function () {
alert($(this).hasClass(‘diggit‘))
})
由于点赞点踩内部有一定的业务逻辑,所以后端单独开设视图函数处理
"""
# 个人建议:写代码先把所有正确的逻辑写完再去考虑错误的逻辑 不要试图两者兼得
import json
from django.db.models import F
def up_or_down(request):
"""
1.校验用户是否登陆
2.判断当前文章是否是当前用户自己写的(自己不能点自己的文章)
3.当前用户是否已经给当前文章点过了
4.操作数据库了
:param request:
:return:
"""
if request.is_ajax():
back_dic = {‘code‘:1000,‘msg‘:‘‘}
# 1 先判断当前用户是否登陆
if request.user.is_authenticated():
article_id = request.POST.get(‘article_id‘)
is_up = request.POST.get(‘is_up‘)
# print(is_up,type(is_up)) # true <class ‘str‘>
is_up = json.loads(is_up) # 记得转换
# print(is_up, type(is_up)) # True <class ‘bool‘>
# 2 判断当前文章是否是当前用户自己写的 根据文章id查询文章对象 根据文章对象查作者 根request.user比对
article_obj = models.Article.objects.filter(pk=article_id).first()
if not article_obj.blog.userinfo == request.user:
# 3 校验当前用户是否已经点了 哪个地方记录了用户到底点没点
is_click = models.UpAndDown.objects.filter(user=request.user,article=article_obj)
if not is_click:
# 4 操作数据库 记录数据 要同步操作普通字段
# 判断当前用户点了赞还是踩 从而决定给哪个字段加一
if is_up:
# 给点赞数加一
models.Article.objects.filter(pk=article_id).update(up_num = F(‘up_num‘) + 1)
back_dic[‘msg‘] = ‘点赞成功‘
else:
# 给点踩数加一
models.Article.objects.filter(pk=article_id).update(down_num=F(‘down_num‘) + 1)
back_dic[‘msg‘] = ‘点踩成功‘
# 操作点赞点踩表
models.UpAndDown.objects.create(user=request.user,article=article_obj,is_up=is_up)
else:
back_dic[‘code‘] = 1001
back_dic[‘msg‘] = ‘你已经点过了,不能再点了‘ # 这里你可以做的更加的详细 提示用户到底点了赞还是点了踩
else:
back_dic[‘code‘] = 1002
back_dic[‘msg‘] = ‘你个臭不要脸的!‘
else:
back_dic[‘code‘] = 1003
back_dic[‘msg‘] = ‘请先<a href="/login/">登陆</a>‘
return JsonResponse(back_dic)
<script>
// 给所有的action类绑定事件
$(‘.action‘).click(function () {
{#alert($(this).hasClass(‘diggit‘))#}
let isUp = $(this).hasClass(‘diggit‘);
let $div = $(this);
// 朝后端发送ajax请求
$.ajax({
url:‘/up_or_down/‘,
type:‘post‘,
data:{
‘article_id‘:‘{{ article_obj.pk }}‘,
‘is_up‘:isUp,
‘csrfmiddlewaretoken‘:‘{{ csrf_token }}‘
},
success:function (args) {
if(args.code == 1000){
$(‘#digg_tips‘).text(args.msg)
// 将前端的数字加一
// 先获取到之前的数字
let oldNum = $div.children().text(); // 文本 是字符类型
// 易错点
$div.children().text(Number(oldNum) + 1) // 字符串拼接了 1+1 = 11 11 + 1 = 111
}else{
$(‘#digg_tips‘).html(args.msg)
}
}
})
})
</script>
"""
我们先写根评论
再写子评论
点击评论按钮需要将评论框里面的内容清空
根评论有两步渲染方式
1.DOM临时渲染
2.页面刷新render渲染
子评论
点击回复按钮发生了几件事
1.评论框自动聚焦
2.将回复按钮所在的那一行评论人的姓名
@username
3.评论框内部自动换行
根评论子评论都是点击一个按钮朝后端提交数据的
parent_id
根评论子评论区别在哪?
parent_id
"""
"""
当一个文件夹下文件比较多的时候 你还可以继续创建文件夹分类处理
templates文件夹
backend文件夹
应用1文件夹
应用2文件夹
"""
有两个需要注意的问题
1.文章的简介
不能直接切去
应该先想办法获取到当前页面的文本内容之后截取150个文本字符
2.XSS攻击
针对支持用户直接编写html代码的网址
针对用户直接书写的script标签 我们需要处理
1.注视标签内部的内容
2.直接将script删除
如何解决?
我们自己的话
针对1 后端通过正则表达式筛选
针对2 首先需要确定及获取script标签
这两步都好烦 有木有人来帮我一下
beautifulsoup模块 bs4模块
专门用来帮你处理html页面内的
该模块主要用于爬虫程序
下载千万不要下错了
pip3 install beautifulsoup4
# 模块使用
soup = BeautifulSoup(content,‘html.parser‘)
tags = soup.find_all()
# 获取所有的标签
for tag in tags:
# print(tag.name) # 获取页面所有的标签
# 针对script标签 直接删除
if tag.name == ‘script‘:
# 删除标签
tag.decompose()
# 文章简介
# 1 先简单暴力的直接切去content 150个字符
# desc = content[0:150]
# 2 截取文本150个
desc = soup.text[0:150]
"""
当你发现一个数据处理起来不是很方便的时候
可以考虑百度搜搜有没有现成的模块帮你完成相应的功能
"""
编辑器的种类有很多,你可以自己去网上搜索
http://kindeditor.net/doc.php
别人写好了接口 但是接口不是你自己的
你需要手动去修改
# 在使用别人的框架或者模块的时候 出现了问题不要慌 看看文档可能会有对应的处理方法
@login_required
def set_avatar(request):
if request.method == ‘POST‘:
file_obj = request.FILES.get(‘avatar‘)
# models.UserInfo.objects.filter(pk=request.user.pk).update(avatar=file_obj) # 不会再自动加avatar前缀
# 1.自己手动加前缀
# 2.换一种更新方式
user_obj = request.user
user_obj.avatar = file_obj
user_obj.save()
return redirect(‘/home/‘)
blog = request.user.blog
username = request.user.username
return render(request,‘set_avatar.html‘,locals())
<label class="id_myfile" for="id_myfile">
<img id="id_img" width="80px" src="{% static ‘images/default.png‘ %}" alt="">
</label>
<input id="id_myfile" type="file" style="display: none">
<script>
$(‘#myfile‘).change(function(){
// 1、生成一个文件阅读器对象
let myFileReaderObj = new FileReader();
// 2、获取用户上传的头像文件
let fileObj = $(this)[0].files[0];
// 3、将文件对象交给阅读器对象读取
myFileReaderObj.readAsDataURL(fileObj) //异步IO操作
// 4、利用文件阅读器将文件展示到前端页面 修改src属性
// 使用onload等待文件阅读器加载完毕后再执行
myFileReaderObj.onload = function(){
$(‘#myfile‘).attr(‘src‘, myFileReaderObj.result)
}
})
</script>
# settings.py
‘‘‘
MEDIA_ROOT = os.path.join(BASE_DIR,‘media‘)
用户上传文件会自动创建media文件夹然后在该文件夹内存储数据
还需要将资源暴露给用户
‘‘‘
# 如何自定义暴露后端资源
# urls.py
from django.views.static import serve
from BBS14 import settings
# 固定写法
url(r‘^media/(?P<path>.*)‘,serve,{‘document_root‘:settings.MEDIA_ROOT}),
from PIL import Image, ImageDraw, ImageFont
‘‘‘
Image:生成图片
ImageDraw:在图片上涂画
ImageFont:控制字体样式
‘‘‘
from io import BytesIO,StringIO
‘‘‘
# 内存管理器模块
BytesIO:临时帮你存储数据 返回的时候数据是二进制
StringIO:临时帮你存储数据 返回的时候数据是字符串
‘‘‘
from PIL import Image, ImageDraw, ImageFont
from io import BytesIO # 内存管理器模块
import random
# 利用pillow模块动态产生图片验证码
def get_code(request):
img_obj = Image.new(‘RGB‘, (134, 38), get_random()) # 产生画布
img_draw = ImageDraw.Draw(img_obj) # 创建画笔
# 设置字体样式以及大小
img_font = ImageFont.truetype(‘static/font/GothamNights.ttf‘, 30)
code = ‘‘
# 产生过随机验证码(5位数)
for i in range(5):
random_upper = chr(random.randint(65, 90))
random_lower = chr(random.randint(97, 122))
random_int = str(random.randint(0, 9))
# 随机选择上面的一个来拼接
tmp = random.choice([random_upper, random_lower, random_int])
# 往画布图片上涂画
img_draw.text((i*25+5, 1), tmp, get_random(), img_font)
code += tmp
# 存储验证码到session方便拿取使用
request.session[‘code‘] = code
io_obj = BytesIO()
img_obj.save(io_obj, ‘png‘)
return HttpResponse(io_obj.getvalue())
<img id="id_code" width="" height="" class="" src="{% url ‘getcode‘ %}" alt="">
‘‘‘
1.修改正则表达式
2.调整url方法的位置
‘‘‘
# 官方提供的方法
from django.db.models.functions import TruncMonth
Article.objects
.annotate(month=TruncMonth(‘timestamp‘)) # Truncate to month and add to select list
.values(‘month‘) # Group By month
.annotate(c=Count(‘id‘)) # Select the count of the grouping
.values(‘month‘, ‘c‘) # (might be redundant, haven‘t tested) select month and count
‘‘‘
准备工作3步走
1、创建文件名为templatetags的文件夹
2、文件夹内创建任意名字的py文件(mytags.py)
3、在mytags.py内写入如下两行代码
from django import template
register = template.Library()
‘‘‘
# 开始代码搬运
# mytags.py
from django import template
from app01 import models
from django.db.models import Count
from django.db.models.functions import TruncMonth
import datetime
register = template.Library()
@register.inclusion_tag(‘right_menu.html‘)
def right_menu(username):
user_obj = models.UserInfo.objects.filter(username=username).first()
blog = user_obj.blog
article_list = models.Article.objects.filter(blog=blog)
# 文章分类
category_list = models.Category.objects.filter(blog=blog) .annotate(count=Count(‘article‘)).values(‘name‘, ‘count‘, ‘pk‘)
# 文章标签
tags_list = models.Tag.objects.filter(blog=blog).annotate(count=Count(‘article‘)).values(‘name‘, ‘count‘, ‘pk‘)
# 日期归档
date_list = models.Article.objects.filter(blog=blog).annotate(month=TruncMonth(‘create_time‘)).values(‘month‘) .annotate(count=Count(‘id‘)).values(‘month‘, ‘count‘)
# 园龄
now_time = datetime.datetime.now()
create_time = user_obj.create_time
age = now_time - create_time
blog_age = age.days
return locals()
<div class="card mb-4" >
<div class="card-header bg-info text-light">
公告
</div>
<div class="card-body">
<div class="media">
<img width="80" src="/media/{{ user_obj.avatar }}" class="mr-3 img-thumbnail" alt="">
<div class="media-body" style="font-size: 13px">
<p class="mb-1">昵称: {{ blog.site_title }}</p>
<p>园龄: {{ blog_age }} 天</p>
</div>
</div>
</div>
</div>
<div class="card mb-4" >
<div class="card-header bg-info text-light">
文章分类
</div>
<div class="card-body">
<ul class="list-group list-group-flush">
{% for category in category_list %}
<a href="/{{ username }}/category/{{ category.pk }}/" class="category_text pb-1">{{ category.name }} ({{ category.count }})</a>
{% endfor %}
</ul>
</div>
</div>
<div class="card mb-4" >
<div class="card-header bg-info text-light">
文章标签
</div>
<div class="card-body">
<ul class="list-group list-group-flush">
{% for tag in tags_list %}
<a href="/{{ username }}/tag/{{ tag.pk }}/" class="category_text pb-1">{{ tag.name }} ({{ tag.count }})</a>
{% endfor %}
</ul>
</div>
</div>
<div class="card" >
<div class="card-header bg-info text-light">
日期归档
</div>
<div class="card-body">
<ul class="list-group list-group-flush">
{% for date in date_list %}
<a href="/{{ username }}/archive/{{ date.month|date:‘Y‘ }}/{{ date.month|date:‘m‘ }}/" class="category_text pb-1">{{ date.month|date:‘Y年m月‘ }} ({{ date.count }})</a>
{% endfor %}
</ul>
</div>
</div>
{% load mytags %}
{% right_menu username %}
"""
在开发任意的web项目的时候 其实到了后期需要写的代码会越来越少
都是用已经写好的url填写到a标签href属性完成跳转即可
"""
主要功能总结
表设计 开发流程(粗燥流程 还可以细化)
注册功能
forms组件使用
头像动态展示(FileReader文件阅读器)
fileReader.readAsDataURL(fileObj); # 异步IO操作,需要使用onload等待加载完毕后执行
错误信息提示
登陆功能
图片验证码(pillow模块+io模块中的BytesIO)
from PIL import Image,ImageFont,ImageDraw
img_obj = Image.new(‘RGB‘, (width,height), color) # 创建画布
img_draw = ImageDraw.Draw(img_obj)# 创建画笔
ImageFont.truetype(‘file_path‘, ‘font_size‘)# 创建字体
img_draw.text((width,height), ‘str‘, color, font) # 在图片上写字
io_obj = BytesIO()
mg_obj.save(io_obj, ‘png‘) # 指定存储格式
io_obj.getvalue() //读取二进制数据
滑动验证码
首页展示
media配置
‘‘‘MEDIA_ROOT = os.path.join(BASE_DIR, ‘media‘)‘‘‘
主动暴露任意资源接口
‘‘‘
from django.views.static import serve
from xxx import settings
url(r‘^media/(?P<path>.*)‘, serve, {‘document‘:settings.MEDIA_ROOT})
‘‘‘
个人站点展示
侧边栏展示
侧边栏筛选(涉及到年月分组时可以使用TruncMonth)
‘‘‘
from django.db.models.functions import TruncMonth
objects.filter().annotate(month=TruncMonth(‘时间字段‘)).values(‘month‘)
‘‘‘
侧边栏inclusion_tag
‘‘‘
三步走:
1、创建templatetags文件夹
2、创建任意py文件
3、书写from django import templatetag
register = templatetag.Library
‘‘‘
文章详情页
点赞点踩(通过设置唯一的class属性来操作同一个点击事件实现点赞点踩)
评论(先写更评论,再写子评论,通过parent_id来判断)
点击回复,评论框聚焦并且渲染回复人姓名
点击提交,清空评论框,渲染临时评论区,刷新永久展示
后台管理
发表文章(kindeditor富文本编辑器的使用http://kindeditor.net/doc.php)
针对简介保存html代码问题
soup = BeautifulSoup(content, ‘html.parser‘)
使用直接使用bs4实例化的对象所提供的text方法即可
soup.text
针对XSS攻击
方式1:将script标签注释
方式2:删除script标签(beautifulsoup4库解决)
for tag in soup.find_all():
if tag.name == ‘script‘:
tag.decompose()
修改头像
将注册页面的动态渲染代码拷贝修改即可
(需要注意的是,orm语句使用update,无法自动拼接路径前缀了,因此采用.save()的方法修改)
"""
针对bbs需要你掌握每一个功能的书写思路 内部逻辑
之后再去敲代码熟悉 找感觉
"""
标签:template pen sqlite数据库 loading roc 读取 key memcach 两种
原文地址:https://www.cnblogs.com/guanxiying/p/13138520.html