标签:正则 play 训练 flat code cat margin input fit
本地没有GPU环境,今天在百度AIStudio的GPU服务器上竟然跑起来了Keras版本的猫狗分类,服务器配置如图: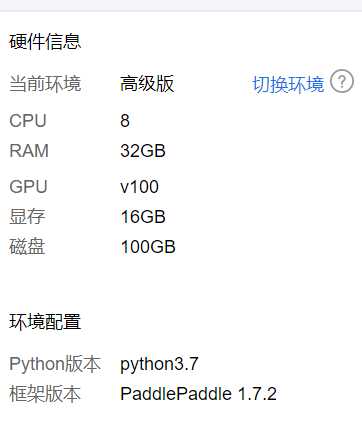
具体操作步骤。
1.首先打开百度AI Studio,并建立自己的工程。
2.数据准备,下载猫狗分类数据集在本地电脑,选取猫狗各2000图片压缩为zip文件,在刚建立的工程中上次zip文件到百度服务器(最大上传150M的文件)
3.服务器中解压zip文件,需要先安装zip,同时在notebook中添加图片分类脚本,将数据集分为训练集、验证集和测试集,脚本代码下边会附上。
pip install zip
4.安装训练所需要的库,keras和TensorFlow
pip install keras
pip install tensorflow
5.将模型代码添加到notebook并运行。
数据集分类脚本,将上边的zip文件解压到/home/aistudio/data/datasets
import os, shutil origin_dataset_dir = ‘/home/aistudio/data/datasets‘ base_dir = ‘/home/aistudio/data/datasets_small‘ if not os.path.exists(base_dir): os.mkdir(base_dir) train_dir = os.path.join(base_dir, ‘train‘) os.mkdir(train_dir) validation_dir = os.path.join(base_dir, ‘validation‘) os.mkdir(validation_dir) test_dir = os.path.join(base_dir, ‘test‘) os.mkdir(test_dir) train_cats_dir = os.path.join(train_dir, ‘cats‘) os.mkdir(train_cats_dir) train_dogs_dir = os.path.join(train_dir, ‘dogs‘) os.mkdir(train_dogs_dir) validation_cats_dir = os.path.join(validation_dir, ‘cats‘) os.mkdir(validation_cats_dir) validation_dogs_dir = os.path.join(validation_dir, ‘dogs‘) os.mkdir(validation_dogs_dir) test_cats_dir = os.path.join(test_dir, ‘cats‘) os.mkdir(test_cats_dir) test_dogs_dir = os.path.join(test_dir, ‘dogs‘) os.mkdir(test_dogs_dir) fnames = [‘cat.{}.jpg‘.format(i) for i in range(1000)] for fname in fnames: src = os.path.join(origin_dataset_dir, fname) dst = os.path.join(train_cats_dir, fname) shutil.copyfile(src, dst) fnames = [‘cat.{}.jpg‘.format(i) for i in range(1000, 1500)] for fname in fnames: src = os.path.join(origin_dataset_dir, fname) dst = os.path.join(validation_cats_dir, fname) shutil.copyfile(src, dst) fnames = [‘cat.{}.jpg‘.format(i) for i in range(1500, 2000)] for fname in fnames: src = os.path.join(origin_dataset_dir, fname) dst = os.path.join(test_cats_dir, fname) shutil.copyfile(src, dst) fnames = [‘dog.{}.jpg‘.format(i) for i in range(1000)] for fname in fnames: src = os.path.join(origin_dataset_dir, fname) dst = os.path.join(train_dogs_dir, fname) shutil.copyfile(src, dst) fnames = [‘dog.{}.jpg‘.format(i) for i in range(1000, 1500)] for fname in fnames: src = os.path.join(origin_dataset_dir, fname) dst = os.path.join(validation_dogs_dir, fname) shutil.copyfile(src, dst) fnames = [‘dog.{}.jpg‘.format(i) for i in range(1500, 2000)] for fname in fnames: src = os.path.join(origin_dataset_dir, fname) dst = os.path.join(test_dogs_dir, fname) shutil.copyfile(src, dst) print(‘total traing cat images:‘, len(os.listdir(train_cats_dir))) print(‘total traing dog images:‘, len(os.listdir(train_dogs_dir))) print(‘total validation cat images:‘, len(os.listdir(validation_cats_dir))) print(‘total validation dog images:‘, len(os.listdir(validation_dogs_dir))) print(‘total test cat images:‘, len(os.listdir(test_cats_dir))) print(‘total test dog images:‘, len(os.listdir(test_dogs_dir)))
模型代码如下,由于数据集较小,进行了数据增强,同时采用dropout正则化来规避过拟合:
from keras import models from keras import layers from keras import optimizers from keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation=‘relu‘, input_shape=(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation=‘relu‘)) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation=‘relu‘)) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation=‘relu‘)) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(512, activation=‘relu‘)) model.add(layers.Dense(1, activation=‘sigmoid‘)) print(‘--------------------------------------------------------------‘, model.summary()) model.compile(loss=‘binary_crossentropy‘, optimizer=optimizers.RMSprop(lr=1e-4), metrics=[‘acc‘]) train_dir = ‘/home/aistudio/data/datasets_small/train‘ validation_dir = ‘/home/aistudio/data/datasets_small/validation‘ train_datagen = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True,) test_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( train_dir, target_size=(150, 150), batch_size=32, class_mode=‘binary‘) validation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=32, class_mode=‘binary‘) history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50 ) model.save(‘cat_and_dog_small_2.h5‘) acc = history.history[‘acc‘] val_acc = history.history[‘val_acc‘] loss = history.history[‘loss‘] val_loss = history.history[‘val_loss‘] epochs = range(1, len(acc)+1) plt.plot(epochs, acc, ‘bo‘, label=‘Traing acc‘) plt.plot(epochs, val_acc, ‘b‘, label=‘Validation acc‘) plt.title(‘Training and validation accuracy‘) plt.legend() plt.figure() plt.plot(epochs, loss, ‘bo‘, label=‘Traing loss‘) plt.plot(epochs, val_loss, ‘b‘, label=‘Validation loss‘) plt.title(‘Training and validation loss‘) plt.legend() plt.show()
运行起来后可以看到每轮耗时大概36秒,本地CPU每轮大概耗时100秒。真是工欲善其事必先利其器。这里声明一点,不是paddlepaddle做的不好,是我刚开始接触深度学习,首先看的框架就是keras,所以一些验证学习都是基于keras上来做的,后边肯定会转向paddlepaddl,时间问题而已。另外百度在深度学习的推广以及支持力度是真的给力,这里深深的感谢。
百度GPU上:

本地CPU:

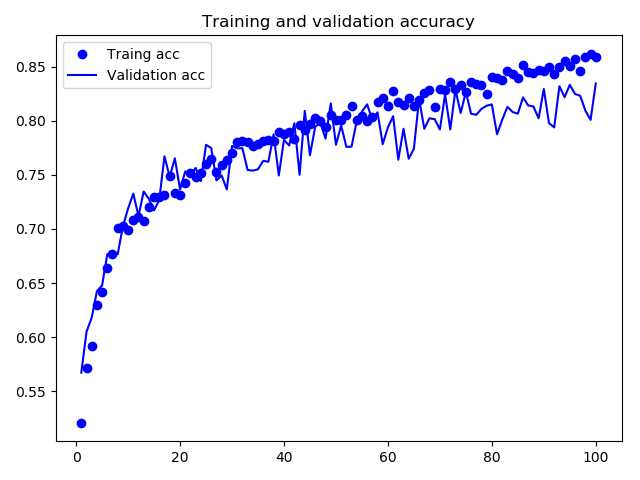
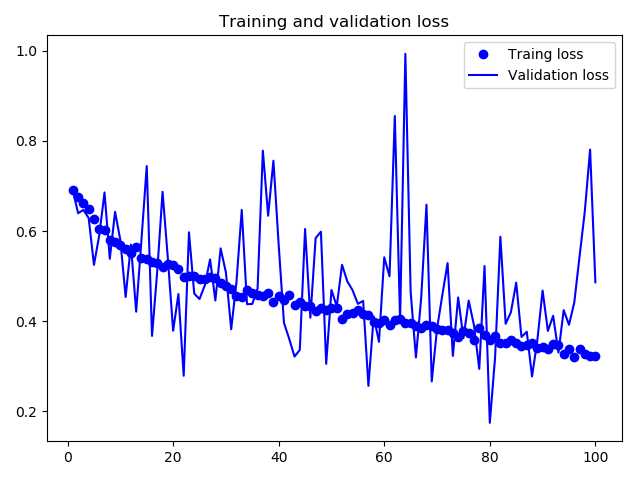
训练结束的精度和损失图示如下,精度80%左右,验证损失变化较大,还需要进一步查看原因:
使用GPU在AIStudio服务器进行猫狗分类 Keras框架
标签:正则 play 训练 flat code cat margin input fit
原文地址:https://www.cnblogs.com/andy2020/p/13140007.html