标签:渲染 单位 ken loading lap queryset ace def use
pip install whoosh django-haystack jieba
注册haystack框架:
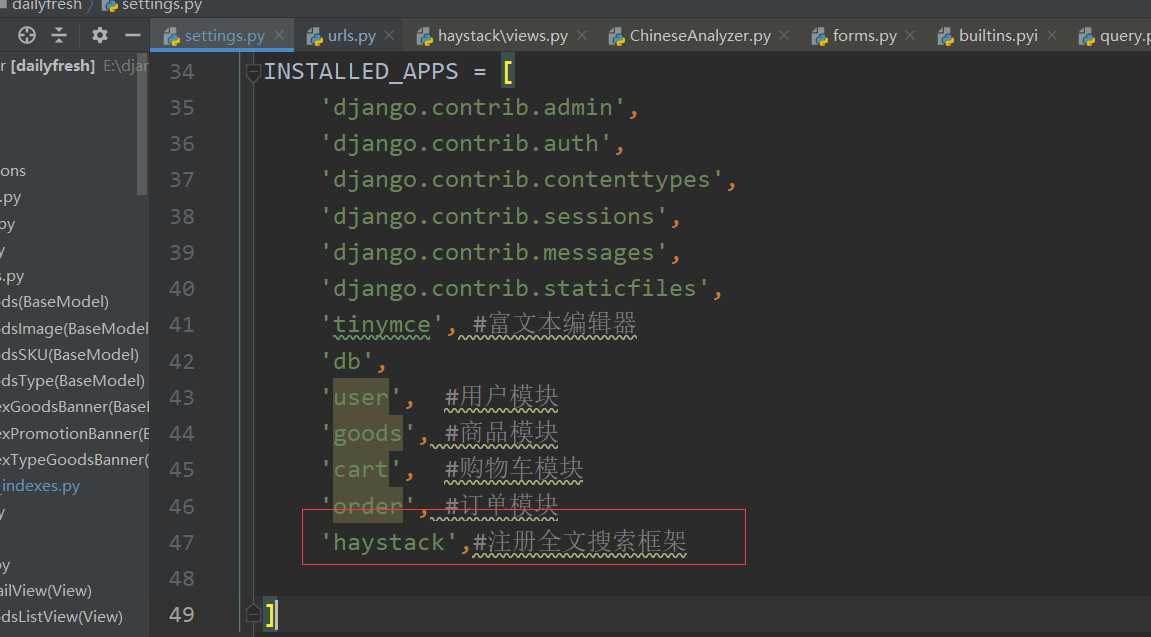
配置搜索引擎、索引文件路径、自动更新索引文件:

HAYSTACK_CONNECTIONS = {
‘default‘: {
‘ENGINE‘: ‘haystack.backends.whoosh_backend.WhooshEngine‘,
‘PATH‘: os.path.join(BASE_DIR, ‘whoosh_index‘),
},
}
这里用到的模型类:
class GoodsSKU(BaseModel):
‘‘‘商品SKU模型类‘‘‘
status_choices = (
(0, ‘下线‘),
(1, ‘上线‘),
)
type = models.ForeignKey(‘GoodsType‘,on_delete=models.CASCADE, verbose_name=‘商品种类‘)
goodsSPU = models.ForeignKey(‘Goods‘,on_delete=models.CASCADE, verbose_name=‘商品SPU‘)
name = models.CharField(max_length=20, verbose_name=‘商品名称‘)
desc = models.CharField(max_length=256, verbose_name=‘商品简介‘)
price = models.DecimalField(max_digits=10, decimal_places=2, verbose_name=‘商品价格‘)
unite = models.CharField(max_length=20, verbose_name=‘商品单位‘)
image = models.ImageField(upload_to=‘goods‘, verbose_name=‘商品图片‘)
stock = models.IntegerField(default=1, verbose_name=‘商品库存‘)
sales = models.IntegerField(default=0, verbose_name=‘商品销量‘)
status = models.SmallIntegerField(default=1, choices=status_choices, verbose_name=‘商品状态‘)
class Meta:
db_table = ‘df_goods_sku‘
verbose_name = ‘商品‘
verbose_name_plural = verbose_name
def __str__(self):
return self.name
在模型所在的应用下创建search_indexes.py文件:
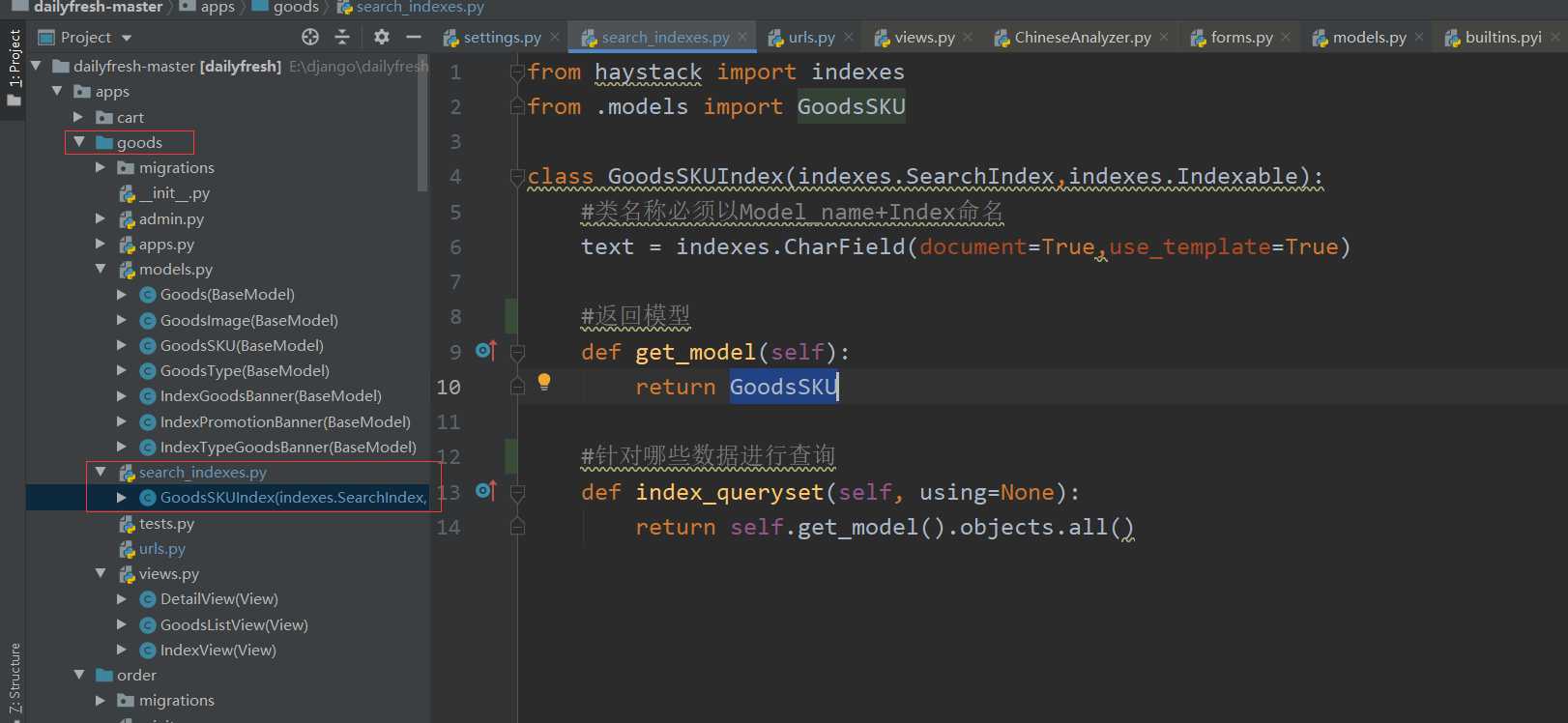
文件中代码如下:
from haystack import indexes
from .models import GoodsSKU
class GoodsSKUIndex(indexes.SearchIndex,indexes.Indexable):
#类名称必须以Model_name+Index命名
text = indexes.CharField(document=True,use_template=True)
#返回模型
def get_model(self):
return GoodsSKU
#针对哪些数据进行查询
def index_queryset(self, using=None):
return self.get_model().objects.all()
执行如下命令,在配置文件中配置的目录下生成索引文件:
python manage.py rebuild_index
因为在索引类中配置了use_template=True,所以需要在templates下按照如下路径建立模板文件:
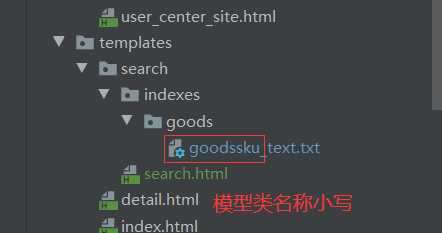
模板中文件内容:
{{ object.name }} #根据商品名称建立索引
{{ object.desc }} #根据商品描述建立索引
{{ object.goodsSPU.detail }} #根据商品详情建立索引
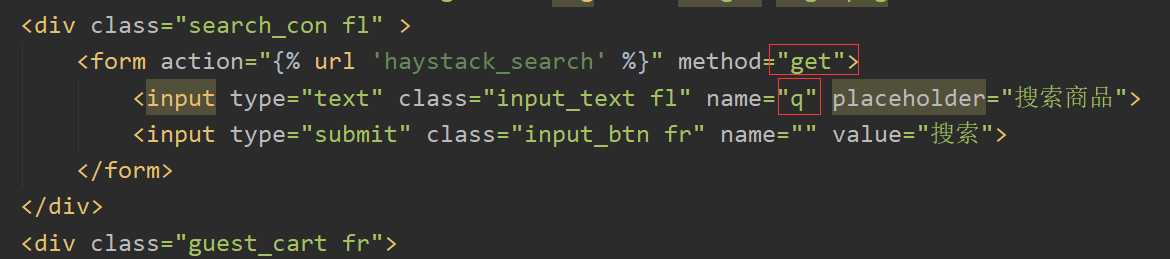
构建搜索表单,下图中红框内容为固定的:
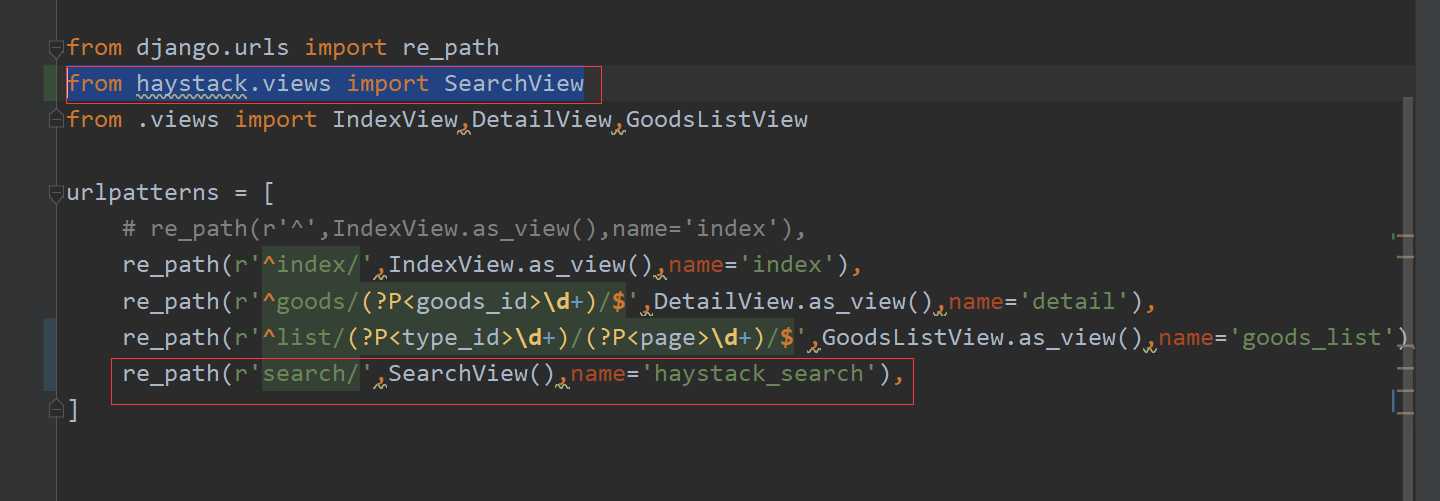
在该应用的路由中添加对应路由:
可通过SearchView()查看搜索结果中返回的内容:
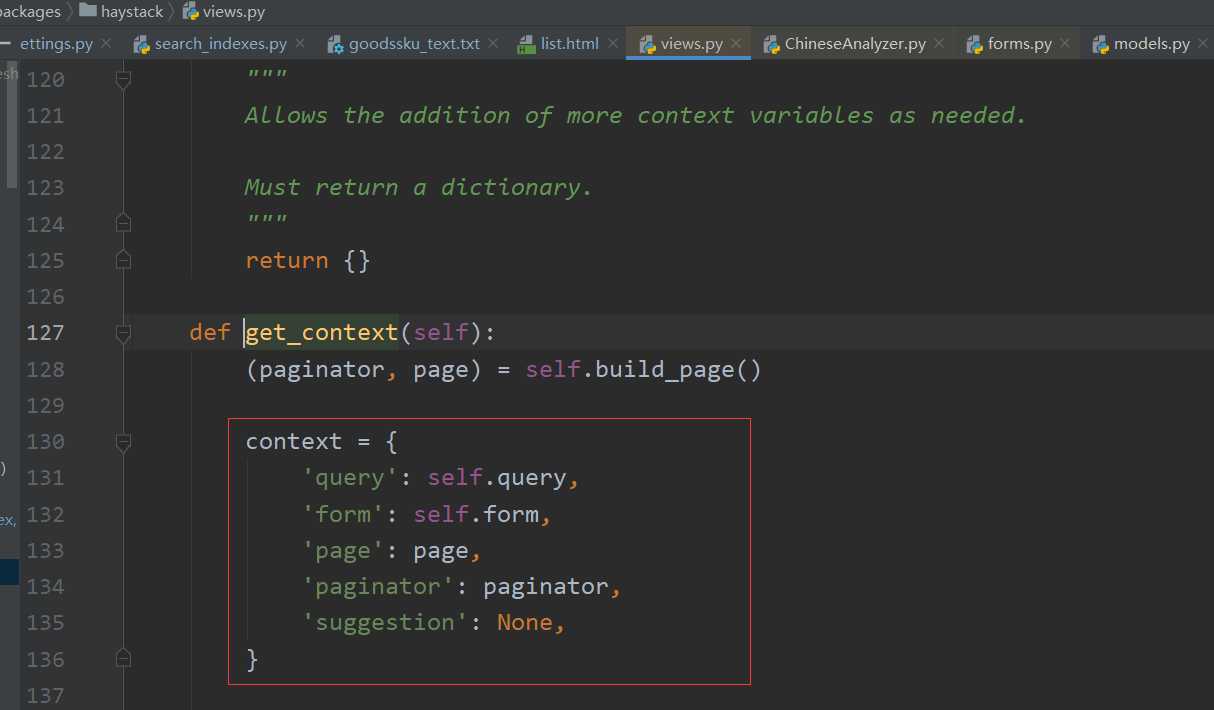
其中主要用到的:
query为搜索的关键字
page为当前页搜索结果对象
paginator为分页对象
注意:遍历page时得到的不是模型对象,遍历后的object属性才是对应模型中的对象
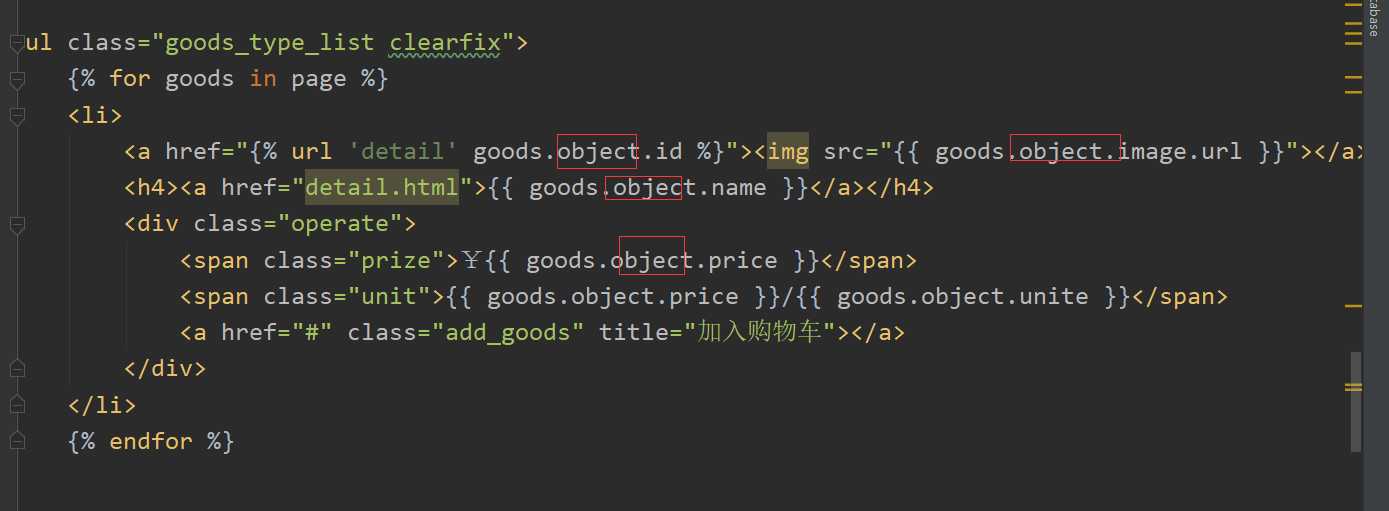
在模板下建立search.html文件,渲染搜索的结果:
在E:\PY_ENV\dailyfresh_env\Lib\site-packages\haystack\backends(haystack的backends目录下)新建ChineseAnalyzer.py文件:
View Code复制该目录下的whoosh_backend.py文件并重命名为whoosh_cn_backend.py
在whoosh_cn_backend.py中执行如下操作:
from .ChineseAnalyzer import ChineseAnalyzer
找到
analyzer=StemmingAnalyzer()
改为
analyzer=ChineseAnalyzer()修改配置文件中引用的搜索引擎:
#全文搜索配置
HAYSTACK_CONNECTIONS = {
‘default‘: {
‘ENGINE‘: ‘haystack.backends.whoosh_cn_backend.WhooshEngine‘,
‘PATH‘: os.path.join(BASE_DIR, ‘whoosh_index‘),
},
}
重新生成索引文件:
python manage.py rebuild_index
django使用全文搜索引擎haystack+jieba分词
标签:渲染 单位 ken loading lap queryset ace def use
原文地址:https://www.cnblogs.com/Xiaojiangzi/p/13155295.html
