标签:单节点 www ann 很多 mysql 持久化 连接池 only 超过
由于互联网发展,用户量激增,传统的架构直接使用关系型数据库,已经不能扛得住现在的并发量了,mysql单机一般的配置并发达到2000基本就顶天了,而且如果打到这个负载,mysql的性能会非常差,所以redis基本是现在各大互联网公司的标配。
本篇文章会以问答的方式编写,方便大家查看。
要明白这个问题,首先要明白redis的线程模型,参考这篇文章:Redis线程模型,我总结一下这篇文章的核心点如下:
这里可能很多人有疑问,什么事io多路复用?
看这几篇文章:操作系统层面聊聊BIO,NIO和AIO (epoll),Linux IO模式及 select、poll、epoll详解,从底层入手,图解 Java NIO BIO MIO AIO 四大IO模型与原理
以下内容来自知乎一个用户的回答,我觉得挺好,就贴在这里:
ok,以上只是解释了什么io多路复用,为什么写了那么多的篇幅,因为我发现写redis的文章,基本都没有解释这个,所以我这里就解释一下,其实决定redis快的因素还有另外两个:
这一块很简单,常用的就五种string,list,hash,set,zset,参考如下文章:Redis五种数据类型
redis还可以作为队列,但是有rabbitmq这种这么专业的队列,为什么要用redis呢,还有订阅发布功能,这个也不常用。
redis有两种持久化策略,分别是rdb、aof
rdb是什么?
rdb是一种持久化策略,将内存中数据制作成快照文件保存到磁盘上。
rdb触发机制?
1.通过执行save或者bgsave命令,save是主线程执行的,会阻塞redis,bgsave是fork出来一个子线程执行,不会阻塞主线程执行
2.通过在redis.conf中配置,如下
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存参考:Redis RDB 持久化方式 , Redis详解(六)------ RDB 持久化
aof是什么?
aof也是一种持久化策略,是通过保存redis增删改的操作日志的方式。
aof保存执行步骤是什么?
1. 命令追加
redis每次执行增删改操作的时候,都会以协议格式的方式追加到aof缓存中
2.文件的写入和同步
write: 根据条件,将aof buf中的数据写入到aof 文件中
save: 根据条件,调用 fsync 或 fdatasync 函数,将aof文件保存到磁盘上
文件的写入和同步的方式有哪几种?
redis每次执行完事件之后,都会调用flushAppendOnlyFile函数判断是否需要将缓存区中的数据持久化到磁盘文件中,这个策略取决于redis.conf的appendfsync选项,该选项可以有三种选择:
1.always:每次执行一条增删改操作之后,都会执行上面的write和save操作,而且是由主线程执行的,会阻塞redis,所以这种方式的效率是最差的,但是是最安全的,如果redis突然挂了,只会丢失一个事件循环中所产生的命令数据。
2.everysec: 每秒执行一次将aof缓存中的数据持久化到磁盘上,redis会在后台启动一个线程来处理,不会影响主线程,redis默认是采用这种方式,效率很快,如果redis突然宕机,丢失的数据可能操作2s的数据,为什么是两秒,看下图;
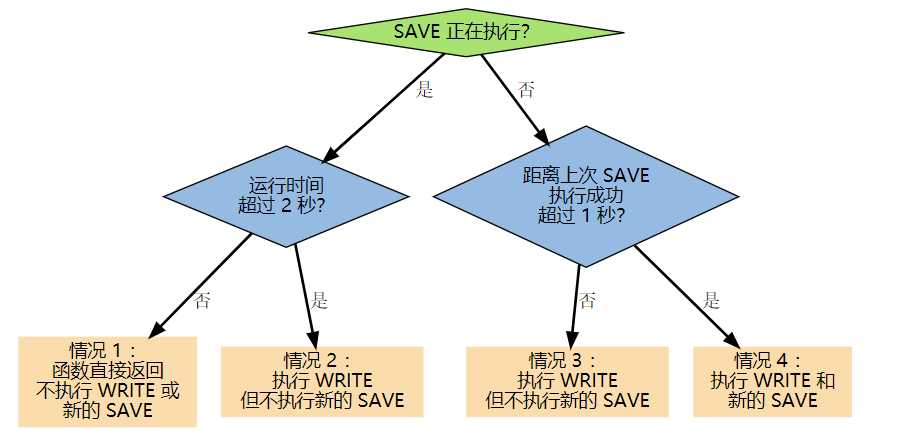
在情况2的时候,由于上次执行的save的事件过长,超过2s,就会导致本次save的操作不会执行,如果这时候redis发生宕机,丢失的数据就会超过2s,参考:<Redis>AOF持久化
3.no: 不保存,就是说每次调用flushAppendOnlyFile函数,只会执行write操作,并不会执行save操作,这个write操作的执行是主线程执行的,会阻塞,同时下面介绍的3种save操作也会阻塞主线程,那什么时候会把write操作写的aof文件持久化到磁盘呢?
可以发现以上三种方式,aof文件持久化到磁盘上的时间间隔越来越长,对redis性能影响确实是越来越低,但是安全性确实越来越差。
参考文章:Redis AOF 持久化详解
如果磁盘上的aof文件越来越大,磁盘不够用怎么处理?
使用aof重写机制,举个例子,set a 1,set a 2 ,set a 3,这三条命令依次执行,其实可以合并成一条命令,就是set a 3,其实aof重写也是差不多这样,他是直接将redis中保存的key-value转化为命令,为了防止影响主线程,aof重写会新启动一个新的子线程,将这些命令写入到aof重写缓存中,那如果在这个重写的过程,redis中又有新的请求进来怎么处理,答案是直接写入到aof的重新缓存中,整个过程不会影响正常的aof写入,当aof重写完成之后,会给父进程发送信号,父进程会调用一个信号函数做如下工作:
1.将aof重写缓存中的内容写入aof文件
2.使用新的aof文件替换原来的aof文件
这两个过程由于是主进程完成的,所以会阻塞主进程。
aof的重写出发时机?
BGREWRITEAOF手动触发。服务器在AOF功能开启的情况下,会维持以下三个变量:
aof_current_size。aof_rewrite_base_size。aof_rewrite_perc。每次当serverCron(服务器周期性操作函数)函数执行时,它会检查以下条件是否全部满足,如果全部满足的话,就触发自动的AOF重写操作:
server.aof_rewrite_min_size(默认为1MB),或者在redis.conf配置了auto-aof-rewrite-min-size大小;auto-aof-rewrite-percentage参数,不设置默认为100%)如果前面三个条件都满足,并且当前AOF文件大小比最后一次AOF重写时的大小要大于指定的百分比,那么触发自动AOF重写。
参考文章:Redis之AOF重写及其实现原理
当redis的内存满了之后,如果这时再有新的写请求进来,redis会如何处理,redis中一下几种策略
优点:简单
缺点:无法高可用
主节点负责写操作,然后同步到从节点,从节点只负责读操作
优点:降低了master的读压力
缺点:主节点挂了无法保证高可用,而且没有解决主节点负载过高的问题
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,如果主服务器挂了,哨兵会重新选择一个从节点来作为主节点,sentinel节点个数一般设置3个就可以了,每个sentinel节点都会向redis的节点和别的sentinel节点发送ping请求,如果操作规定的时间没有返回,这个sentinel就会主观认为这个节点下线了,如果多数的节点都认为某个redis节点下线了,就会变成客观节点下线,如果是主节点,就会启动选主过程。
优点:可以保证高可用
缺点:选主阶段redis集群不可用,没有解决主节点压力过高问题,每个节点都保存了redis的所有数据,没有分布式存储
采用无中心的结构,redis的每个节点互相连接,每个节点都会设置一个或者多个从节点,可以设置成主节点只负责写,从节点负责读,读写分离的模式
优点:每个redis不用保存全部的缓存数据,而是采用分片存储,可以节省空间,集群高可用,同时解决了哨兵模式中主节点写压力过大的问题
缺点:数据异步同步,不保证强一致性
缓存雪崩:redis中多数的key在同一时间过期,导致大量的请求直接访问数据库,导致数据库压力过高。
解决办法:为每个key的过期时间增加一个随机数,防止同一时间很多key同时过期
缓存击穿:少量的热点的key过期的时候,有大量的请求进来,直接访问数据,导致数据库负载过高
解决办法:访问数据库的时候加上同步锁,一次只允许一个线程去访问数据库
缓存穿透: 有大量的请求进来,其中请求的key在redis和数据库中都不存,导致大量的请求直接访问数据库,导致数据库负载过高。
解决办法:1.直接把没有结果的key在redis中也缓存下来,因为这种请求一般为黑客攻击,除非黑客用大量的肉鸡,使用这种方法就可以解决
2.增加校验,把一些不合法的请求直接拒绝了,不让请求可以打到数据库,比如数据的id是自增的,来了一个id为负数的请求,直接拒绝。
要明白redis如何进行分片,就要先明白什么是一致性hash,参考这篇文章:浅谈负载均衡算法与实现
如果是使用redis节点来实现分布式锁,还是很简单的,步骤如下:
加锁:使用setnx lock uuid px 10命令(如果存在就不操作,如果不存在就设置),uuid的作用用来区分是哪个线程加的锁,之后为这个key增加一个过期时间,防止发生死锁。
解锁:我一开始的想法是直接把redis上加锁的lock删除就可以,其实不行,比如:如果A加锁成功,但是由于A执行的时间太长了,导致锁过期了,B获取到了锁,如果A执行完了,准备释放锁,直接把lock删除了,但是这时候A的锁早就不存在了,就会有问题,所以在解锁的时候,要先判断是不是自己加的锁,如果是自己加的锁再删除,而且整个过程要是一个原子操作,使用lua脚本完成,脚本如下:
if redis.call("get", KEYS[1]) == ARGV[1] then return redis.call("del", KEYS[1]) else return 0 end
但是使用redis单节点解锁有一个坏处就是,如果加锁的那个redis节点挂了,可能会出问题,所以后来redis的作者就提出了redlock,我先叙述一下这个算法的流程。
jedis
最老牌的Java客户端,提供了非常丰富的api,但是有一个问题,就是在多线程使用jedis实例访问redis的时候,是线程不安全的,所以需要使用连接池,每个线程使用不同的jedis实例
lettuce
spring-redis默认的Java客户端,线程安全
redission
线程安全,提供了redis的分布式锁实现方式
建议:建议使用lettuce,如果有分布式上的需求,推荐使用redission
参考文章
史上最全Redis面试49题(含答案):哨兵+复制+事务+集群+持久化等
https://www.cnblogs.com/wuhen8866/p/11882142.html
标签:单节点 www ann 很多 mysql 持久化 连接池 only 超过
原文地址:https://www.cnblogs.com/gunduzi/p/13138220.html