标签:假设 特定 ack 通过 inpu tps 问题 html load
在NLP中,对于把词转为向量的操作,最朴素的想法是one-hot独热编码形式,即一个词占一维向量。但这样有两个缺点:
1)不考虑词与词之间的顺序(文本中词的顺序也很重要)
2)假设词是独立的。例如猫和狗、床和沙发,词之间原本是有不同的亲疏远近关系的
3)得到的特征是稀疏的。如果所有的词各占一维,那么这个向量会过于稀疏,甚至造成维度灾难。
为了解决上述问题,引入distributed representation:通过训练,将每个词映射到较短的词向量上。实际中,较难对较短词向量的每个维度做很好解释。较短词向量的维度,一般训练时自己指定。
映射需满足:1)这个映射是单设;2)映射后向量不会丢失所含的信息。
这个映射过程称为word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。也就是降维,但与单纯的降维也不同,这个嵌入的训练过程会引入词的上下文。感觉更像是CNN中channel数的变换。
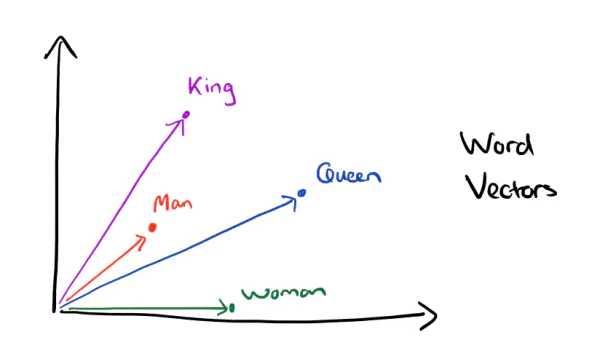
有了distributed representation表示的较短词向量,可以更容易分析词之间的关系。例如vec(King) - vec(Man) + vec(Woman) = vec(Queen)
word2vec
word2vec模型就是一个简化的神经网络
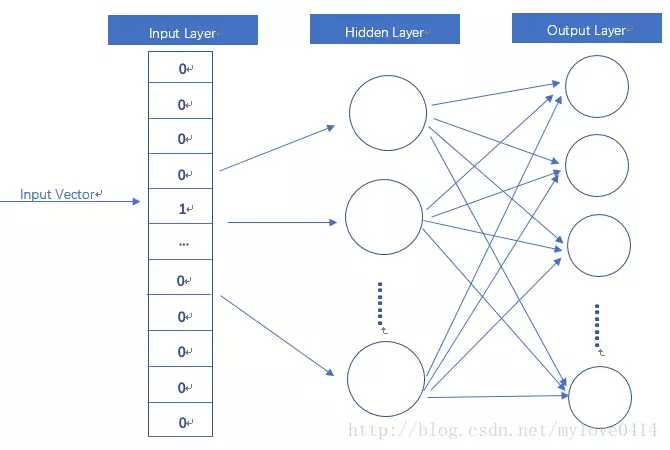
input layer输入向量是one-hot形式。hidden layer没有激活函数,是线性单元。output layer维度与input layer维度一样,使用softmax。
当用这个模型训练好后,真正需要的是这个模型通过训练学得的参数,如隐层权重矩阵。
这个权重矩阵,
word2vec的输入/输出分为两种,CBOW(Continuous Bag-of-Words)与Skip-Gram。
CBOW 输入某特征词的上下文相关的词对应的词向量。输出这个特定词的词向量。
Skip-Gram与CBOW相反,输入特定一个词的词向量,输出特定词对应的上下文词向量。
CBOW对小型语料比较合适,Skip-Gram在大型语料中表现更好。
为什么??
CBOW
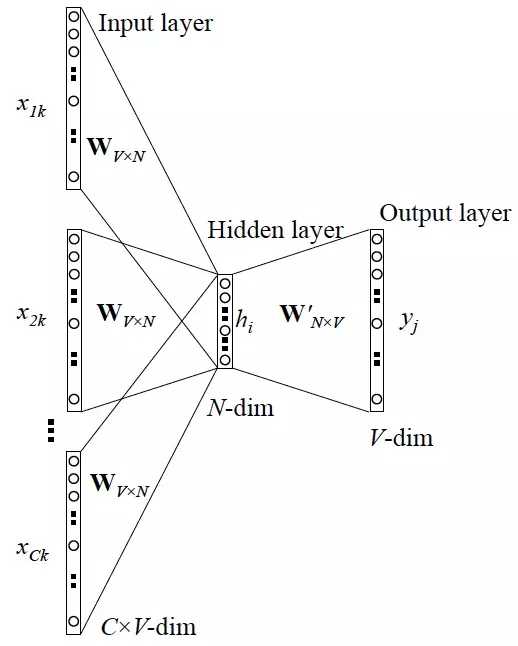
输入层:
上下文单词的onehot作为输入。其中上下文单词数量为C,C这个由超参window size决定,如果window size=2 表示取target word的前两个单词和后两个单词作为input词,此时C=4。每个单词的向量dim为V。
所有onehot分别乘以共享的输入权重矩阵WV*N,其中N为超参。
所得的向量相加求平均作为输入给隐层向量,得到的shape为 1*N
隐藏层:
输入的向量乘以输出权重矩阵W‘N*V ,得到的shape为 1*V。
输出层:
再经过softmax激活函数处理,得到 V 维的概率分布,每维代表一个单词。
概率最大的单词即为target word,即预测出的中间词。将target word与true label的onehot比较,误差越小越好。一般使用交叉熵代价函数。
根据此误差再更新权重矩阵。采用梯度下降法更新W和W‘。
训练完成后,输入层每个单词与W相乘得到的向量就是词向量(word embedding),W这个矩阵就是所有单词的word embedding,也叫look up table。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
任一单词的onehot乘以W这个矩阵都将得到自己的word embedding了。
那 W ‘ 不需要了吗?
Skip-Gram
参考博客:
https://www.jianshu.com/p/471d9bfbd72f
https://zhuanlan.zhihu.com/p/26306795
https://www.cnblogs.com/peghoty/p/3857839.html
标签:假设 特定 ack 通过 inpu tps 问题 html load
原文地址:https://www.cnblogs.com/YeZzz/p/13159090.html