标签:err thread sele intro inf readline png chrome cti
最近做了一个新项目,因为项目需要大量电影数据,猫眼电影又恰好有足够的数据,就上猫眼爬数据了。
1、先分析一下网页地址,发现电影都是被排好序号了,这就很简单了。
2、在分析页面,这次主要爬取黄色框中的内容。在浏览器中按F12检查元素,只要把Div获取出来就算完成了。
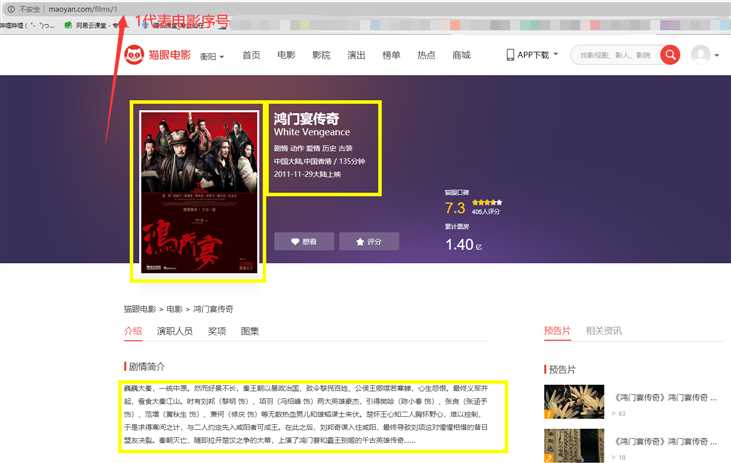
下面贴代码:
主函数
1 static void Main(string[] args) 2 { 3 int errorCount = 0;//计算爬取失败的次数 4 int count = 450;//结束范围 5 for (int i = 401; i <= count; i++) 6 { 7 Thread.Sleep(2000);//每隔两秒爬取一次,不要给服务器压力 8 try 9 { 10 HtmlWeb web = new HtmlWeb(); 11 //https://maoyan.com/films/1 12 web.OverrideEncoding = Encoding.UTF8; 13 HtmlDocument doc = web.Load($"https://maoyan.com/films/{i}");//把url中的1替换为i 14 15 HtmlDocument htmlDoc = new HtmlDocument(); 16 string url = $"https://maoyan.com/films/{i}"; 17 18 //获取电影名 19 HtmlNode MovieTitle = doc.DocumentNode.SelectSingleNode("//div[@class=‘movie-brief-container‘]/h1[@class=‘name‘]");//分析页面结构后得到的div 20 if (MovieTitle == null)//如果是null,那么表明进入验证页面了,执行第二种方法 21 { 22 string urlResponse = URLRequest(url); 23 htmlDoc.LoadHtml(urlResponse); 24 MovieTitle = htmlDoc.DocumentNode.SelectSingleNode("//div[@class=‘movie-brief-container‘]/h1[@class=‘name‘]"); 25 if (MovieTitle == null)//如果是null,那么表明进入验证页面了。(第二种方法也失效) 26 { 27 //此处需要进入浏览器手动完成验证 或者 自行分析验证页面实现自动验证 28 } 29 } 30 string title = MovieTitle.InnerText; 31 //Console.WriteLine(MovieTitle.InnerText); 32 33 //获取电影海报 34 HtmlNode MovieImgSrc = doc.DocumentNode.SelectSingleNode("//div[@class=‘celeInfo-left‘]/div[@class=‘avatar-shadow‘]/img[@class=‘avatar‘]"); 35 if (MovieImgSrc == null) 36 { 37 38 MovieImgSrc = htmlDoc.DocumentNode.SelectSingleNode("//div[@class=‘celeInfo-left‘]/div[@class=‘avatar-shadow‘]/img[@class=‘avatar‘]"); 39 } 40 //Console.WriteLine(MovieImgSrc.GetAttributeValue("src", "")); 41 string imgurl = MovieImgSrc.GetAttributeValue("src", ""); 42 43 //电影类型 44 HtmlNodeCollection MovieTypes = doc.DocumentNode.SelectNodes("//div[@class=‘movie-brief-container‘]/ul/li[@class=‘ellipsis‘]"); 45 if (MovieTypes == null) 46 { 47 MovieTypes = htmlDoc.DocumentNode.SelectNodes("//div[@class=‘movie-brief-container‘]/ul/li[@class=‘ellipsis‘]"); 48 } 49 string types = "", artime = "", releasetime = ""; 50 51 foreach (var item in MovieTypes[0].ChildNodes) 52 { 53 if (item.InnerText.Trim() != "") 54 { 55 //Console.WriteLine(item.InnerText.Trim()); 56 types += item.InnerText.Trim() + "-"; 57 } 58 } 59 artime = MovieTypes[1].InnerText; 60 releasetime = MovieTypes[2].InnerText; 61 //Console.WriteLine(MovieTypes[i].InnerText); 62 63 //剧情简介 64 string intro = ""; 65 HtmlNode introduction = doc.DocumentNode.SelectSingleNode("//div[@class=‘mod-content‘]/span[@class=‘dra‘]"); 66 if (introduction == null) 67 { 68 introduction = htmlDoc.DocumentNode.SelectSingleNode("//div[@class=‘mod-content‘]/span[@class=‘dra‘]"); 69 } 70 //Console.WriteLine(introduction.InnerText); 71 intro = introduction.InnerText; 72 //Console.WriteLine(i); 73 74 using (FileStream fs = new FileStream(@"d:\Sql.txt", FileMode.Append, FileAccess.Write)) 75 { 76 fs.Lock(0, fs.Length); 77 StreamWriter sw = new StreamWriter(fs); 78 sw.WriteLine($"INSERT INTO Movies VALUES(‘{title}‘,‘{imgurl}‘,‘{types}‘,‘{artime}‘,‘{releasetime}‘,‘{intro.Trim()}‘);"); 79 fs.Unlock(0, fs.Length);//一定要用在Flush()方法以前,否则抛出异常。 80 sw.Flush(); 81 } 82 83 } 84 catch (Exception ex) 85 { 86 errorCount++; 87 Console.WriteLine(ex); 88 } 89 } 90 Console.WriteLine($"结束 成功:{count - errorCount}条,失败:{errorCount}条"); 91 Console.ReadLine(); 92 93 }
URLRequest方法
1 static string URLRequest(string url) 2 { 3 // 准备请求 4 HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); 5 6 // 设置GET方法 7 request.Method = "GET"; 8 request.Timeout = 6000; //60 second timeout 9 request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36"; 10 11 string responseContent = null; 12 13 // 获取 Response 14 using (WebResponse response = request.GetResponse()) 15 { 17 using (Stream stream = response.GetResponseStream()) 18 { 19 // 读取流 20 using (StreamReader streamreader = new StreamReader(stream)) 21 { 23 responseContent = streamreader.ReadToEnd(); 24 } 25 } 26 } 27 28 return (responseContent); 29 }
先进入for循环,到时候把url中的 1 替换为 i ,就可以实现自动爬取所有电影了。
解析html代码我用的是第三方类库 HtmlAgilityPack,大家可以在Nuget中搜索到。
我将爬取的数据转换为Sql语句了,存在D盘根目录下 Sql.txt。
下面是结果

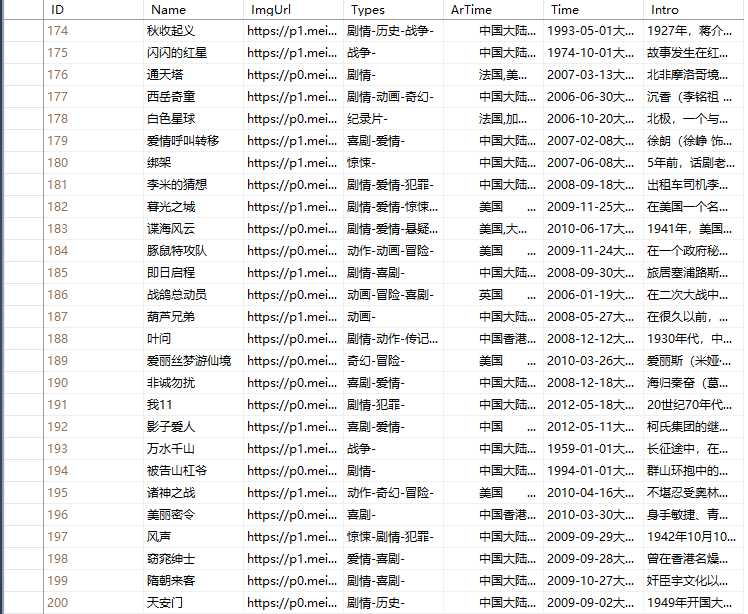
一共爬了200条数据
大家注意一下,程序报错 如果是空异常,那么表明没有获取到相应的div,没有获取到相应的div就表明猫眼让你跳转到验证中心页面了,你要进入到浏览器验证一下,或者更换IP访问。
最后再提醒一下大家,要慢慢的获取数据,不然会403。
标签:err thread sele intro inf readline png chrome cti
原文地址:https://www.cnblogs.com/LingLis/p/13161594.html