标签:mamicode 它的 模式 分组 事件 app nbsp 决定 pool
主要有三部分组成,threadpool,scheduler,task。
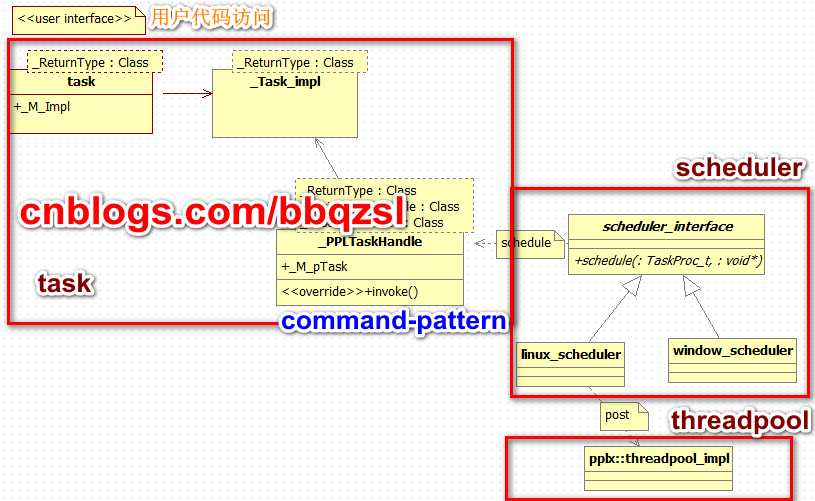
三者关系如上图示,pplx只着重实现了task部分功能,scheduler跟threadpool只是简略实现。
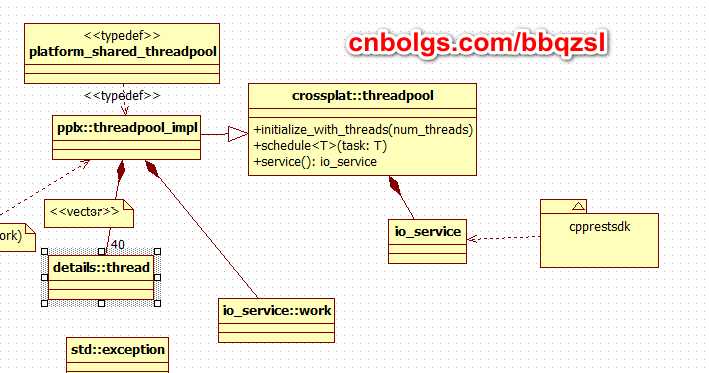
threadpool主要依赖boost.asio达到跨平台的目标,cpprestsdk的 io操作同时也依赖这个threadpool。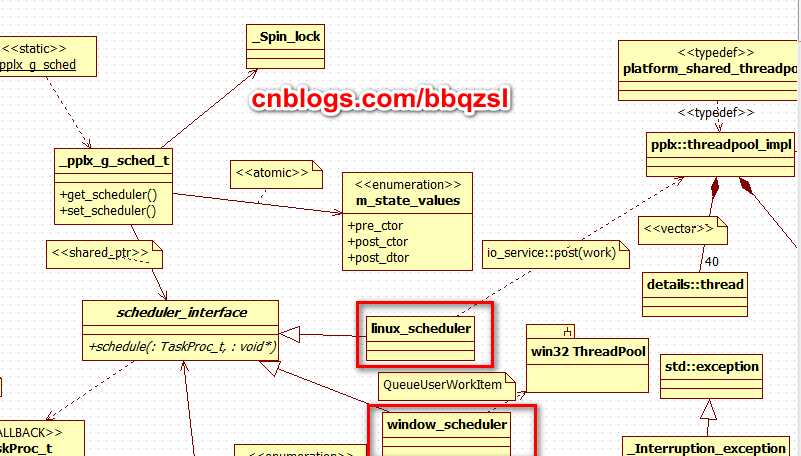
pplx提供了两个版本的scheduler,分别是
linux_scheduler依赖boost.asio.threadpool。
window_schedule依赖win32 ThreadPool。
默认的scheduler只是简单地将work投递到threadpool进行分派。
用户可以根据自己需要,实现scheduler_interface,提供复杂的调度。
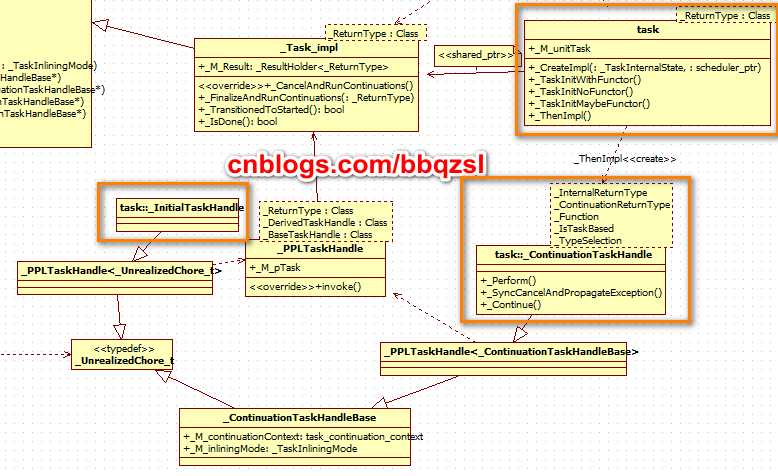
每个task关联着一个_Task_impl实现体,一个_TaskCollection_t(唤醒事件,后继任务队列,这个队列的任务之间的关系是并列的),还有一个_PPLTaskHandle代码执行单元。
task,并行执行的单位任务。通过scheduler将代码执行单元调度到线程去执行。
task提供类似activeobject模式的功能,可以看作是一个future,通过get()同步阻塞等待执行结果。
task提供拓扑模型,通过then()创建后续task,并作为后继执行任务。注意的是每个task可以接受不限数量的then(),这些后继任务之间并不串行。例 task().then().then()串行,(task1.then(), task1.then())并行。一个任务在执行完成时,会将结果传递给它的所有直接后继执行任务。
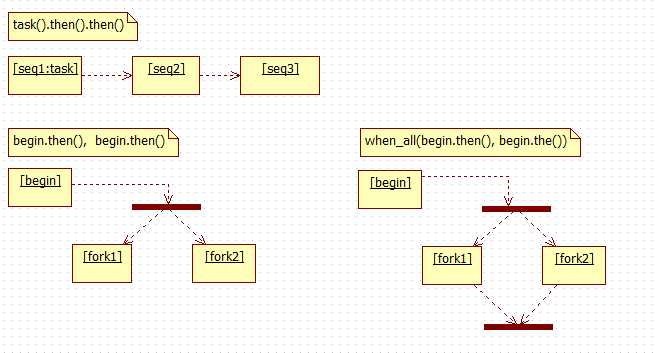
此外,task拓扑除了then()函数外,还可以在执行lambda中添加并行分支,然后可以在后继任务中同步这些分支。
也就是说后继任务同步原本task拓扑外的task拓扑才能继续执行。
1 auto fork0 =
2 task([]()->task<void>{
3 auto fork1 =
4 task([]()->task<void>{
5 auto fork2 =
6 task([](){
7 // do your fork2 work
8
9 });
10 // do your fork1 work
11
12 return fork2;
13 }).then([](task<void>& frk2){ frk2.wait(); }); // will sync fork2
14 // do your fork0 work
15
16 return fork1;
17 }).then([](task<void>& frk1){ frk1.wait(); }); // will sync fork1
18 fork0.wait(); // sync fork1, fork2
上面的方式有一个问题,如果里层的fork先完成,将不要阻塞线程,但是外层fork先完成就不得不阻塞线程等待内层fork完成。
所以可以用when_all
task<task<void> >([]()->task<void> {
std::vector<task<void> > forks;
forks.push_back( task([]() { /* do fork0 work */ }) );
forks.push_back( task([]() { /* do fork1 work */ }) );
forks.push_back( task([]() { /* do fork2 work */ }) );
forks.push_back( task([]() { /* do fork3 work */ }) );
return when_all(std::begin(forks), std::end(forks));
}).then([](task<void> forks){
forks.wait();
}).wait();
通过上面的方式,也可以在lambda中,将其它task拓扑插入到你原来的task拓扑。
task结束,分两种情况,完成以及取消。取消执行,只能在执行代码时通过抛出异常,task并没有提供取消的接口。任务在执行过程中抛出的异常,就会被task捕捉,并暂存异常,然后取消执行。异常在wait()时重新抛出。下面的时序分析可以看到全过程 。
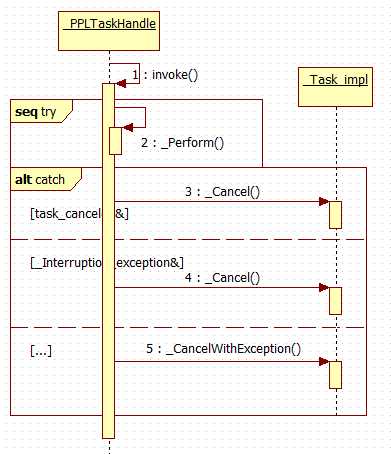
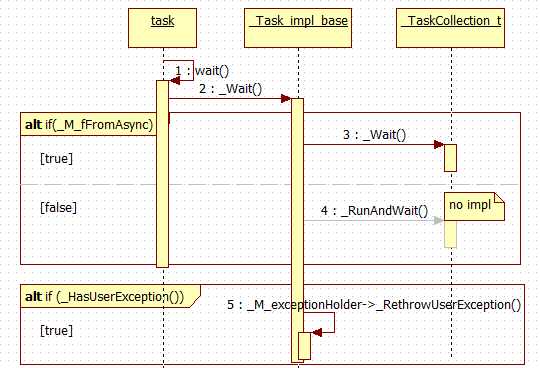
值得注意的是,PPL中task原本的设计是的有Async与Inline之分的。在_Task_impl_base::_Wait()有一小段注释说明
// If this task was created from a Windows Runtime async operation, do not attempt to inline it. The
// async operation will take place on a thread in the appropriate apartment Simply wait for the completed
// event to be set.
也就是task除了由scheduler调度到线程池分派执行,还可以强制在wait()函数内分派执行,后继task也不必再次调度而可以在当前线程继续分派执行。但是pplx没有实现
class _TaskCollectionImpl
{
...
void _Cancel()
{
// No cancellation support
}
void _RunAndWait()
{
// No inlining support yet
_Wait();
}
下面是对task的时序分析。
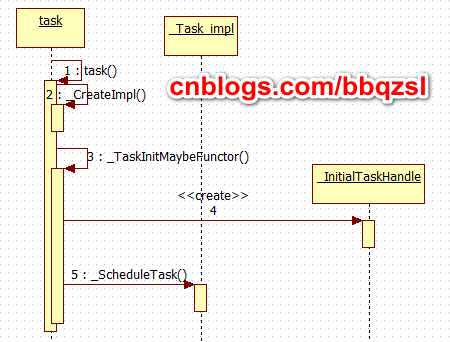
开始的task创建_InitialTaskHandle, 一种只能用于始首的Handle执行单元。
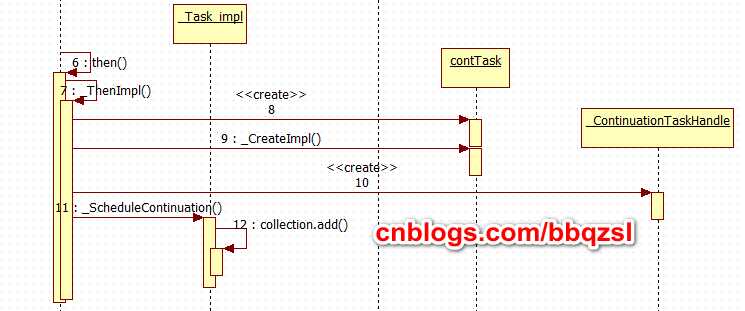
通过then()添加的task,创建_ContinuationTaskHandle,(一种可以入链的后继执行单元),并暂存起来。
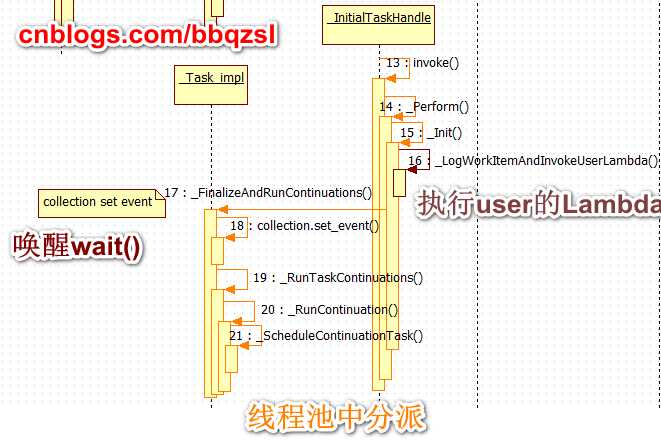
当一个任务在线程池中分派结束时,就会将所有通过then()添加到它结尾的后继任务一次过向scheduler调度出去。
任务只能通过抛出异常从而自己中止执行,task并暂存异常(及错误信息)。
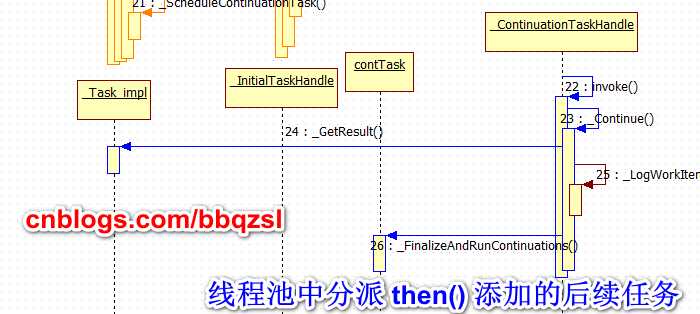
后继任务被调度到线程池继续分派执行。
这里顺便讨论一个开销,在window版本中,每个task都有一个唤醒事件,使用事件内核对象,都要创建释放一个内核对象,在高并行任务时,可能会消耗过多内核对象,消耗句柄数。
并且continuation后继任务,在默认scheduler调度下,不会在同一线程中分派,所有后继任务都会简单投递到线程池。由线程池去决定分派的线程。所以由then()串行起来的任务可能会由不同的线程顺序分派,从而产生开销。因为pplx并没有实现 Inline功能,所有task都会视作Async重新调度到线程池。
标签:mamicode 它的 模式 分组 事件 app nbsp 决定 pool
原文地址:https://www.cnblogs.com/bbqzsl/p/13165300.html