标签:split load 运行 字符串数组 pre out keyset color Collector

public class CollectorDemo { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); //需求1:得到名字为3个字的流 Stream<String> stringStream = list.stream().filter(s -> s.length() == 3); //需求2:把使用Stream流操作完毕的数据收集到List集合中并遍历 List<String> names = stringStream.collect(Collectors.toList()); for (String name : names){ System.out.println(name); } //创建Set集合 Set<Integer> set = new HashSet<>(); set.add(10); set.add(20); set.add(30); set.add(33); set.add(35); //需求3:得到年龄大于25的流 Stream<Integer> setStream = set.stream().filter(age -> age > 25); //需求4:把使用Set流操作完毕的数据收集到Set集合中并遍历 Set<Integer> ages = setStream.collect(Collectors.toSet()); for (int age : ages){ System.out.println(age); } //定义一个字符串数组,每一个字符串数据由姓名和年龄数据组合而成 String[] strArray = {"林青霞,30","张曼玉,35","王祖贤,33","柳岩,25"}; //需求5:得到字符串中年龄数据大于28的流 Stream<String> arrayStream = Stream.of(strArray).filter(s -> Integer.parseInt(s.split(",")[1]) > 28); //需求6:把使用Stream流操作完毕的数据收集到Map集合中并遍历,字符串中的姓作为键,年龄作为值 Map<String, Integer> map = arrayStream.collect(Collectors.toMap((s -> s.split(",")[0]), s -> Integer.parseInt(s.split(",")[1]))); //遍历map集合 Set<String> keySet = map.keySet(); for (String key : keySet){ Integer value = map.get(key); System.out.println(key+","+value); } } }
运行结果:
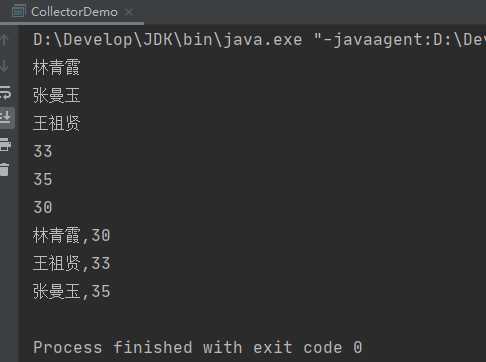
标签:split load 运行 字符串数组 pre out keyset color Collector
原文地址:https://www.cnblogs.com/pxy-1999/p/13166595.html