标签:try file windows height xlsx clear 数据处理 import 云图
一.前期准备,抓取HTML我们所需要关键信息
目标url:https://search.jd.com/Search?keyword=shouji&enc=utf-8&wq=shouji&pvid=a1727a28a24544829b30ef54d049feae
目标url其中page可以换页可以更改
然后跳转url转到相关数据页面:
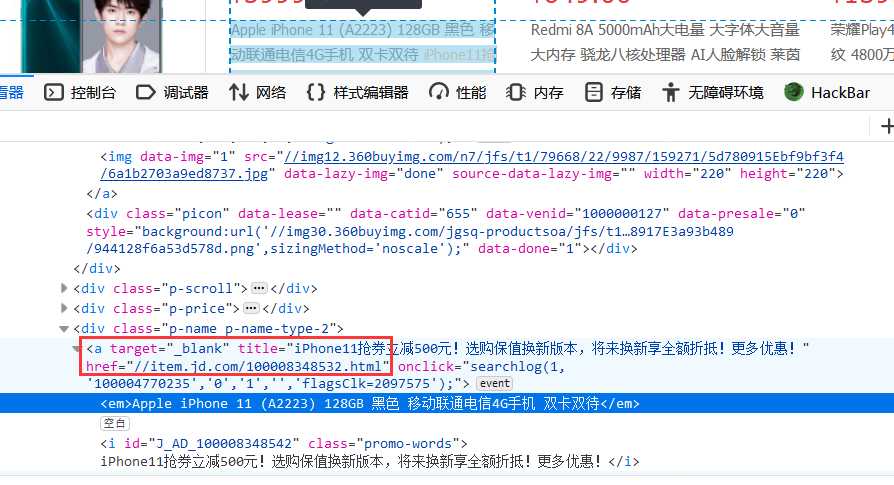
跳转到手机详细页面我们需要找到手机相关信息eg:名称 价格 销量等
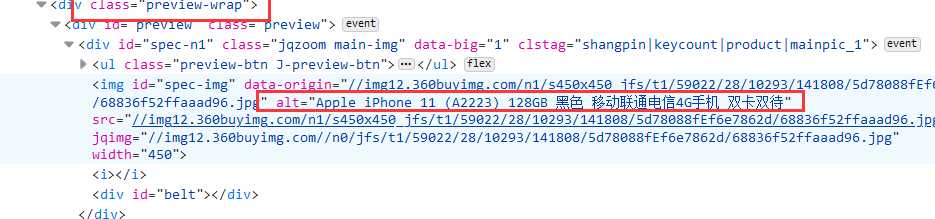
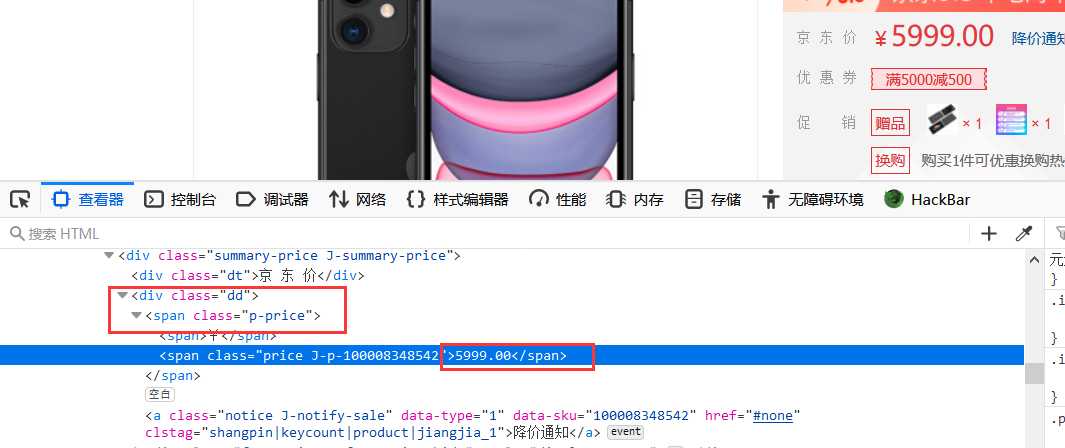
前期准备工作完成
二.代码编写
1.库的导入
2.函数功能 a.请求网页 b.数据处理 c.词云图设计
3.效果展示
完整代码

import requests import re from bs4 import BeautifulSoup import json import os import csv import jieba from wordcloud import WordCloud import numpy as np import PIL header = { ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36‘ } if os.path.exists("./存储文件/JDphone.xlsx"): os.remove("./存储文件/JDphone.xlsx") #获取每个手机对应的详情页 def get_list(): # 非法URL invalidLink=‘javascript:;‘ result = [] _url = ‘https://search.jd.com/Search?keyword=手机&suggest=1.rem.0.V03--38s0&wq=手机&page={p}&s=1&click=0‘ for i in range(1): #爬取的页数 url = _url.format(p = str(i)) session = requests.session() session.headers = header res = session.get(url=url,timeout=20) res.encoding = res.apparent_encoding html = res.text soup = BeautifulSoup(html,‘lxml‘) # print(soup) _result = soup.find(‘ul‘,class_=‘gl-warp clearfix‘).find_all(‘a‘) for k in _result: try: link = k.get(‘href‘) except: link = ‘‘ if link is not None: #过滤非法链接 if link == invalidLink: pass elif ‘https:‘ + link in result: pass else: # print(‘https:‘ + link) result.append(‘https:‘ + link) return result #数据存储 def save_data(href_list): filename = ‘手机信息.csv‘ # 写入的表格名称 outputfile = open(filename, ‘w‘, newline=‘‘) # 以写方式打开表格,取消空行 # 创建一个csv.writer对象 传入一个文件句柄,默认以逗号作为分隔符 csv_writer = csv.writer(outputfile, dialect=‘excel‘) urls = href_list total = len(urls) count = 1 for url in urls: print(‘正在爬取:‘ + str(count) + ‘/‘ + str(total)) count += 1 try: commodity_id = re.sub(r‘\D‘, "", url) # 商品编号 session = requests.session() session.headers = header priceUrl = ‘https://p.3.cn/prices/mgets?skuIds={}‘.format(commodity_id) priceres = session.get(url=priceUrl) jsons = json.loads(priceres.text[0:-1]) commodity_price= jsons[0][‘p‘] # 商品价格 res = session.get(url=url, timeout=20) res.encoding = res.apparent_encoding html = res.text soup = BeautifulSoup(html, ‘lxml‘) result_1 = soup.find(‘div‘, class_=‘jqzoom main-img‘).find_all(‘img‘)[0] commodity_name = result_1.get(‘alt‘) # 商品名称 csv_writer.writerow([commodity_id,commodity_price,commodity_name,url]) f = open(‘11.txt‘, ‘a‘) f.write(commodity_name,‘utf-8‘) f.close() except: pass def ciyuntu(): # 1.读出词语 text = open(‘11.txt‘, ‘r‘).read() print(text) # 2.把数据切开 cut_text = jieba.cut(text) # 3.以空格拼接起来 result = " ".join(cut_text) print(result) # 4.生成词云 #导入图片 image1 = PIL.Image.open(r‘640.png‘) Mask = np.array(image1) wc = WordCloud( font_path=‘font/yunmo.ttf‘, # 字体路劲 background_color=‘white‘, # 背景颜色 width=1600, height=800, max_font_size=25, # 字体大小 min_font_size=5, mask=Mask, # 背景图片 max_words=1000 ) wc.generate(result) wc.to_file(‘词云图12.png‘) # 图片保存 print(‘词云图生成完成-----‘) if __name__ == ‘__main__‘: href_list = get_list() save_data(href_list) ciyuntu()
标签:try file windows height xlsx clear 数据处理 import 云图
原文地址:https://www.cnblogs.com/Inti/p/13166748.html
