标签:特性 适配器 子序列 谓词 头文件 pointer 重复 顺序存储 none
为了建立数据结构和算法的一套标准,并且降低他们之间的耦合关系,以提升各自的独立性、弹性、交互操作性(相互合作性,interoperability),诞生了STL。
STL提供了六大组件,彼此之间可以组合套用,这六大组件分别是:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器。
容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据,从实现角度来看,STL容器是一种class template。
算法:各种常用的算法,如sort、find、copy、for_each。从实现的角度来看,STL算法是一种function tempalte.
迭代器:扮演了容器与算法之间的胶合剂,共有五种类型,从实现角度来看,迭代器是一种将operator* , operator-> , operator++,operator–等指针相关操作予以重载的class template. 所有STL容器都附带有自己专属的迭代器,只有容器的设计者才知道如何遍历自己的元素。原生指针(native pointer)也是一种迭代器。
仿函数:行为类似函数,可作为算法的某种策略。从实现角度来看,仿函数是一种重载了operator()的class 或者class template
适配器:一种用来修饰容器或者仿函数或迭代器接口的东西。
空间配置器:负责空间的配置与管理。从实现角度看,配置器是一个实现了动态空间配置、空间管理、空间释放的class tempalte.
STL六大组件的交互关系,容器通过空间配置器取得数据存储空间,算法通过迭代器存储容器中的内容,仿函数可以协助算法完成不同的策略的变化,适配器可以修饰仿函数。
STL容器就是将运用最广泛的一些数据结构实现出来。
常用的数据结构:数组(array) , 链表(list), tree(树),栈(stack), 队列(queue), 集合(set),映射表(map), 根据数据在容器中的排列特性,这些数据分为序列式容器和关联式容器两种。
序列式容器强调值的排序,序列式容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。Vector容器、Deque容器、List容器等。
关联式容器是非线性的树结构,更准确的说是二叉树结构。各元素之间没有严格的物理上的顺序关系,也就是说元素在容器中并没有保存元素置入容器时的逻辑顺序。关联式容器另一个显著特点是:在值中选择一个值作为关键字key,这个关键字对值起到索引的作用,方便查找。Set/multiset容器 Map/multimap容器
| 容器 | 底层数据结构 | 时间复杂度 | 有无序 | 可不可重复 |
|---|---|---|---|---|
| array | 数组 | 随机读改 O(1) | 无序 | 可重复 |
| vector | 数组 | 随机读改、尾部插入、尾部删除 O(1)头部插入、头部删除 O(n) | 无序 | 可重复 |
| deque | 双端队列 | 头尾插入、头尾删除 O(1) | 无序 | 可重复 |
| forward_list | 单向链表 | 插入、删除 O(1) | 无序 | 可重复 |
| list | 双向链表 | 插入、删除 O(1) | 无序 | 可重复 |
| stack | deque / list | 顶部插入、顶部删除 O(1) | 无序 | 可重复 |
| queue | deque / list | 尾部插入、头部删除 O(1) | 无序 | 可重复 |
| priority_queue | vector /max-heap | 插入、删除 O(log2n) | 有序 | 可重复 |
| set | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 不可重复 |
| multiset | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 可重复 |
| map | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 不可重复 |
| multimap | 红黑树 | 插入、删除、查找 O(log2n) | 有序 | 可重复 |
| unordered_set | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 不可重复 |
| unordered_multiset | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 可重复 |
| unordered_map | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 不可重复 |
| unordered_multimap | 哈希表 | 插入、删除、查找 O(1) 最差 O(n) | 无序 | 可重复 |
array 是固定大小的顺序容器,它们保存了一个以严格的线性顺序排列的特定数量的元素。
| 方法 | 说明 |
|---|---|
| begin | 返回指向数组容器中第一个元素的迭代器 |
| end | 返回指向数组容器中最后一个元素之后的理论元素的迭代器 |
| rbegin | 返回指向数组容器中最后一个元素的反向迭代器 |
| rend | 返回一个反向迭代器,指向数组中第一个元素之前的理论元素 |
| cbegin | 返回指向数组容器中第一个元素的常量迭代器(const_iterator) |
| cend | 返回指向数组容器中最后一个元素之后的理论元素的常量迭代器(const_iterator) |
| crbegin | 返回指向数组容器中最后一个元素的常量反向迭代器(const_reverse_iterator) |
| crend | 返回指向数组中第一个元素之前的理论元素的常量反向迭代器(const_reverse_iterator) |
| size | 返回数组容器中元素的数量 |
| max_size | 返回数组容器可容纳的最大元素数 |
| empty | 返回一个布尔值,指示数组容器是否为空 |
| operator[] | 返回容器中第 n(参数)个位置的元素的引用 |
| at | 返回容器中第 n(参数)个位置的元素的引用 |
| front | 返回对容器中第一个元素的引用 |
| back | 返回对容器中最后一个元素的引用 |
| data | 返回指向容器中第一个元素的指针 |
| fill | 用 val(参数)填充数组所有元素 |
| swap | 通过 x(参数)的内容交换数组的内容 |
| get(array) | 形如 std::get<0>(myarray);传入一个数组容器,返回指定位置元素的引用 |
| relational operators (array) | 形如 arrayA > arrayB;依此比较数组每个元素的大小关系 |
vector 是表示可以改变大小的数组的序列容器。
具体函数可参考:https://www.cnblogs.com/john1015/p/12891825.html
deque容器为一个给定类型的元素进行线性处理,像向量一样,它能够快速地随机访问任一个元素,并且能够高效地插入和删除容器的尾部元素。但它又与vector不同,deque支持高效插入和删除容器的头部元素,因此也叫做双端队列。
deque的中控器: deque是由一段一段的定量连续空间构成。一旦有必要在deque的前端或尾端增加新空间,便配置一段定量连续空间,串接在整个deque的头端或尾端。deque的最大任务,便是在这些分段的定量连续空间上,维护其整体连续的假象,并提供随机存取的接口。避开了“重新配置、复制、释放”的轮回,代价则是复杂的迭代器结构。
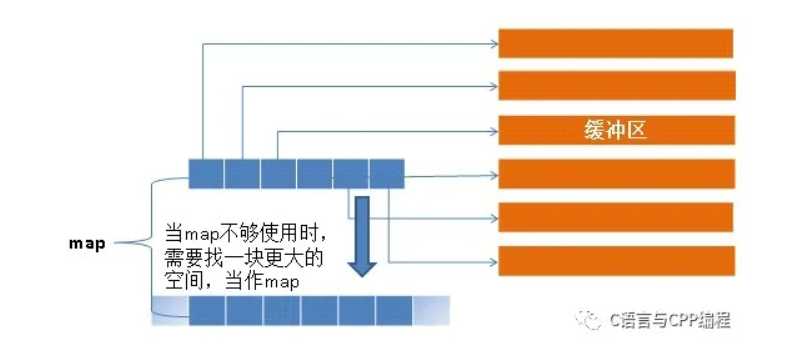
deque采用一块所谓的map(不是STL的map容器)作为主控。
map是一小块连续空间,其中每个元素(此处称为一个节点,node)都是指针,指向另一段(较大的)连续线性空间,称为缓冲区。
缓冲区才是deque的储存空间主体。
1 template<class T, class Alloc = alloc, size_t BufSiz = 0> 2 class deque{ 3 public : 4 typedef T value_type ; 5 typedef value_type* pointer ; 6 ... 7 protected : 8 //元素的指针的指针(pointer of pointer of T) 9 // 其实就是T**,一个二级指针,维护一个二维数组 10 typedef pointer* map_pointer ; 11 12 protected : 13 map_pointer map ; //指向map,map是块连续空间,其内的每个元素 14 //都是一个指针(称为节点),指向一块缓冲区 15 size_type map_size ;//map内可容纳多少指针 16 ... 17 };
map其实是一个T**,也就是说它是一个指针,所指之物也是一个指针,指向型别为T的一块空间。
具体函数参考:https://www.cnblogs.com/john1015/p/13141349.html

list双向链表,是序列容器,允许在序列中的任何地方进行常数时间插入和擦除操作,并在两个方向上进行迭代,可以高效地进行插入删除元素。
list容器的底层实现:
和 array、vector 这些容器迭代器的实现方式不同,由于 list 容器的元素并不是连续存储的,所以该容器迭代器中,必须包含一个可以指向 list 容器的指针,并且该指针还可以借助重载的 *、++、--、==、!= 等运算符,实现迭代器正确的递增、递减、取值等操作。
1 template<tyepname T,...> 2 struct __list_iterator{ 3 __list_node<T>* node; 4 //... 5 //重载 == 运算符 6 bool operator==(const __list_iterator& x){return node == x.node;} 7 //重载 != 运算符 8 bool operator!=(const __list_iterator& x){return node != x.node;} 9 //重载 * 运算符,返回引用类型 10 T* operator *() const {return *(node).myval;} 11 //重载前置 ++ 运算符 12 __list_iterator<T>& operator ++(){ 13 node = (*node).next; 14 return *this; 15 } 16 //重载后置 ++ 运算符 17 __list_iterator<T>& operator ++(int){ 18 __list_iterator<T> tmp = *this; 19 ++(*this); 20 return tmp; 21 } 22 //重载前置 -- 运算符 23 __list_iterator<T>& operator--(){ 24 node = (*node).prev; 25 return *this; 26 } 27 //重载后置 -- 运算符 28 __list_iterator<T> operator--(int){ 29 __list_iterator<T> tmp = *this; 30 --(*this); 31 return tmp; 32 } 33 //... 34 }
在头文件<forward_list>中,与list类似,区别就是list时双链表,forward_list是单链表,forward_list(单向链表)是序列容器,允许在序列中的任何地方进行恒定的时间插入和擦除操作。在链表的任何位置进行插入/删除操作都非常快。

forward_list的特点:
stack没有迭代器,是一种容器适配器,用于在LIFO(后进先出)的操作,其中元素仅从容器的一端插入和提取。

stack底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时.
底层用deque实现:
1 //deque<T> >中间有个空格是为了兼容较老的版本 2 template <class T, class Sequence = deque<T> > 3 class stack { 4 // 以下的 __STL_NULL_TMPL_ARGS 会开展为 <> 5 friend bool operator== __STL_NULL_TMPL_ARGS (const stack&, const stack&); 6 friend bool operator< __STL_NULL_TMPL_ARGS (const stack&, const stack&); 7 public: 8 typedef typename Sequence::value_type value_type; 9 typedef typename Sequence::size_type size_type; 10 typedef typename Sequence::reference reference; 11 typedef typename Sequence::const_reference const_reference; 12 protected: 13 Sequence c; // 底层容器 14 public: 15 // 以下完全利用 Sequence c 的操作,完成 stack 的操作。 16 bool empty() const { return c.empty(); } 17 size_type size() const { return c.size(); } 18 reference top() { return c.back(); } 19 const_reference top() const { return c.back(); } 20 // deque 是两头可进出,stack 是末端进,末端出(所以后进者先出)。 21 void push(const value_type& x) { c.push_back(x); } 22 void pop() { c.pop_back(); } 23 }; 24 25 template <class T, class Sequence> 26 bool operator==(const stack<T, Sequence>& x, const stack<T, Sequence>& y) { 27 return x.c == y.c; 28 } 29 30 template <class T, class Sequence> 31 bool operator<(const stack<T, Sequence>& x, const stack<T, Sequence>& y) { 32 return x.c < y.c; 33 }
底层用list实现:
1 #include<stack> 2 #include<list> 3 #include<algorithm> 4 #include <iostream> 5 using namespace std; 6 7 int main(){ 8 stack<int, list<int>> istack; 9 istack.push(1); 10 istack.push(3); 11 istack.push(5); 12 13 cout << istack.size() << endl; //3 14 cout << istack.top() << endl;//5 15 istack.pop(); 16 cout << istack.top() << endl;//3 17 cout << istack.size() << endl;//2 18 19 system("pause"); 20 return 0; 21 }
queue 是一种容器适配器,用于在FIFO(先入先出)的操作,其中元素插入到容器的一端并从另一端提取。

队列不提供迭代器,不实现遍历操作。
1 template <class T, class Sequence = deque<T> > 2 class queue { 3 friend bool operator== __STL_NULL_TMPL_ARGS (const queue& x, const queue& y); 4 friend bool operator< __STL_NULL_TMPL_ARGS (const queue& x, const queue& y); 5 public: 6 typedef typename Sequence::value_type value_type; 7 typedef typename Sequence::size_type size_type; 8 typedef typename Sequence::reference reference; 9 typedef typename Sequence::const_reference const_reference; 10 protected: 11 Sequence c; 12 public: 13 bool empty() const { return c.empty(); } 14 size_type size() const { return c.size(); } 15 reference front() { return c.front(); } 16 const_reference front() const { return c.front(); } 17 reference back() { return c.back(); } 18 const_reference back() const { return c.back(); } 19 void push(const value_type& x) { c.push_back(x); } 20 void pop() { c.pop_front(); } 21 }; 22 23 template <class T, class Sequence> 24 bool operator==(const queue<T, Sequence>& x, const queue<T, Sequence>& y) { 25 return x.c == y.c; 26 } 27 28 template <class T, class Sequence> 29 bool operator<(const queue<T, Sequence>& x, const queue<T, Sequence>& y) { 30 return x.c < y.c; 31 }
优先队列,其底层是用堆来实现的。在优先队列中,队首元素一定是当前队列中优先级最高的那一个。
集合,set 是按照特定顺序存储唯一元素的容器。
1 template<class _Kty, 2 class _Pr = less<_Kty>, 3 class _Alloc = allocator<_Kty> > 4 class set
multiset允许元素重复而set不允许。
1 template<class _Kty, 2 class _Pr = less<_Kty>, 3 class _Alloc = allocator<_Kty> > 4 class multiset
map 是关联容器,按照特定顺序存储由 key value (键值) 和 mapped value (映射值) 组合形成的元素。
由于 RB-tree 是一种平衡二叉搜索树,自动排序的效果很不错,所以标准的STL map 即以 RB-tree 为底层机制。又由于 map 所开放的各种操作接口,RB-tree 也都提供了,所以几乎所有的 map 操作行为,都只是转调 RB-tree 的操作行为。
| 方法 | 说明 |
|---|---|
| map | 构造函数 |
| begin | 返回引用容器中第一个元素的迭代器 |
| key_comp | 返回容器用于比较键的比较对象的副本 |
| value_comp | 返回可用于比较两个元素的比较对象,以获取第一个元素的键是否在第二个元素之前 |
| find | 在容器中搜索具有等于 k的键的元素,如果找到返回一个迭代器,否则返回 map::end |
| count | 在容器中搜索具有等于 k(参数)的键的元素,并返回匹配的数量 |
| lower_bound | 返回一个非递减序列 [first, last)中的第一个大于等于值 val的位置的迭代器 |
| upper_bound | 返回一个非递减序列 [first, last)中第一个大于 val的位置的迭代器 |
| equal_range | 获取相同元素的范围,返回包含容器中所有具有与 k等价的键的元素的范围边界 |
multimap 的特性以及用法与 map 完全相同,唯一的差别在于它允许键值重复,因此它的插入操作采用的是底层机制 RB-tree 的 insert_equal() 而非 insert_unique。
unordered_set是基于哈希表,因此要了解unordered_set,就必须了解哈希表的机制。哈希表是根据关键码值而进行直接访问的数据结构,通过相应的哈希函数(也称散列函数)处理关键字得到相应的关键码值,关键码值对应着一个特定位置,用该位置来存取相应的信息,这样就能以较快的速度获取关键字的信息。
1 find(beg, end, val); // 返回一个迭代器,指向输入序列中第一个等于 val 的元素,未找到返回 end 2 find_if(beg, end, unaryPred); // 返回一个迭代器,指向第一个满足 unaryPred 的元素,未找到返回 end 3 find_if_not(beg, end, unaryPred); // 返回一个迭代器,指向第一个令 unaryPred 为 false 的元素,未找到返回 end 4 count(beg, end, val); // 返回一个计数器,指出 val 出现了多少次 5 count_if(beg, end, unaryPred); // 统计有多少个元素满足 unaryPred 6 all_of(beg, end, unaryPred); // 返回一个 bool 值,判断是否所有元素都满足 unaryPred 7 any_of(beg, end, unaryPred); // 返回一个 bool 值,判断是否任意(存在)一个元素满足 unaryPred 8 none_of(beg, end, unaryPred); // 返回一个 bool 值,判断是否所有元素都不满足 unaryPred
1 adjacent_find(beg, end); // 返回指向第一对相邻重复元素的迭代器,无相邻元素则返回 end 2 adjacent_find(beg, end, binaryPred); // 返回指向第一对相邻重复元素的迭代器,无相邻元素则返回 end 3 search_n(beg, end, count, val); // 返回一个迭代器,从此位置开始有 count 个相等元素,不存在则返回 end 4 search_n(beg, end, count, val, binaryPred); // 返回一个迭代器,从此位置开始有 count 个相等元素,不存在则返回 end
1 search(beg1, end1, beg2, end2); // 返回第二个输入范围(子序列)在爹一个输入范围中第一次出现的位置,未找到则返回 end1 2 search(beg1, end1, beg2, end2, binaryPred); // 返回第二个输入范围(子序列)在爹一个输入范围中第一次出现的位置,未找到则返回 end1 3 find_first_of(beg1, end1, beg2, end2); // 返回一个迭代器,指向第二个输入范围中任意元素在第一个范围中首次出现的位置,未找到则返回end1 4 find_first_of(beg1, end1, beg2, end2, binaryPred); // 返回一个迭代器,指向第二个输入范围中任意元素在第一个范围中首次出现的位置,未找到则返回end1 5 find_end(beg1, end1, beg2, end2); // 类似 search,但返回的最后一次出现的位置。如果第二个输入范围为空,或者在第一个输入范围为空,或者在第一个输入范围中未找到它,则返回 end1 6 find_end(beg1, end1, beg2, end2, binaryPred); // 类似 search,但返回的最后一次出现的位置。如果第二个输入范围为空,或者在第一个输入范围为空,或者在第一个输入范围中未找到它,则返回 end1
1 for_each(beg, end, unaryOp); // 对输入序列中的每个元素应用可调用对象 unaryOp,unaryOp 的返回值被忽略 2 mismatch(beg1, end1, beg2); // 比较两个序列中的元素。返回一个迭代器的 pair,表示两个序列中第一个不匹配的元素 3 mismatch(beg1, end1, beg2, binaryPred); // 比较两个序列中的元素。返回一个迭代器的 pair,表示两个序列中第一个不匹配的元素 4 equal(beg1, end1, beg2); // 比较每个元素,确定两个序列是否相等。 5 equal(beg1, end1, beg2, binaryPred); // 比较每个元素,确定两个序列是否相等。
1 lower_bound(beg, end, val); // 返回一个非递减序列 [beg, end) 中的第一个大于等于值 val 的位置的迭代器,不存在则返回 end 2 lower_bound(beg, end, val, greater<type>()); // 返回一个非递减序列 [beg, end) 中的第一个小于等于值 val 的位置的迭代器,不存在则返回 end 3 upper_bound(beg, end, val); // 返回一个非递减序列 [beg, end) 中第一个大于 val 的位置的迭代器,不存在则返回 end 4 upper_bound(beg, end, val, greater<type>()); // 返回一个非递减序列 [beg, end) 中第一个小于等于 val 的位置的迭代器,不存在则返回 end 5 equal_range(beg, end, val); // 返回一个 pair,其 first 成员是 lower_bound 返回的迭代器,其 second 成员是 upper_bound 返回的迭代器 6 binary_search(beg, end, val); // 返回一个 bool 值,指出序列中是否包含等于 val 的元素。对于两个值 x 和 y,当 x 不小于 y 且 y 也不小于 x 时,认为它们相等。
1 fill(beg, end, val); // 将 val 赋予每个元素,返回 void 2 fill_n(beg, cnt, val); // 将 val 赋予 cnt 个元素,返回指向写入到输出序列最有一个元素之后位置的迭代器 3 genetate(beg, end, Gen); // 每次调用 Gen() 生成不同的值赋予每个序列,返回 void 4 genetate_n(beg, cnt, Gen); // 每次调用 Gen() 生成不同的值赋予 cnt 个序列,返回指向写入到输出序列最有一个元素之后位置的迭代器
1 copy(beg, end, dest); // 从输入范围将元素拷贝所有元素到 dest 指定定的目的序列 2 copy_if(beg, end, dest, unaryPred); // 从输入范围将元素拷贝满足 unaryPred 的元素到 dest 指定定的目的序列 3 copy_n(beg, n, dest); // 从输入范围将元素拷贝前 n 个元素到 dest 指定定的目的序列 4 move(beg, end, dest); // 对输入序列中的每个元素调用 std::move,将其移动到迭代器 dest 开始始的序列中 5 transform(beg, end, dest, unaryOp); // 调用给定操作(一元操作),并将结果写到dest中 6 transform(beg, end, beg2, dest, binaryOp); // 调用给定操作(二元操作),并将结果写到dest中 7 replace_copy(beg, end, dest, old_val, new_val); // 将每个元素拷贝到 dest,将等于 old_val 的的元素替换为 new_val 8 replace_copy_if(beg, end, dest, unaryPred, new_val); // 将每个元素拷贝到 dest,将满足 unaryPred 的的元素替换为 new_val 9 merge(beg1, end1, beg2, end2, dest); // 两个输入序列必须都是有序的,用小于号运算符将合并后的序列写入到 dest 中 10 merge(beg1, end1, beg2, end2, dest, comp); // 两个输入序列必须都是有序的,使用给定的比较操作(comp)将合并后的序列写入到 dest 中
1 is_partitioned(beg, end, unaryPred); // 如果所有满足谓词 unaryPred 的元素都在不满足 unarypred 的元素之前,则返回 true。若序列为空,也返回 true 2 partition_copy(beg, end, dest1, dest2, unaryPred); // 将满足 unaryPred 的元素拷贝到到 dest1,并将不满足 unaryPred 的元素拷贝到到 dest2。返回一个迭代器 pair,其 first 成员表示拷贝到 dest1 的的元素的末尾,second 表示拷贝到 dest2 的元素的末尾。 3 partitioned_point(beg, end, unaryPred); // 输入序列必须是已经用 unaryPred 划分过的。返回满足 unaryPred 的范围的尾后迭代器。如果返回的迭代器不是 end,则它指向的元素及其后的元素必须都不满足 unaryPred 4 stable_partition(beg, end, unaryPred); // 使用 unaryPred 划分输入序列。满足 unaryPred 的元素放置在序列开始,不满足的元素放在序列尾部。返回一个迭代器,指向最后一个满足 unaryPred 的元素之后的位置如果所有元素都不满足 unaryPred,则返回 beg 5 partition(beg, end, unaryPred); // 使用 unaryPred 划分输入序列。满足 unaryPred 的元素放置在序列开始,不满足的元素放在序列尾部。返回一个迭代器,指向最后一个满足 unaryPred 的元素之后的位置如果所有元素都不满足 unaryPred,则返回 beg
1 sort(beg, end); // 排序整个范围 2 stable_sort(beg, end); // 排序整个范围(稳定排序) 3 sort(beg, end, comp); // 排序整个范围 4 stable_sort(beg, end, comp); // 排序整个范围(稳定排序) 5 is_sorted(beg, end); // 返回一个 bool 值,指出整个输入序列是否有序 6 is_sorted(beg, end, comp); // 返回一个 bool 值,指出整个输入序列是否有序 7 is_sorted_until(beg, end); // 在输入序列中査找最长初始有序子序列,并返回子序列的尾后迭代器 8 is_sorted_until(beg, end, comp); // 在输入序列中査找最长初始有序子序列,并返回子序列的尾后迭代器 9 partial_sort(beg, mid, end); // 排序 mid-beg 个元素。即,如果 mid-beg 等于 42,则此函数将值最小的 42 个元素有序放在序列前 42 个位置 10 partial_sort(beg, mid, end, comp); // 排序 mid-beg 个元素。即,如果 mid-beg 等于 42,则此函数将值最小的 42 个元素有序放在序列前 42 个位置 11 partial_sort_copy(beg, end, destBeg, destEnd); // 排序输入范围中的元素,并将足够多的已排序元素放到 destBeg 和 destEnd 所指示的序列中 12 partial_sort_copy(beg, end, destBeg, destEnd, comp); // 排序输入范围中的元素,并将足够多的已排序元素放到 destBeg 和 destEnd 所指示的序列中 13 nth_element(beg, nth, end); // nth 是一个迭代器,指向输入序列中第 n 大的元素。nth 之前的元素都小于等于它,而之后的元素都大于等于它 14 nth_element(beg, nth, end, comp); // nth 是一个迭代器,指向输入序列中第 n 大的元素。nth 之前的元素都小于等于它,而之后的元素都大于等于它
1 remove(beg, end, val); // 通过用保留的元素覆盖要删除的元素实现删除 ==val 的元素,返回一个指向最后一个删除元素的尾后位置的迭代器 2 remove_if(beg, end, unaryPred); // 通过用保留的元素覆盖要删除的元素实现删除满足 unaryPred 的元素,返回一个指向最后一个删除元素的尾后位置的迭代器 3 remove_copy(beg, end, dest, val); // 通过用保留的元素覆盖要删除的元素实现删除 ==val 的元素,返回一个指向最后一个删除元素的尾后位置的迭代器 4 remove_copy_if(beg, end, dest, unaryPred); // 通过用保留的元素覆盖要删除的元素实现删除满足 unaryPred 的元素,返回一个指向最后一个删除元素的尾后位置的迭代器 5 unique(beg, end); // 通过对覆盖相邻的重复元素(用 == 确定是否相同)实现重排序列。返回一个迭代器,指向不重复元素的尾后位置 6 unique (beg, end, binaryPred); // 通过对覆盖相邻的重复元素(用 binaryPred 确定是否相同)实现重排序列。返回一个迭代器,指向不重复元素的尾后位置 7 unique_copy(beg, end, dest); // 通过对覆盖相邻的重复元素(用 == 确定是否相同)实现重排序列。返回一个迭代器,指向不重复元素的尾后位置 8 unique_copy_if(beg, end, dest, binaryPred); // 通过对覆盖相邻的重复元素(用 binaryPred 确定是否相同)实现重排序列。返回一个迭代器,指向不重复元素的尾后位置 9 rotate(beg, mid, end); // 围绕 mid 指向的元素进行元素转动。元素 mid 成为为首元素,随后是 mid+1 到到 end 之前的元素,再接着是 beg 到 mid 之前的元素。返回一个迭代器,指向原来在 beg 位置的元素 10 rotate_copy(beg, mid, end, dest); // 围绕 mid 指向的元素进行元素转动。元素 mid 成为为首元素,随后是 mid+1 到到 end 之前的元素,再接着是 beg 到 mid 之前的元素。返回一个迭代器,指向原来在 beg 位置的元素
1 reverse(beg, end); // 翻转序列中的元素,返回 void 2 reverse_copy(beg, end, dest);; // 翻转序列中的元素,返回一个迭代器,指向拷贝到目的序列的元素的尾后位置
1 random_shuffle(beg, end); // 混洗输入序列中的元素,返回 void 2 random_shuffle(beg, end, rand); // 混洗输入序列中的元素,rand 接受一个正整数的随机对象,返回 void 3 shuffle(beg, end, Uniform_rand); // 混洗输入序列中的元素,Uniform_rand 必须满足均匀分布随机数生成器的要求,返回 void
1 min(val1, va12); // 返回 val1 和 val2 中的最小值,两个实参的类型必须完全一致。参数和返回类型都是 const的引引用,意味着对象不会被拷贝。下略 2 min(val1, val2, comp); 3 min(init_list); 4 min(init_list, comp); 5 max(val1, val2); 6 max(val1, val2, comp); 7 max(init_list); 8 max(init_list, comp); 9 minmax(val1, val2); // 返回一个 pair,其 first 成员为提供的值中的较小者,second 成员为较大者。下略 10 minmax(vall, val2, comp); 11 minmax(init_list); 12 minmax(init_list, comp); 13 min_element(beg, end); // 返回指向输入序列中最小元素的迭代器 14 min_element(beg, end, comp); // 返回指向输入序列中最小元素的迭代器 15 max_element(beg, end); // 返回指向输入序列中最大元素的迭代器 16 max_element(beg, end, comp); // 返回指向输入序列中最大元素的迭代器 17 minmax_element(beg, end); // 返回一个 pair,其中 first 成员为最小元素,second 成员为最大元素 18 minmax_element(beg, end, comp); // 返回一个 pair,其中 first 成员为最小元素,second 成员为最大元素
1 lexicographical_compare(beg1, end1, beg2, end2); 2 lexicographical_compare(beg1, end1, beg2, end2, comp);
需要根据容器的特点和使用场景而定,可能满足需求的不止一种容器。
按是否有序关联性分为:
注意:deque 容器归为使用连续存储空间的这一类,是存在争议的。因为 deque 容器底层采用一段一段的连续空间存储元素,但是各段存储空间之间并不一定是紧挨着的。
选择容器的几点建议:
原文链接:https://mp.weixin.qq.com/s/W7ix5j9YkevTpIugrdS6Rw
标签:特性 适配器 子序列 谓词 头文件 pointer 重复 顺序存储 none
原文地址:https://www.cnblogs.com/john1015/p/13168813.html