标签:hash cep 垃圾 python 请求 输出 方式 密钥 new
(1)JAVA知识
Q1:List、Set、Map 之间的区别
List 是一个有序并且允许元素重复的集合,它的底层数据结构是数组,数组的优缺点都很明显,就是查询速度很快,但是要做数据移动,比如增加、删除速度就会很慢。
Set 是一个无序且不允许元素重复的集合,它的底层数据结构是哈希表,它的优缺点是跟数组完全相反的,既查询速度慢,但是增加、删速度很快。
Map也是集合的一部分,它最大的特点是key-value形的,并且key不能重复出现,但是value可以重复出现,这对我们某些业务,如用户重复处理能起到重要作用。
Q2:ArrayList 与 LinkedList 的区别?
ArrrayList说白了就是个数组,所以自然也是有数据的优缺点的,比如支持随机访问,查询速度快。而LinkedList 的底层数据结构是链表,所以是不支持随机访问的,在代码中用下标访问一个元素时,ArrayList 的time complexity是 O(1),而 LinkedList 是O(n)。
Q3:Hashtable 与 HashMap 有什么不同之处?
Hashtable 是过时了的遗留下来的类,后面新增的是HashMap。Hashtable 的方法是同步的,所以时间上比较慢,但HashMap 没有同步策略,虽然时间更快了但是也导致它另外一个问题:HashMap是线程不安全的。因为是异步的,在线程并发时可能会导致数据错乱。
Q4:Java 中 ++ 操作符是线程安全的吗?
当然不是线程安全的操作,因为这个过程涉及到多个指令,比如先读取变量值,然后进行增加操作,最后存储回内存,整个过程可能会出现多个线程交差。所以说它不是线程安全的。
Q5:int 和 Integer 哪个会占用更多的内存?
由于Integer 是一个对象,不仅需要存储指向对象的指针,还要存储对象值,所以会占用更多的内存。但是 int 是八种数据类型之一,不需要实例化才能使用,所以占用的空间更少一些。
Q6:Java 中 sleep 方法和 wait 方法的区别?
这两个方法是继承自不同的类的,所以虽然都可以用来暂停当前运行的线程,但sleep() 只是短暂停顿,并不会释放锁,而 wait() 是条件等待,使用了该方法之后,还要释放锁,不然其他等待的线程就不能在满足条件时获取到该锁。而且sleep必须捕获异常的,但wait不需要捕获异常
Q7:解释 Java 堆空间及 GC?
当通过 Java 命令启动 Java 进程的时候,会为它分配内存。内存的一部分用于创建堆空间,当程序中创建对象的时候,就从对空间中分配内存。GC 是 JVM 内部的一个进程,回收无效对象的内存用于将来的分配。
(2)Python知识
Q1:python的八大基本数据类型是?
int、str、float、list、bool、tuple元组、dict字典、set集合
Q2:python中可变数据类型和不可变数据类型有哪些?
不可变数据类型:数值型、字符串string、元组tuple,这类数据类型改变了变量的值相当于是新建了一个对象,也就是如果值是是相同,那么只用一个内存地址保存
可变数据类型:列表list、字典dict:允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化
Q3:python字典和json字符串相互转化方法是?
字典转json使用:json.dumps()
json转字典使用:json.loads()
Q4:Python中@staticmethod和@classmethod的区别
首先说一下什么是普通方法,普通方法需要传递参数,类调用的时默认会将类的实例对象传进去。
@staticmethod装饰的静态方法与普通函数相同:实例和类均可调用,但是不需要传递默认的参数进去
@classmethod装饰的类方法:也需要参数,使用时需要将调用的类传进去
Q5:什么是装饰器?
装饰器的本质是一个闭包函数,实现的功能是在不修改原函数及调用方式的情况下对原函数进行功能扩展的,是开放封闭原则的典型代表,我们在业务中有编程场景可以用上装饰器,比如用户登陆后的权限校验、执行函数前的预备处理、执行后的功能清理、以及更高级的事务处理等等。
Q6:python中常见的异常举例
Exception 所有异常类的基类
AssertionError assert语句失败
FileNotfoundError 文件打开失败
AttributeError 试图访问对象没有属性
Q7:Python是如何进行内存管理的?
Python一个高效语言的原因之一是因为它有非常完善的内存管理机制,在python中万物皆对象,所以围绕对象的内存管理是整个的核心。第一:对象的引用计数机制,python是使用引用计数来保持追踪内存中的对象。第二:垃圾回收机制,当一个对象的引用计数归零时,它将被垃圾收集机制处理掉,保证对象可回收。第三:内存池机,Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统制
(3)数据库知识
Q1:数据表project有code字段,其中code中的编码名有重复,如何消除重复行?
select distinct code from project
Q2:什么是内链接、左链接、右链接、全链接?
(1)INNER JOIN产生的结果集中,是左和右的交集
(2)LEFT JOIN返回左表的全部行和右表满足ON条件的行,其他null替代
(3)RIGHT JOIN返回右表的全部行和左表满足ON条件的行,其他null替代
(4)FULL JOIN 会从左表 和右表 那里返回所有的行,如果其中一个表的数据行在另一个表中没有匹配的行,那么对面的数据用NULL代替。这个问题基本是问数据库问题必问的,大家还可以深入准备下哪些业务场景用到哪种链接。
Q3:某个字段被建立索引后,数据的什么操作会使用到该索引?
(1)对建立了索引的字段做where条件查询时
(2)多表做join操作时会使用索引
(3)对建立了索引的字段做min()或max()时
(4)对建立了索引的字段做sort排序操作时
其中我们用索引最多的时候在查询场景,但同时索引查询也会增加内存消耗,所以索引查询该如何优化是一个更大的问题,此类问题也是数据库常见面试题之一,有兴趣的小伙伴可以自行查阅资料。
(4)http知识
Q1:http协议是不是安全的?如果不是,如何确保传输安全?
HTTP的连接很简单,是无状态的,所以不安全,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,是HTTP的安全版。(SSL协议的对称密钥加密、非对称密钥加密Google查资料)
Q2: 简述cookie和session的区别
session 在服务器端,而cookie 在客户端(浏览器)
cookie 由于是放在客户端的,存在不安全性,容易被黑客利用
session 放在服务端的,安全相对较高,但是如果网站访问量较大的时候,session的存储机制会占用服务器较多内存,所以同时需要考虑性能优化的问题
Q3: 什么是socket?
网络中的进程一般是通过socket通信的,socket是在应用层和TCP/IP协议通信之间的抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口,供应用层调用以实现进程在网络中通信,socket函数的本质是操作文件,如读写I/O、打开进程、关闭进程。
(5)Git 知识
Q1: git pull和git fetch之间有什么区别?
简单来说,git pull 是 git fetch + git merge。
1.git pull 会拉取所有的提交并且合并到当前处理的分支中,如果没有细心管理分支,可能会频繁遇到冲突。
2.git fetch 会拉取目标分支中所有本地不存在的提交,将这些远程提交存储到本地仓库中,但不会把这些提交合并到当前分支中,如果跟小伙伴的代码存在较大可能心时,建议先用git fetch拉取代码,后用 git merge合并代码
Q2: git如何进行版本回退
git reset --hard HEAD^
Q3: gitlab如何进行分支保护和代码审查
Gitlab是部署在自己服务器的一套git代码版本管理系统,部署完毕后让自己的成员在该网址上注册好账号,管理员建立对应的项目组并且拉相关成员进组,需要给对应的成员设置好角色,因为角色不同决定了对整个项目的操作权限不同。代码分支管理在设置中的Protected Branches,在Allowed to merge下选择对应角色的成员既有权利管理master分支,并且在其他成员将自己分支合并到master分支之前做好代码审查工作。
四、测试开发面试题
Q1: 接口测试如例如何设计
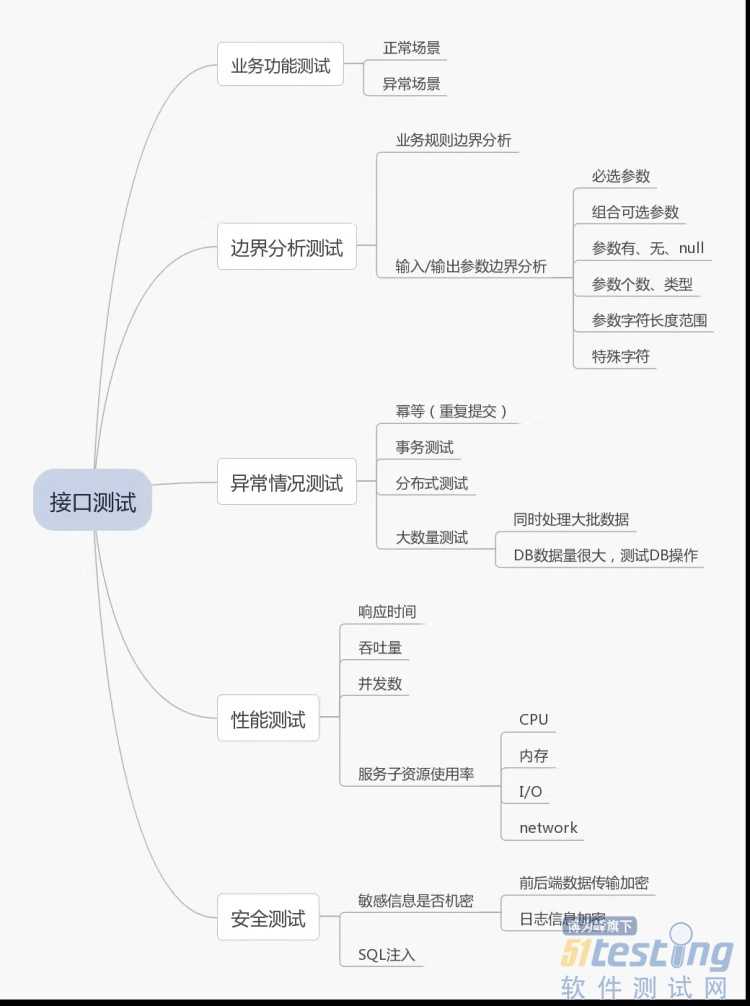
Q2: 自动化框架的搭建思路,分别有什么模块,作用是什么?
用例模块、发送请求、全局配置文件、数据自动采集、读取数据、接口断言、日志记录、测试报告
Q3: 测试数据有几种,分别放哪里?
全局数据:写入配置文件 一次性消耗数据:从随机函数生成 需要被接口多次读取数据:参数化,放入excel、json、或者从数据库读取 接口数据文件:数据驱动、使用excel管理测试接口
Q4: 影响数据流的接口如何处理,比如删除这种接口如何测试
方法一:最后单独处理这个接口,单独造独立的数据去删除,丰富数据
方法二:连接到数据库中操作
Q5: 测试脚本数据如何规划设计
V1.0:跑通一个流程的接口(约10个),常量数据脚本
V2.0:跑通一个流程的接口(约10个),数据参数化,数据与脚本分离
V3.0:跑通所有接口,数据参数化,数据与脚本分离
V4.0:多组有效数据,保证所有接口能全部跑通且提高覆盖率
V5.0:多组无效数据,加强测试覆盖率
Q6: 使用什么框架完成自动化?讲述使用过程
unittest、pytest、postman、jmeter、Selenium、Appnium等
Q7: unittest、pytest框架对比
pytest 相较于 unittest 最为跳跃的一点应该就是 fixture 机制。对于unittest来说,每个用例的类中都需要去写入setUp和tearDown。也就是我们所说的前置和后置,而不可避免的,很多用例的前置和后置都是一样,重复的复制粘贴致工作量增加,代码量也增加。
Q8:pytest的@pytest.mark.parametrize 装饰器作用是什么?
@pytest.mark.parametrize 装饰器可以让我们每次参数化fixture的时候传入多个项目。回忆上一节,我们参数化的时候只能传入1个字符串或者是其他的数据对象,parametrize每次多个参数,更加灵活。
Q9:postman + Newman相关问题
是否会使用postman完成接口的基本调试?
变量有几种,作用域分别是什么?
如何使用变量?
sandbox如何使用,如何实现断言
如何实现接口参数化,以及接口传递
Newman的作用是什么,如何使用
如何输出html格式的测试报告
Newman是否可以改造
Q10:selenium常用的八大定位法
Id、name、link_text、partial_link_text、tag_name、class_name、css_selector、xpath
Q11:GUI测试如何提高脚本的稳定性
不要右键复制xpath(十万八千里那种路径,肯定不稳定),自己写相对路径,多用name定位,sleep等待尽量少用(影响执行时间)、使用WebDriverWait,结合WebDriverWait和expected_conditions判断元素方法,自己封装一套定位元素方法
五、扩展问题
Q1: 安全测试有哪些方面?
XSS、CSRF攻击、SQL注入攻击、web木马攻击、文件上传攻击、账密暴力破解、验证码缺陷、用户权限、端口扫描、服务检测、中间件安全。对这块有要求的小伙伴找本书看看,推荐《web安全防护指南基础篇》
Q2: 简述性能测试、负载测试、压力测试
性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。
负载测试- 核实在保持配置不变的情况下,测试对象在不同操作条件(如不同用户数、事务数等)下性能行为的可接受性
压力测试:压力测试主要是为了测试硬件系统是否达到需求文档设计的性能目标,譬如在一定时期内,系统的cpu利用率,内存使用率,磁盘I/O吞吐率,网络吞吐量等,压力测试和负载测试最大的差别在于测试目的不同。
Q3: 常用的性能指标的名称与具体含义。
响应时间、并发用户数,吞吐量,性能计数器,TPS,HPS
标签:hash cep 垃圾 python 请求 输出 方式 密钥 new
原文地址:https://www.cnblogs.com/xidianlxf/p/13168882.html