标签:信息 体验 出现 tensor 高达 定义 rap 细节 dict
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
Accelerating Medical Image Segmentation with NVIDIA Tensor Cores and TensorFlow 2
医学图像分割是当前学术界研究的热点。这方面正在进行的挑战、竞赛和研究项目的数量证明了这一点,这些项目的数量只是逐年上升。在解决这一问题的各种方法中,U-Net已经成为许多2D和3D分割任务的最佳解决方案的骨干。这是因为简单性、多功能性和有效性。
当实践者面临一个新的分割任务时,第一步通常是使用现有的U-Net实现作为主干。但是,随着TensorFlow 2.0的到来,缺少现成的解决方案。如何有效地将模型转换到TensorFlow 2.0以利用新功能,同时仍然保持顶级硬件性能并确保最先进的精度?
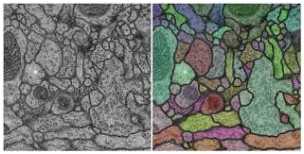
Figure 1. Example of a serial section Transmission Electron Microscopy image (ssTEM) and its corresponding segmentation
U-Net首先由Olaf Ronneberger、Philip Fischer和Thomas Brox引入。在本文中,U-Net:用于生物医学图像分割的卷积网络。U-Net允许以高精度和高性能无缝分割2D图像。可以用来解决许多不同的分割问题。
图2显示了U-Net模型及其不同组件的构造。U-Net由一条压缩和一条扩展路径组成,其目的是通过卷积和池操作的结合,在其最核心的部分建立一个瓶颈。在这个瓶颈之后,通过卷积和上采样相结合的方法重建图像。跳跃连接的目的是帮助梯度的反向流动,以改善训练。
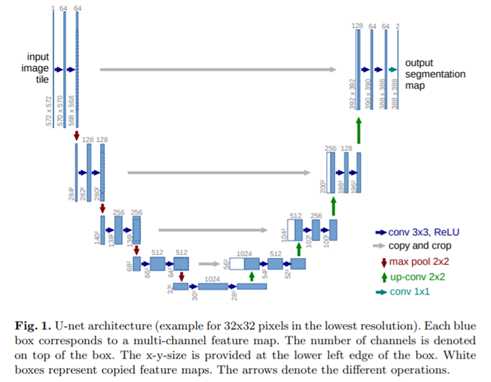
Figure 2. The architecture of a U-Net model. Source: U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net擅长的任务通常被称为语义分割,需要用对应的类来标记图像中的每个像素,以反映所表示的内容。因为对图像中的每个像素都执行此操作,所以此任务通常称为密集预测。
在语义分割的情况下,预测的预期结果是高分辨率图像,通常与被馈送到网络的图像具有相同的维度,其中每个像素被标记到相应的类。广义地说,语义分割只是一种像素级、多类分类的形式。
尽管U-Net主要用于语义分割,但基于U-Net的网络在目标检测或实例分割等任务中取得很好的效果并不少见。
通常,使用深度学习模型的第一步是建立一个让感到舒适的基线。在NVIDIA深度学习示例Github存储库中,可以找到最流行的深度学习模型的实现。这些实现几乎涵盖了每个领域和框架,并提供了广泛的基准,以确保最佳的准确性和性能。因此,无论是从业者还是研究者,都是最佳起点。
在这些实现中,可以找到U-Net,可以在TensorFlow 1.x和TensorFlow 2.0中找到。但是,迁移到TensorFlow的最新版本需要遵循哪些步骤?
A new way to run models
在这个新版本的TensorFlow中,最显著的变化之一是在使用会话到函数调用之间的切换。到目前为止,将指定要调用的输入和函数,并期望返回模型的输出。然后在会话.run调用,如下代码示例所示:
TensorFlow 1.X
outputs = session.run(f(placeholder), feed_dict={placeholder: input})
TensorFlow 2.0
outputs = f(input)
这是可能的,因为TensorFlow 2.0中默认启用了紧急执行。这改变了与TensorFlow交互的方式,因为紧急执行是一个立即评估操作的命令式编程环境。提供了一些好处,例如更直观的界面、更容易调试、自然的控制流,但代价是性能较差。通常被推荐用于研究和实验。
AutoGraph
要在使用TensorFlow 2.0的模型中实现生产级性能,必须使用AutoGraph(AG)。这个Tensorflow 2.0特性允许通过使用decorator使用自然的Python语法编写Tensorflow图形代码@tf.函数,如下代码示例所示:
@tf.function
def train_step(features, targets, optimizer):
With tf.GradientTape() as tape:
predictions = model(features)
loss = loss_fn(predictions, targets)
vars = model.trainable_variables
gradients = tape.gradient(loss, vars)
optimizer = apply_gradients(zip(gradients, vars))
尽管AG仍有局限性,但带来的性能改进是显而易见的。有关如何使用tf.函数和AG,参见TensorFlow 2.0指南。
混合精度是不同数值精度在计算方法中的综合运用。混合精度训练通过以半精度格式执行操作,同时以单精度存储最小信息以在网络的关键部分保留尽可能多的信息,从而显著加快计算速度。
在Volta和Turing体系结构中引入张量核之后,可以通过切换到混合精度来体验显著的训练加速:在最严格的数学模型体系结构上,总体加速高达3倍。使用混合精度训练需要两个步骤:
1. Porting the model to use the FP16 data type where appropriate.
2. Adding loss scaling to preserve small gradient values.
For more information, see the following resources:
要在TensorFlow 2.0中启用自动混合精度(AMP),必须对代码应用以下更改。
设置Keras混合精度策略:
tf.keras.mixed_precision.experimental.set_policy(‘mixed_float16‘)
在优化器上使用损失缩放包装器。默认情况下,可以选择动态损耗缩放:
optimizer = tf.keras.mixed_precision.experimental.LossScaleOptimizer(optimizer, "dynamic")
确保使用缩放损失计算梯度:
loss = loss_fn(predictions, targets)scaled_loss = optimizer.get_scaled_loss(loss)
vars = model.trainable_variables
scaled_gradients = tape.gradient(scaled_loss, vars)
gradients = optimizer.get_unscaled_gradients(scaled_gradients)
optimizer.apply_gradients(zip(gradients, vars))
加速线性代数(XLA)是一种特定于领域的线性代数编译器,可以加速TensorFlow模型,而不必更改源代码。其结果是速度和内存使用的提高:在启用XLA之后,大多数内部基准测试的运行速度提高了1.1-1.5倍。
要启用XLA,请在优化器中设置实时(JIT)图形编译。可以通过对代码进行以下更改来完成此操作:
tf.config.optimizer.set_jit(True)
在NVIDIA深度学习示例GitHub存储库中,可以找到使用TensorFlow 2.0的U-Net实现。这个实现包含了所有必要的部分,不仅可以将U-Net移植到新版本的Google框架中,还可以使用
tf.estimator.Estimator.
除了前面描述的与模型性能相关的必要更改外,请遵循以下步骤以确保模型完全符合新API:
由于TensorFlow 2.0中的许多API操作已被删除或已更改位置,第一步是使用v2升级脚本将不推荐的调用替换为新的等效调用:
tf_upgrade_v2 \
--intree unet_tf1/ \
--outtree unet_tf2/ \
--reportfile report.txt
尽管此转换脚本自动化了大部分过程,但根据报告文件中捕获的建议,仍需要手动进行一些更改。有关更多信息,TensorFlow提供了以下指南,自动将代码升级到TensorFlow 2。
数据加载
用于训练模型的数据管道与用于TensorFlow 1.x实现的数据管道相同。是使用tf.data.Dataset数据集API操作。数据管道加载图像并使用不同的数据增强技术对其进行转换。有关详细信息,请参见data_loader.py脚本。
模型定义
这个新版本的TensorFlow鼓励将代码重构成更小的函数并模块化不同的组件。其中之一是模型定义,现在可以通过子类化来执行tf.keras.Model型:
class Unet(tf.keras.Model): """ U-Net: Convolutional Networks for Biomedical Image Segmentation
Source:
https://arxiv.org/pdf/1505.04597
"""
def __init__(self):
super().__init__(self)
self.input_block = InputBlock(filters=64)
self.bottleneck = BottleneckBlock(1024)
self.output_block = OutputBlock(filters=64, n_classes=2)
self.down_blocks = [DownsampleBlock(filters, idx)
for idx, filters in enumerate([128, 256, 512])]
self.up_blocks = [UpsampleBlock(filters, idx)
for idx, filters in enumerate([512, 256, 128])]
def call(self, x, training=True):
skip_connections = []
out, residual = self.input_block(x)
skip_connections.append(residual)
for down_block in self.down_blocks:
out, residual = down_block(out)
skip_connections.append(residual)
out = self.bottleneck(out, training)
for up_block in self.up_blocks:
out = up_block(out, skip_connections.pop())
out = self.output_block(out, skip_connections.pop())
return tf.keras.activations.softmax(out, axis=-1)
根据上述更改,运行模型以验证TensorFlow2.0上Tensor Cores提供的加速。有三种不同的特性影响性能:
结果是通过ensorflow:20.02-tf-py3下一代NVIDIA DGX-1上带有(8x V100 16G)GPU的容器。性能数字(以每秒项/图像为单位)在1000次迭代中平均,不包括前200个预热步骤。

Table 1. Single- and multi-GPU training performance for FP32 and mixed precision. The speedup is the ratio of images per second processed in mixed precision compared to FP32.
在TensorFlow 2.0中,对于单GPU训练,使用混合精度的例子模型能够达到每秒图像测量的2.89x加速比;对于多GPU训练,使用混合精度的例子模型能够达到每秒图像测量的2.7x加速比,使用混合精度的例子模型能够达到几乎完美的弱比例因子。有关更多信息,请参阅遵循的步骤。
对TensorFlow2.0中可用的不同特性如何影响训练阶段性能的额外了解。提高模型吞吐量的最有效方法是启用AMP,包括此功能在内的所有设置都是性能最好的。但是,当使用混合精度进行训练时,XLA只有在使用AG时才能提供提升。AMP、XLA和AG的组合提供了最佳的结果。
通过运行tensorflow:20.02-tf-py3下一代NVIDIA DGX-1上的容器,带有(1x V100 16G)GPU。吞吐量以每秒图像帧为单位报告。每批报告的延迟时间以毫秒为单位。

表2. FP32和混合精度的单GPU推理性能。加速比是每秒以混合精度处理的图像与FP32的比率。
该模型在TensorFlow 2.0推理机上使用混合精度,可达到3.19x的加速比。有关更多信息,请参阅推理性能基准测试步骤。
TensorFlow2.0中可用的不同特性如何影响推理阶段性能的额外细节。最重要的性能提升出现在启用放大器时,因为张量核大大加速了预测。因为模型已经过训练,所以可以通过启用AG来禁用急切执行,这将提供额外的增强。
可以使用NVIDIA gpu开始利用TensorFlow 2.0中的新功能。TensorFlow2.0极大地简化了模型的训练过程,并且在最新版本的框架中比以往任何时候都更容易利用Tensor核心。
在Deep Learning Examples存储库中,将找到25个以上最流行的Deep Learning模型的开源实现。有TensorFlow、Pythorch和MXNet。在这些例子中,是关于如何以最先进的精度和破纪录的性能运行这些模型的逐步指南。
所有实现都附带了有关如何执行混合精度训练以使用张量核加速模型的说明。还以检查点的形式分发这些模型。这些模型是完全维护的,包括最新的功能,如多GPU训练、使用DALI加载数据和TensorRT部署。
用NVIDIA Tensor Cores和TensorFlow 2加速医学图像分割
标签:信息 体验 出现 tensor 高达 定义 rap 细节 dict
原文地址:https://www.cnblogs.com/wujianming-110117/p/13169888.html