标签:解决 net ESS csu cli 不同的 VID lam card
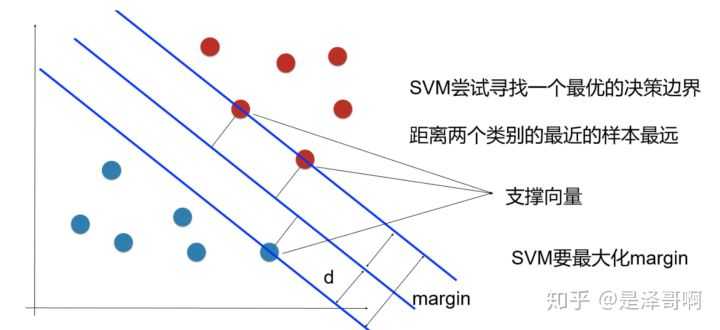
SVM是二分类模型,在特征空间需要间隔最大化。可形式化为一个求解凸二次规划问题。
1、可以有效解决高维特征的分类和回归问题
2、无需依赖全体样本,只依赖支持向量
3、有大量的核技巧可以使用,从而可以应对线性不可分
4、样本量中等偏小照样有较好的效果
1、如果特征维度远大于样本个数,SVM表现一般
2、SVM在样本巨大且使用核函数时计算量很大
3、非线性数据的核函数选择依旧没有标准
4、SVM对缺失数据敏感
5、特征的多样性导致很少使用svm,因为 svm 本质上是属于一个几何模型,这个模型需要去定义 instance 之间的 kernel 或者 similarity(线性svm中的内积),而我们无法预先设定一个很好的similarity。这样的数学模型使得 svm 更适合去处理 “同性质”的特征
SVM中没有特定的处理缺失值的方法。而在SVM中又希望样本在样本空间中线性可分,所以特征空间的好坏对SVM的性能很重要。
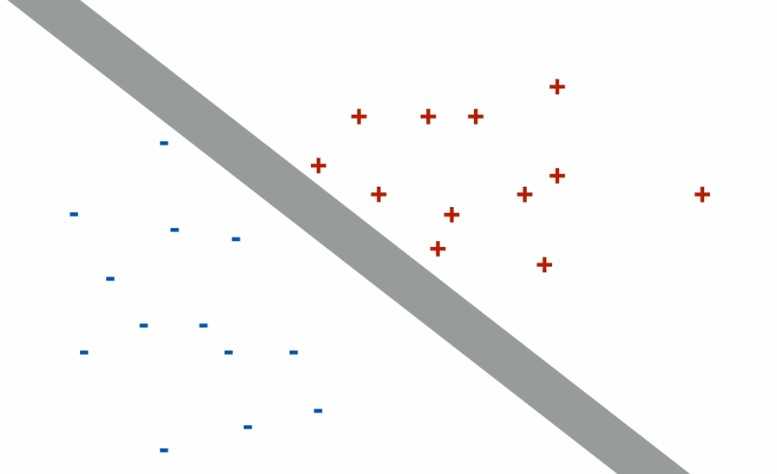
在二维空间上,两类点被一条直线完全分来叫做线性可分。
为了使得这个超平面更具有鲁棒性,我们回去寻找最佳超平面,以最大间隔把两类样本分开的超平面,也被称为最大间隔超平面,硬间隔最大化==硬性规定,间隔之间没有点

参考
一个点到不同超平面的距离得用几何距离
不同的点到同一个超平面的距离,用函数距离

用途:二次规划问题,问题规模与训练样本数成正比时
SMO,是序列最小优化算法,每次优化一个参数,其他参数先固定不变,仅求当前这个优化参数的极值
SMO每次优化一个参数,但我们优化的约束条件是
,没法一个只变动一个参数,所以我们选择两个参数
https://blog.csdn.net/fendegao/article/details/79968994


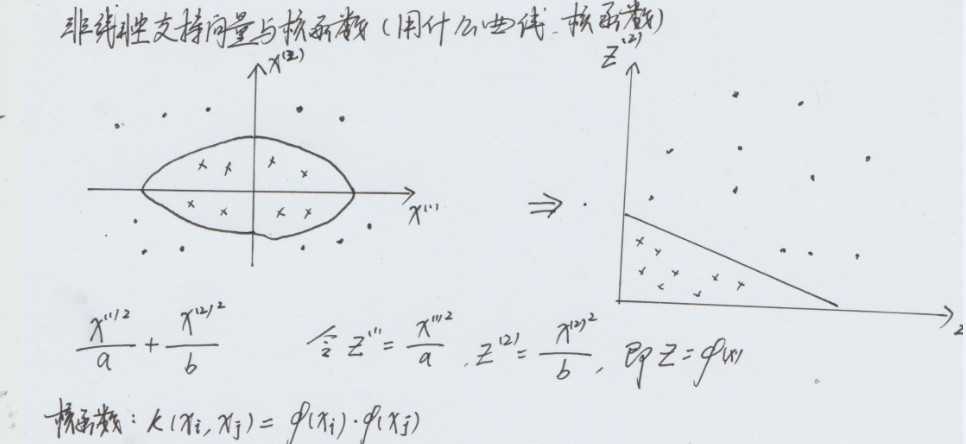
核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
核函数本质不是将特征映射到高维空间,而是找到一种直接在低位空间对高维空间中向量做点积运算的简便方法。
线性内核是最简单的内核函数。 它由内积<x,y>加上可选的常数c给出。 使用线性内核的内核算法通常等于它们的非内核对应物,即具有线性内核的KPCA与标准PCA相同。
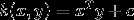
将原始空间映射到无穷维空间。

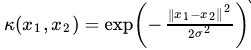
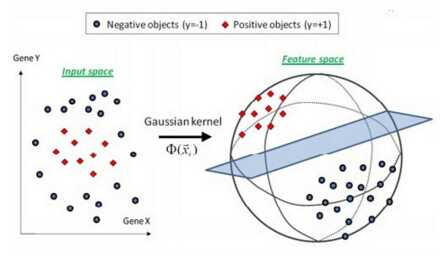
指数核与高斯核密切相关,只有正态的平方被忽略。 它也是一个径向基函数内核
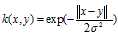
参考2**
标签:解决 net ESS csu cli 不同的 VID lam card
原文地址:https://www.cnblogs.com/Towerb/p/13172398.html