标签:训练 array display 调整 规模 版本 适应 结构 硬币
Dropout是指在深度网络的训练中, 以一定的概率随机地 “临时丢弃”一部分神经元节点。
应用dropout之后前向传播过程变为:
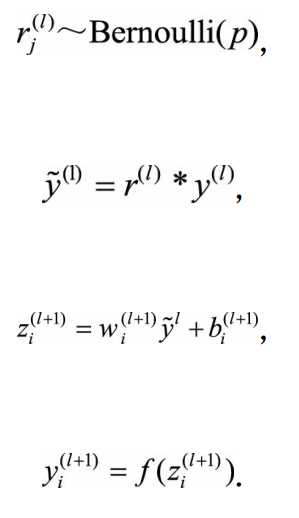
经过一个p值的伯努利分布,乘以上一层的输出,之后前向传播,值为0的BP时不计算梯度。
dropout是带有随机性的,如果测试也做的话,网络的输出就不稳定了。所以测试阶段是没有dropout的。
测试阶段是前向传播的过程。 在前向传播的计算时, 每个神经元的参数要预先乘以概率系数p, 以恢复在训练中该神经元只有p的概率被用于整个神经网络的前向传播计算。
https://zhuanlan.zhihu.com/p/38200980
https://zhuanlan.zhihu.com/p/38200980
# coding:utf-8 import numpy as np # dropout函数的实现 def dropout(x, level): if level < 0. or level >= 1: #level是概率值,必须在0~1之间 raise ValueError(‘Dropout level must be in interval [0, 1[.‘) retain_prob = 1. - level # 我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样 # 硬币 正面的概率为p,n表示每个神经元试验的次数 # 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。 random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了 print(random_tensor) x *= random_tensor print(x) x /= retain_prob return x #对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果 x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32) dropout(x,0.4) # [0 1 1 0 1 1 1 1 1 0] [0. 2. 3. 0. 5. 6. 7. 8. 9. 0.]
[ 1.6666666 0. 0. 0. 8.333333 10.
11.666666 13.333333 0. 0. ]#放大后
但是我们可以看到有一句这么的操作: x /= retain_prob,对失活后又进行了scale,*了1/(1-p),其中这里的p表示的是失活率。
https://www.zhihu.com/question/61751133,进行了解释。

这里的p指的是1-失活率。因为训练的时候经过了*p的操作,而如果测试的时候不做改变,那么测试的输出就是训练时候的1/p倍,那么如果在训练的时候在dropout之后,就*1/p之后,预测的时候就不必做操作了。总的来说是为了保持输出期望不变,输出就会比较稳定。这就是Inverted Dropout。
朴素vanilla 版本:训练时候因为随机扔掉了一些节点,总期望变小,那么预测时候就全体缩小一点来保持一致。存在的问题:预测过程需要跟着 dropout 策略做调整,哪些层取消了、加重了或者减轻了,都需要改。一不小心就会出错。

标签:训练 array display 调整 规模 版本 适应 结构 硬币
原文地址:https://www.cnblogs.com/BlueBlueSea/p/13174452.html