标签:目的 要求 不可 原子操作 progress 读写 访问 区别 图片
知乎用户
ljgibbs授权转发
本系列我想深入探寻 AXI4 总线。不过事情总是这样,不能我说想深入就深入。当前我对 AXI总线的理解尚谈不上深入。但我希望通过一系列文章,让读者能和我一起深入探寻 AXI4。
声明1:部分时序图以及部分语句来自 ARM AMBA 官方手册
(有的时候感觉手册写得太好了,忍不住就直接翻译了。。)
声明2:AXI 总线是 ARM 公司的知识产权

备注:
下载手册可以到ARM官网搜AMBA ,需要注册 ARM 账号。官方手册developer.arm.com
百度文库应该有中文翻译版本。
AXI 协议中定义了一组信号表示读写传输事务的类型,分别为 ARCACHE 以及 AWCACHE,合称为 AXCACHE。两者控制了
AXI 协议中存在两类主机:存储从机(Memory Slave)与外设从机(Peripheral Slave)。
我们协议中传输事务属性主要是为存储从机准备的礼物,存储从机必须支持所有的事务属性信号。
而对于外设从机,支持哪些属性信号,就看着办了,协议只有一个要求:外设从机必须完成整个传输事务,哪怕存在其不支持的某个事务属性信号。
外设从机对于属性信号的支持以及相应的访问方式(method of access)由具体实现决定(IMPLEMENTATION DEFINED),一般设计者会将支持的方式列于该从机的规格书中,从机也只对所支持访问方式进行正确响应。
极端情况下,从机接收到一个不支持的访问方式,然后 GG (比如崩溃)了,这是可以的。但是一定一定要完成这次的传输事务后再 GG,以防止整个系统死锁。
协议也不要求从机支持复活机制。(continued correct operation is not required)
系统级缓存
注意:AXI 协议缓存相关机制是针对处理器的系统级缓存的一种实现。
所谓系统级缓存(system level cache)区别于处理器内部的缓存,系统级缓存提高整个系统访问外部存储的速度。当系统级缓存连接在处理器核与外部存储之间时,可以被看做处理器核外部的 L2 缓存,如下图所示
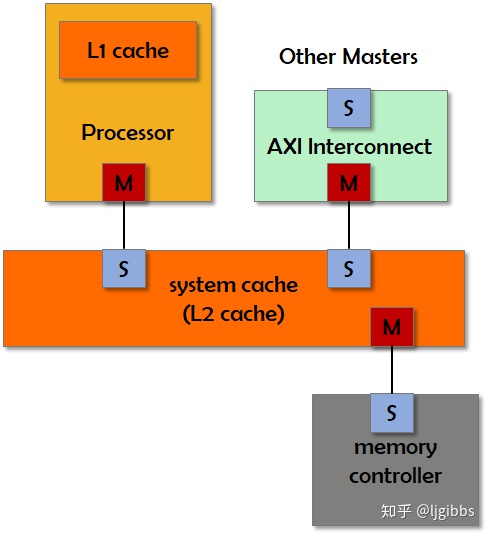
处理器核、系统缓存以及外部存储控制器通过 AXI 总线接口互联。L1 缓存位于处理器核内部。当处理器访问外部存储中的数据,在 L1 缓存中缺失时,向外部缓存发起传输事务。传输事务在通过系统缓存时,如果该事务命中缓存表项,即可直接得到结果,避免访问外部存储带来的缺失代价。
这里的 system cache 概念与拓扑见参考文献[1],来自 Xilinx system cache IP 手册
存储相关信号主要涉及到缓存(cache)的相关知识,本节的叙述已经假定读者了解存储,尤其是缓存相关的基础知识,比如以下几点。
什么是缓存?为什么缓存能够加速存储的读写?
然后是经典的缓存四问,来自阅读材料(C):
如果你不能很好地答上这些问题,不慌,笔者有一个三步阅读套餐给你。
(A)很棒的知乎科普读物,建议基本读完所有文字
(B)教科书,推荐《计算机组成与设计 硬件/软件接口》(第五版)第五章
(C)经典书籍,《计算机体系结构 量化研究方法》(第五版)附录B
其实读完(A),我们就接着往下看吧,毕竟这不是与缓存紧密相关的 ACE 协议(ACE 后面再学习),不建议啥也不读就往下看。
AXI4 的存储属性信号以 AXI3 作为基础,并做了一些改进。协议先叙述的 AXI3,再讨论 AXI4 的改进。那么本文则直接讨论 AXI4 了。
AxCACHE 信号共有 4 比特,每个比特代表不同的含义。首先是 AxCACHE[0] 信号,代表 Bufferable。
Bufferable
当 AxCACHE[0] 置高时,表示该传输事务在传输至目的地的途中,可以被 interconnect 或者任意的 AXI 组件缓存,延迟若干个周期。一般应用于写传输事务。
协议上言尽于此,本文根据 cache 机制展开引申。
值得注意的是,笔者为此问题在网上冲浪了很久,并没有一个针对 AXI Bufferable 本身的明确解释,这里的描述可能不一定完全正确。
CPU 在特定的写入策略下,本来在写传输事务中需要写入至主存储(main memory)的数据,可以先缓存于 cache 中,等待被替换时再真正写入主存储。
因此 CPU 在写入 cache 后就认为写操作完成。写事务原先的目的地是主存储,比如外部 DDR,理论上应该由 DDR 控制器在 “真的” 写入数据到 DDR 后,向 CPU 发出写回复信号,表示写传输事务完成。但是现在数据写入 cache后,即向 CPU 发出了写回复信号结束了本次写回复。
当 AxCACHE[0] 置低时,这种特性即不被允许,那什么情况下不允许缓存?参考文献[2]中的网页中举了一个例子,当 CPU 使用 DMA 将数据传输至 IO 设备时,数据首先被写入 DMA 在内存中开辟的缓冲区。此时 CPU 需要掌握什么时候数据“真的”被完全写入缓冲区,因为需要确保数据存入后,再启动 DMA 传输。
我们接着引申,假设数据已经被缓存在中间组件中了,如果相邻的缓存事务中的数据正好要被写入相邻的地址(换句话说在一个 cache line 中),那么如果能把不同数据聚合起来,这样一来岂不是能减少写入数据的次数,减少对总线的占用?这就涉及到 AxCACHE[1] Modifiable 信号
Modifiable
当 AxCACHE[1] 置高时,表示传输过程中,该写传输事务的传输特性可以改变。
协议列举了一些传输事务改变的情形:
上述几种情况中,几项信号可以发生改变(Modify):
此外,AxID、AxQOS 等信号也是可以改变的,AxID 的改变常见于 interconnect 的输出。
AxCACHE 信号本身也是可以改变的,但有一些特别的限制。对于存储属性信号的修改必须保证传输事务对于 AXI 组件的可见性不减小,不能改变传输事务本身的传播路径,也不能改变事务对于缓存的查找需求。此外,对于传输事务存储属性的修改需要作用于整个地址范围中的事务。
协议规定 AxLOCK、AxPROT 信号是不可改变的。此外两种情况下,传输事务的信号不能改变:
当 AxCACHE[1] 置低时,表示传输过程中,该写传输事务的传输特性不可以改变。
下图中的信号不可改变,此外比如 ID 和 QoS 信号还是可以改变的。比如前者在多机通信场景中,通过 interconnect 后会改变,与其存储属性无关。

AxCACHE 信号可以改变,但只能从 bufferable 修改为 non-bufferable。
cache-allocate
对于读写事务,AxCACHE 中的高 2 比特,用于表示本次传输事务所访问地址中的数据是否可能在缓存中, 2 比特分别表示:
对于读事务 2 比特分别表示:
当 2 比特为 2‘b00 时,表示 CPU 指示该传输事务无需至 cache 中查找,必须直接从主存储中读取或者写入主存储。
当 2 比特不为 2‘b00 时,先前的读写事务可能已经将该地址缓存与 cache 中,所以该传输事务必须首先在 cache 中查找,缺失的情况下再访问主存储。
这里说可能是因为,尽管 CPU 根据指令顺序认为该数据已缓冲,但由于指令乱序、数据实际未就绪等原因,实际的存储情况可能与 CPU 记录的情况不同,由缓存控制器具体判断。
我们具体地分别来看下读写事务中的 AxCACHE[3:0] 信号,首先是写事务。
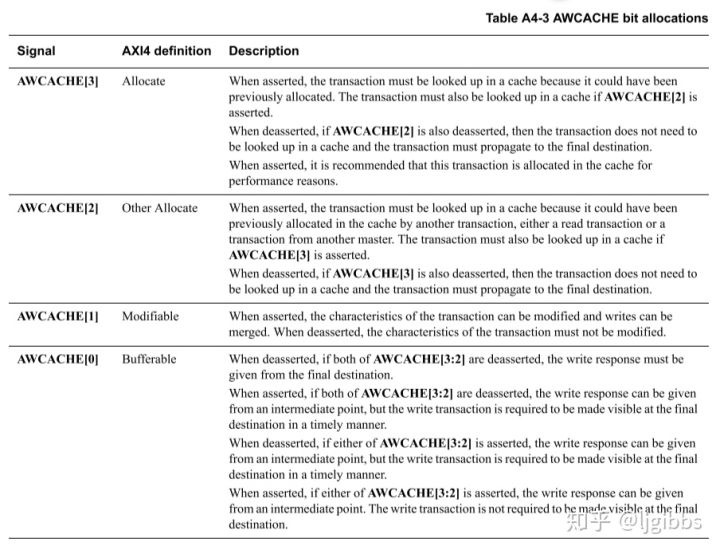
AWCACHE[3] 信号置高表示本主机先前的写事务可能已经将该位置上的数据缓冲于 cache,首先在 cache 中查找对应表项。当 AWCACHE[3] 信号置低,但 AWCACHE[2] 置高时,该位置上的数据可能因为其他主机的操作、或者本机的读事务缓存于 cache 中,同样需要首先查找 cache。
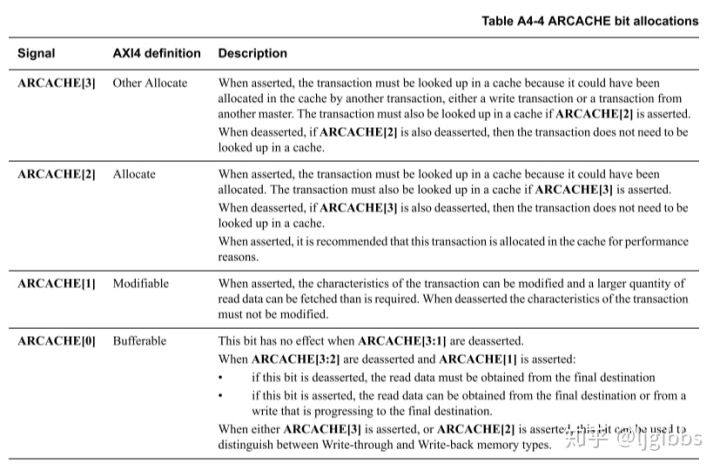
对于读事务来说,字段的含义与写事务对应,将读写事务交换即可。同时注意 Allocate 和 Other Allocate 比特的位置交换。
总的来说 AxCACHE[3:0] 主要作用在于给不同存储类型(Memory type)编码,前文只是在解释各个比特位对应的含义。换句话说,可以根据传输事务的具体存储类型,做出相应操作。
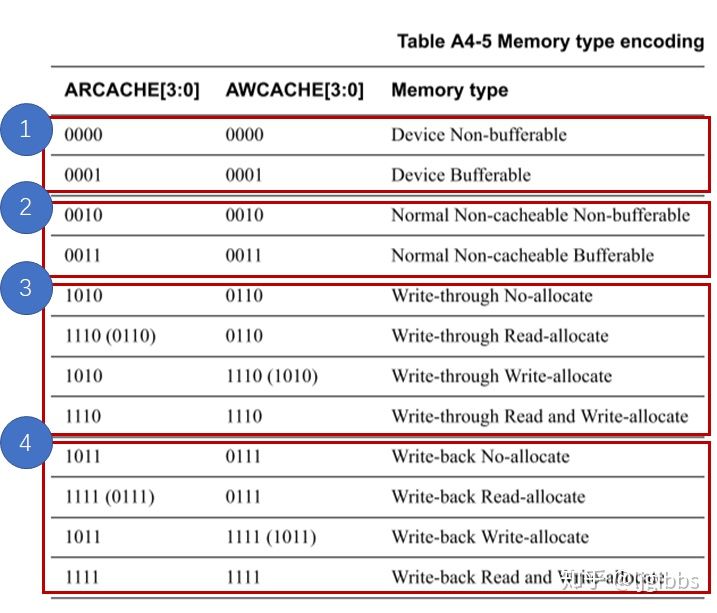
存储类型可以划分为四种情况,我们依次来看。除了上表列出的情况,AxCACHE 剩余可能的数值均留作备用。
(1)Device 访问
在访问 Device 时,AxCACHE[3:1] = 3‘b000,传输事务在中间节点不能被修改。具体地说,不能预读数据(Prefetch read)和汇聚写数据(Merge write)。这是因为在访问非存储外设时,读写的是寄存器值,预取数据是没有必要的。而将不同的写事务聚集则容易造成预期之外的问题,比如会导致相邻寄存器操作的先后顺序无法满足。
根据 AxCACHE[0] 决定 device 访问是否可以被中间节点缓存,决定 bufferable 性质。
(2)Normal Non-cacheable 访问
Normal 访问指正常地访问存储介质,而不会查找缓存,AxCACHE[3:1] = 3‘b001。Normal 非缓存访问中,中间组件可以对传输事务信息进行修改,支持写事务聚合。
根据 AxCACHE[0] 决定 normal 访问是否可以被中间节点缓存,决定 bufferable 性质。
(3)Wirte-through 访问
write-through 指缓存的写入策略为直写,即数据写入缓存的同时,也写入主存储中。此时 AxCache[1:0] = 2‘b10,即中间组件可以修改传输事务,实现写聚合与读预取。AxCache[0]置低,每个写事务最终必须写入目的地址。
此类访问启用缓存,读数据可以来自缓存,并且每次读写操作都需要查找缓存,寻找匹配表项。
根据 AxCache[3:2] 不同,从图中得到共有 4 种情况,分别代表不同的分派提示,比如 No-allocate 代表建议不要为该事务分派缓存空间。Read-allocate 代表建议为读事务分派缓存,但不建议为写事务分派缓存。不过这都只是代表处理器从性能出发给出的建议,由缓存控制器视情况执行。
(4)Write-back 访问
Write-back 指缓存的写入策略为写回,数据仅写入缓存,修改的缓存只在被替换时写入主存储。
AxCache[1:0] = 2‘b10,即中间组件可以修改传输事务,并且进行缓存。
与 Wirte-through 访问相比,区别在于由于写回策略中并不是每次写事务后都需要更新主缓存,因此无需将每个写事务传输至其本来的目的地(即主存储)。(Write transactions are not required)
为了阻止恶意程序越权访问的关键外设,AXI 协议设计了访问控制信号 AxPROT,配合其他安全机制,限定不同应用的访问权限。
读写事务的 AxPROT 信号位宽均为 3 比特,其含义如下图所示
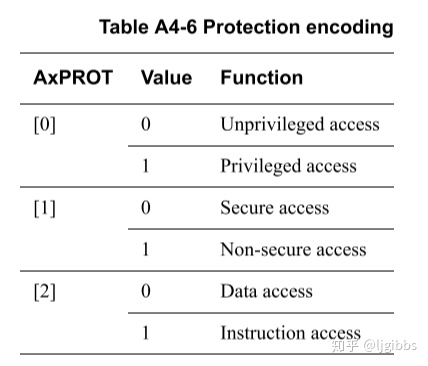
AxPORT 信号本身不存在任何机制,仅传递了权限以及安全访问信息,相关机制由 AXI 组件实现,比如 ARM TrustZone 等。
标签:目的 要求 不可 原子操作 progress 读写 访问 区别 图片
原文地址:https://www.cnblogs.com/icparadigm/p/13174276.html