标签:tps replace 基本 ica import upd 标准 table timestamp
数据集来源:
https://tianchi.aliyun.com/dataset/dataDetail?dataId=649
这个数据集既能训练取数也能训练一定的业务逻辑,是个不错的项目,在这里做个学习记录
分析目的:用MySQL分析数据集,通过用户行为分析业务问题,得出针对性的运营方案
1、分析常见的数据指标,得出各环节流失率
2、不同时间下的用户行为习惯
3、根据用户行为对用户进行价值分层
此次分析参考两个常见模型进行,即AARRR模型和RFM模型
理解数据
User_ID:用户ID
Item_ID:商品ID
Category_ID:商品种类ID
Behavior_type:用户行为类别,其中pv是点击,cart是加入购物车,fav是收藏,buy是购买
Timestamps:时间戳
数据提取和清洗
1、原数据集的数据量非常大,本文只是做分析练习,用python提取40万条数据
import pandas as pd; data = pd.read_csv(r‘C:\Users\ASUS\Desktop\UserBehavior\user.csv‘) data = data.sample(n=400000,replace=True,axis=0) data.to_csv(r"C:\Users\ASUS\Desktop\UserBehavior\user1.csv") data.head() data.info()
2、导入到Navicat中,创建userbehavior数据表,将时间戳转换为日期和时间,效果如下图
ALTER TABLE userbehavior ADD Date VARCHAR(255); ALTER TABLE userbehavior ADD TIME VARCHAR(255); UPDATE userbehavior SET Date = from_unixtime(Timestamps,‘%y-%m-%d‘); UPDATE userbehavior SET TIME = from_unixtime(Timestamps,‘%H:%I:%S‘);

因为这个数据集记录的日期是2017-11-25至2017-12-03之间,故删除掉这段日期以外的数据,共233条
DELETE FROM userbehavior WHERE date not BETWEEN ‘17-11-25‘ AND ‘17-12-03‘
分析问题
数据初步清洗完后,分析最开始提出的问题。
一、分析常见的用户指标
1、总体行为分析,构建AARRR漏斗模型
SELECT Behavior_type, COUNT(*) FROM userbehavior GROUP BY Behavior_type ORDER BY Behavior_type DESC;
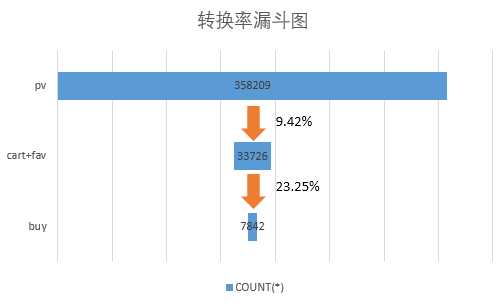
从漏斗图中可以看到,从点击到产生购买意向的转化率是9.42%,有购买意向到完成购买的转化率是23.25%,这其中可能还包含有一开始就加入了购物车或收藏的用户,故要着重提升从点击到产生购买意向这个过程的转化率,可以通过优化信息流显示、优化商品推荐、增加优质商品集等方法解决。
2、单个用户行为分析
SELECT Behavior_type, COUNT(DISTINCT user_id) as COUNT FROM userbehavior GROUP BY Behavior_type ORDER BY COUNT desc;
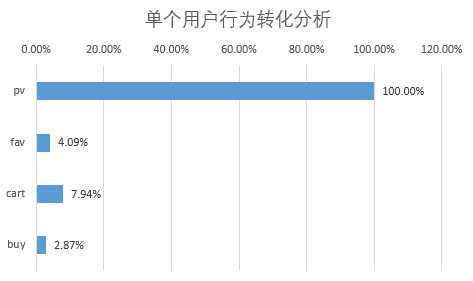
可见产生购买行为的用户占产生点击行为的用户仅2.87%,付费转化率PUR似乎并不理想
说实话分析到这,我觉得我提取的这40万数据情况有些特殊,结合单个用户行为分析数据和整体行为分析数据可以看出,将近36万的总点击量是由27万人产生的,平均每人只产生点击行为1.3次。。。大概是恰好较少点击的用户有大部分在这个数据集里。按理来说应该重新提取数据,但是我有点好奇这样的数据集,其他指标会是什么样的,毕竟前面的漏斗图还是挺正常的,就继续分析下去
3、各环节流失分析
因为上一阶段的分析可以看出这个数据集显示的PUR不理想,那就来看看各环节流失人数
先创建用户流失视图,统计每个用户的不同行为次数
CREATE VIEW 用户流失 as select user_id,sum(case when behavior_type=‘pv‘ then 1 else 0 end) as PV, sum(case when behavior_type=‘fav‘ then 1 else 0 end) as fav, sum(case when behavior_type=‘cart‘ then 1 else 0 end) as cart, sum(case when behavior_type=‘buy‘ then 1 else 0 end) as buy from userbehavior group by user_id;
看看只产生一次点击行为有多少人
SELECT COUNT(user_id) FROM `用户流失` WHERE PV = 1
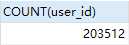
wow...原来本文的数据集里只产生一次点击行为的用户有20万人...
看看没有产生点击行为的用户有多少人
SELECT COUNT(User_ID) FROM `用户流失` WHERE PV = 0
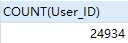
wow...本文数据集没有发生点击行为的用户将近2.5万人...
突然好奇没有点击就产生购买行为的用户数,实际情况来说确实会有用户提早加入购物车,在这段时间只是发生购买行为的
SELECT COUNT(User_ID) FROM `用户流失` WHERE PV = 0 AND buy > 0
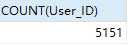
wow...人数还不少,记得在前面单个用户行为分析里得到,总共的购买用户数7750,也就是直接购买的用户占总购买用户数的66%,可以说是很特别的数据集了...
现在分析各环节流失人数,因为在用户流失视图里已经对用户进行分组,这里统计用户总数就不用distinct了
select count(user_ID)as 用户总数, sum(case when pv<>0 and fav=0 and cart=0 and buy=0 then 1 else 0 end)as 浏览后流失, sum(case when fav>0 and cart=0 and buy=0 then 1 else 0 end)as 收藏后流失, sum(case when fav=0 and cart>0 and buy=0 then 1 else 0 end)as 加购后流失, sum(case when fav>0 and cart>0 and buy=0 then 1 else 0 end)as 加购收藏后流失, sum(case when buy<>0 then 1 else 0 end)as 购买人数 from 用户流失;

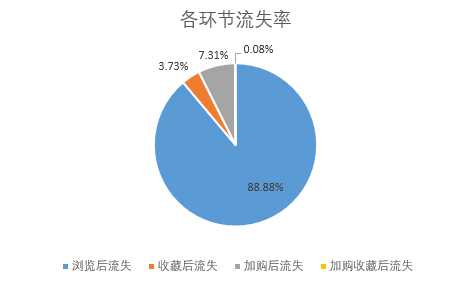
可以看到浏览后流失的用户数非常多,但是加购收藏后流失的用户数非常少,从这个角度看,可以在商品宣传推广或详情页展示时采取措施鼓励用户进行加购或者收藏,提升从浏览点击到收藏加购的转化率
二、不同时间的用户行为分析
1、一天内的24小时不同时间
SELECT HOUR(time) as 小时, sum(case WHEN Behavior_type = ‘pv‘ then 1 else 0 end) as 点击数, sum(case WHEN Behavior_type = ‘fav‘ then 1 else 0 end) as 收藏数, sum(case WHEN Behavior_type = ‘cart‘ then 1 else 0 end) as 加购数, sum(case WHEN Behavior_type = ‘buy‘ then 1 else 0 end) as 购买数 FROM userbehavior GROUP BY 小时 ORDER BY 小时;
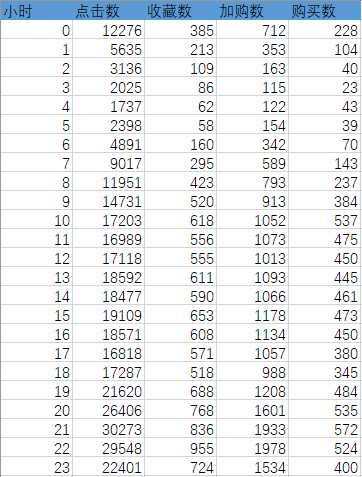
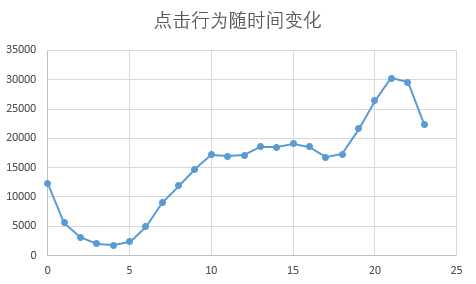
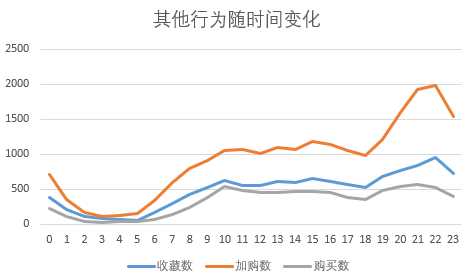
作图分析,可见:
1、用户上午9点到晚上23点之间活跃的数量是比较高的,在21点达到顶峰,而在凌晨1点到8点之间活跃用户数较低,刚好这段时间是休息及在早起上班的时间
2、每小时浏览量及加购量都在晚上21时到22时之间达到顶峰,是用户活跃度最高的时候,考虑在此时间段加大推广及曝光力度
2、一周不同天数
注意,dayofweek函数中周日是一周的第一天
SELECT DAYOFWEEK(date) as 周几, sum(case WHEN Behavior_type = ‘pv‘ then 1 else 0 end) as 点击数, sum(case WHEN Behavior_type = ‘fav‘ then 1 else 0 end) as 收藏数, sum(case WHEN Behavior_type = ‘cart‘ then 1 else 0 end) as 加购数, sum(case WHEN Behavior_type = ‘buy‘ then 1 else 0 end) as 购买数 FROM userbehavior GROUP BY 周几 ORDER BY 周几
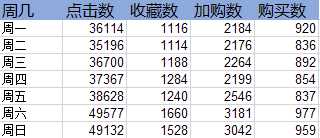
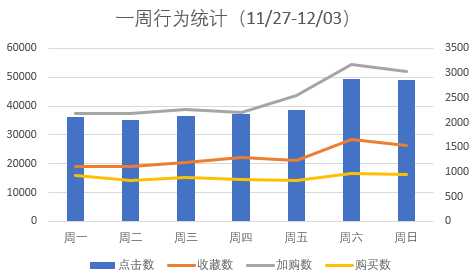
每种行为类型的趋势基本相同,可见在周末活跃人数明显更高,这也符合预期。
商家在周末应该加大商品的推广曝光力度,通过直播带货等方式
三、RFM模型做用户分层
这部分借鉴了网友的优秀做法,我自己原先的做法直接对R值和F值指定对应分数的情况,最后在Excel里相加。如下的方法有较好的借鉴意义
注意,此数据集没有金额,故M值不做计算
-- 设置参数提取有购买行为的用户总数 set @userBuyNum = ( select count(distinct user_id) as 购买用户数 from userbehavior where Behavior_type = ‘buy‘); -- 下面提取R+F分数 select r.*,f.frequency,f.freq_rank, ( -- 下面是根据R的排名进行打分 (case when r.recent_rank <= @userBuyNum*1/4 then 4 when (r.recent_rank > @userBuyNum*1/4) and (r.recent_rank <= @userBuyNum*2/4) then 3 when (r.recent_rank > @userBuyNum*2/4) and (r.recent_rank <= @userBuyNum*3/4) then 2 else 1 end)+ -- 下面是根据F的排名进行打分 (case when f.freq_rank <= @userBuyNum*1/4 then 4 when (f.freq_rank > @userBuyNum*1/4) and (f.freq_rank <= @userBuyNum*2/4) then 3 when (f.freq_rank > @userBuyNum*2/4) and (f.freq_rank <= @userBuyNum*3/4) then 2 else 1 end) ) as user_value from -- 提取R的相关数据 (select a.*,(@rank:=@rank+1) as recent_rank FROM (SELECT user_id,datediff(‘2017-12-04‘,max(date)) as recent from userbehavior where Behavior_type = ‘buy‘ group by user_id order by recent) as a, (select @rank:=0) as b) as r left JOIN -- 提取F的相关数据 (select a.*,(@rank2:=@rank2+1) as freq_rank FROM (select user_id,count(Behavior_type) as frequency from userbehavior where Behavior_type = ‘buy‘ group by user_id order by frequency DESC) as a, (select @rank2:=0) as b) as f on r.user_id = f.user_id ORDER BY user_value DESC;
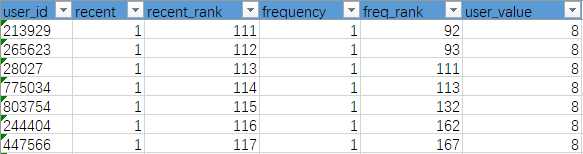
结果展示取了一小部分,分析结果中只包含产生了购买行为的用户,共7750人,最高得到8分,最低得到2分
共494位用户获得8分,约6.4%;共1535位用户获得至少7分,约19.8%;5分以上用户占62.6%;只有520位用户获得2分,约6.7%
可见淘宝APP的用户粘性还是很好的。获得7分以上的用户可以定为活跃的成熟用户,可以积极推送营销信息;在3分以下的用户,可以用更多的运营活动比如积分兑换等唤起用户的注意力
此次的学习记录到这里基本结束,原本还做了不同商品的受欢迎程度分析,分购买次数和点击次数的角度,但是这个数据集出来的结果有点微妙,就不放上来了。
总体来说这个数据集虽然有点特别,还是能展示出符合预期的指标的。
关于分析总结,
从AARRR模型来说,这个模型的五块内容是获取用户、激活用户、留存率、收益、传播。获取用户可以拿用户点击代替,不过本文的数据集直接购买的用户数不算少,所以挺微妙的。此数据集可以重点分析第二部分内容,也就是激活用户,从漏斗图中可以看出从点击到购买的转化率并不好,而从收藏加购到购买的转化率超过20%,可以着重提高从点击到收藏加购这个过程的转换率,这部分可以通过优化搜索信息流,收藏商品送小礼物,加购提前发货等等方法吸引用户收藏加购。
从RFM模型来说,计算R值和F值区分核心用户,重点在于R值和F值的划分标准。将用户分层后,针对性地对不同层次的用户提供不同的运营方案。
从实际情况考虑,这个数据集的时间在11/25-12/03这个时间段,处于双十一和双十二中间,用户可能倾向于先浏览搜索,等待双十二购买
当然正常来说,我应该重新提取用于分析的数据集。
那么,此次学习记录结束o(* ̄▽ ̄*)ブ
标签:tps replace 基本 ica import upd 标准 table timestamp
原文地址:https://www.cnblogs.com/Cles/p/13171899.html