标签:反序 reduce 节点 大数 get apache keyword 文件 统计
实验包括:创建一个存储桶比如hadoop202006…

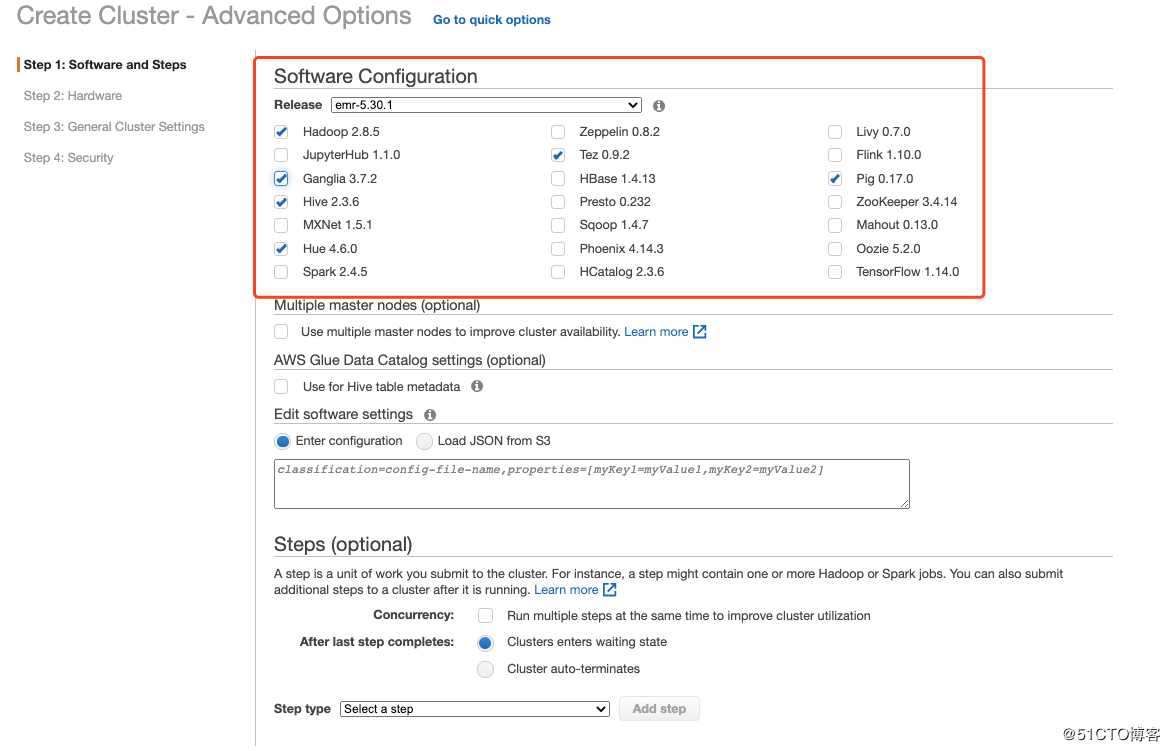
这里我解释一下Hadoop集群中的一些组件,了解大数据的同学直接忽略就好。
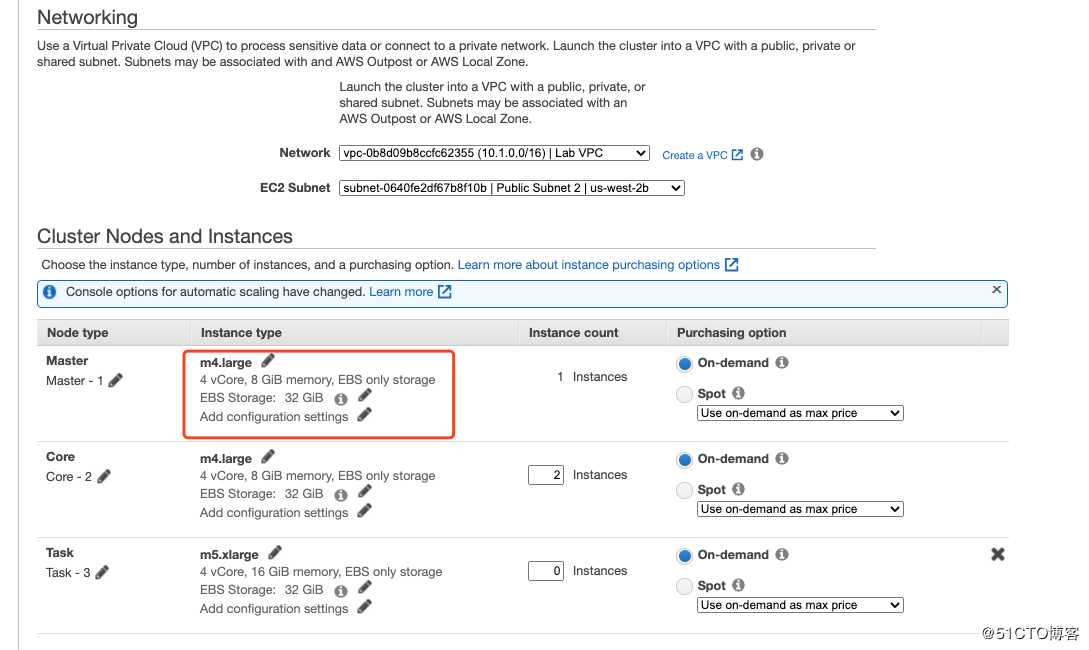
解释一下,Master、Core、Task。
MasterNode至少有一个
CoreNode 至少一个
TaskNode 可以有一个(可选)
当Cluster状态为Waiting时,执行Task3.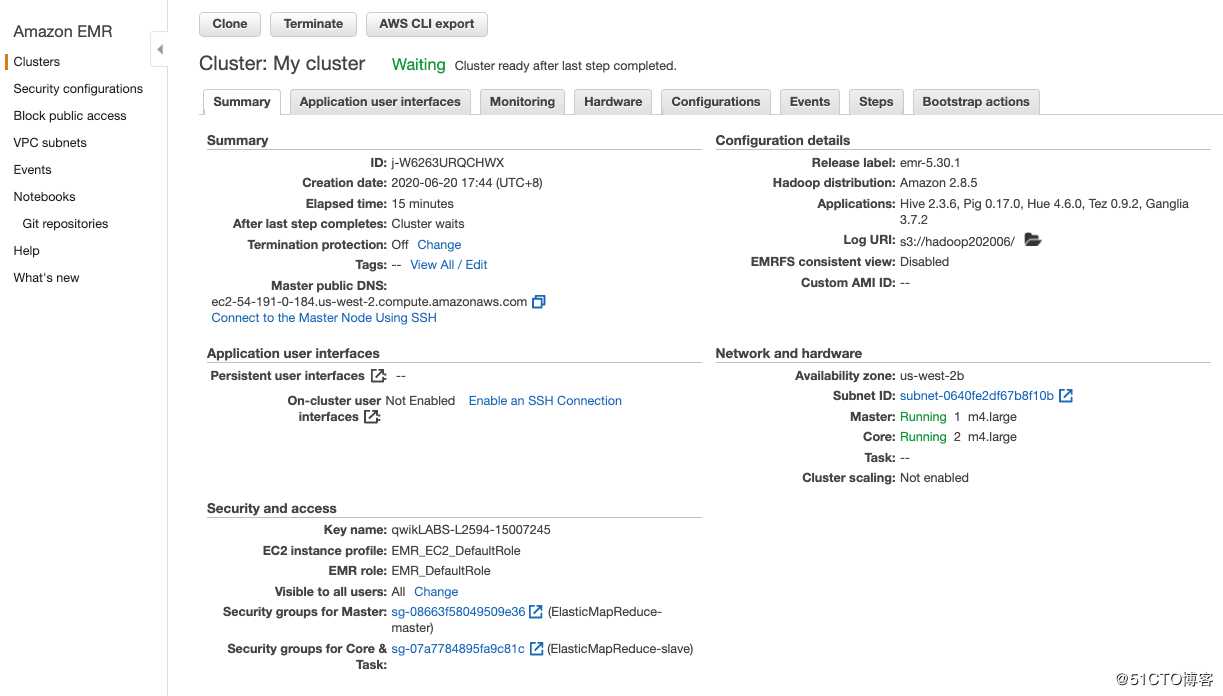
在处理数据之前肯定要明确两件事情:
如何处理数据
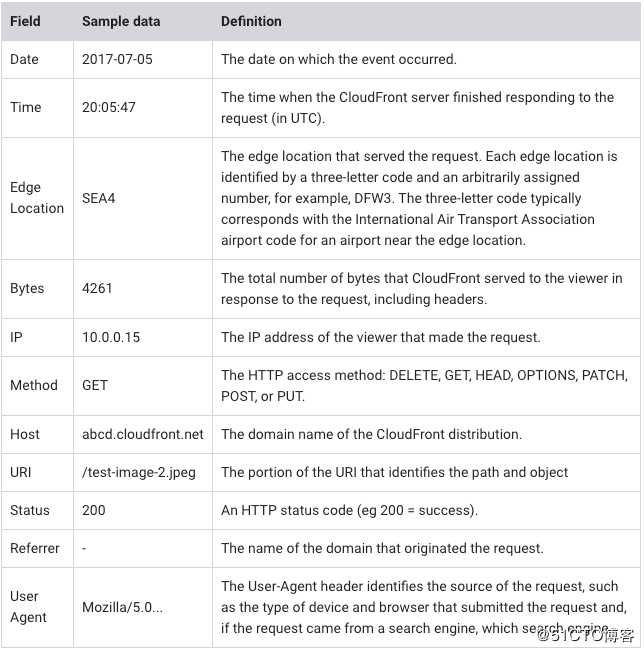
2017-07-05 20:05:47 SEA4 4261 10.0.0.15 GET eabcd12345678.cloudfront.net /test-image-2.jpeg 200 - Mozilla/5.0%20(MacOS;%20U;%20Windows%20NT%205.1;%20en-US;%20rv:1.9.0.9)%20Gecko/2009040821%20Chrome/3.0.9
解释如下:
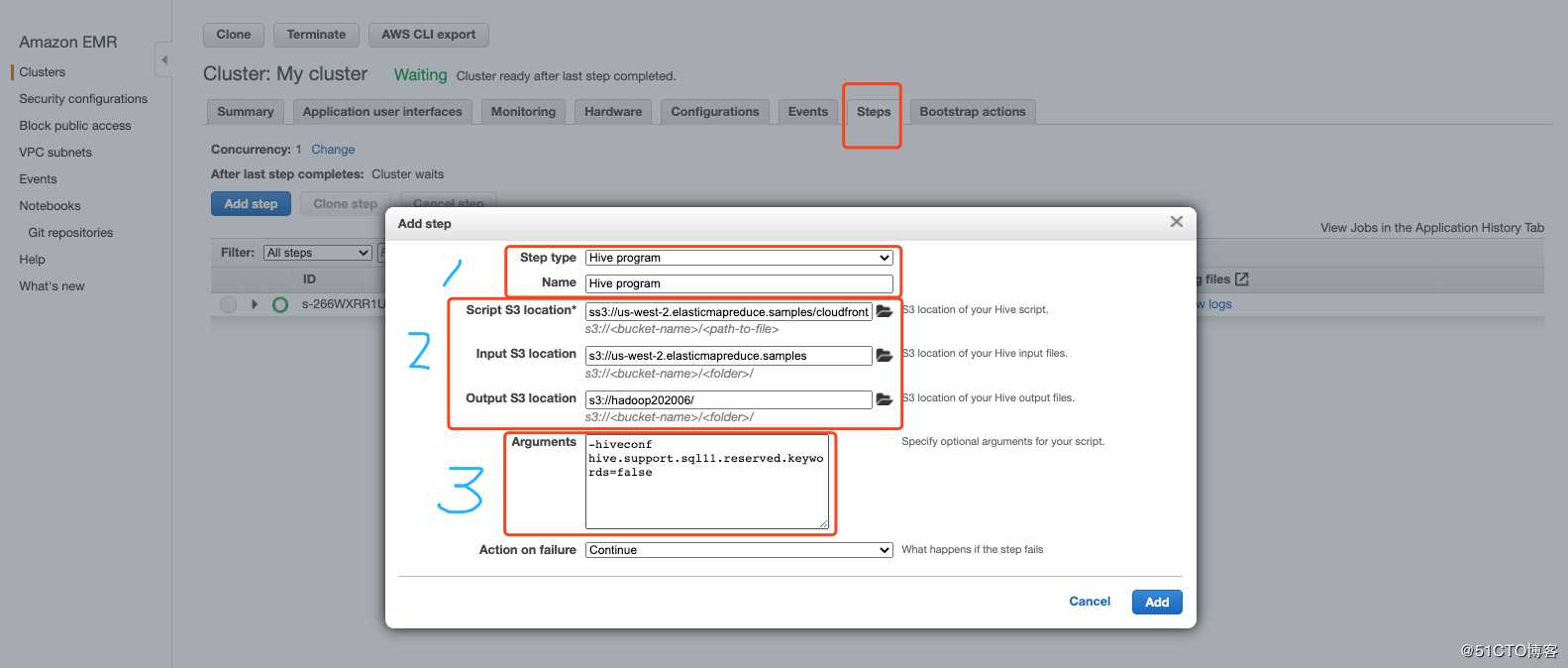
在EMR集群中,添加STEP,

如下图:
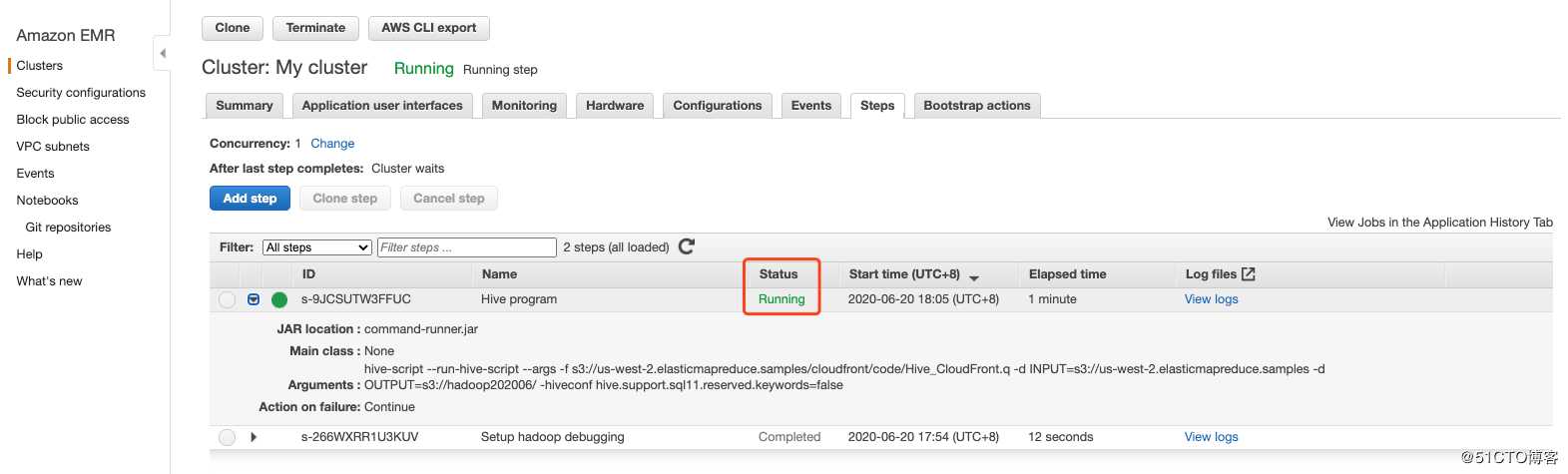
脚本都干了啥?(你可以SSH到Cluster上直接执行HiveQL)
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (DateObject Date,Time STRING,Location STRING,Bytes INT,RequestIP STRING,Method STRING,Host STRING,Uri STRING,Status INT,Referrer STRING,OS String,Browser String,BrowserVersion String)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe‘WITH SERDEPROPERTIES ( "input.regex" = "^(?!#)([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+[^(]+(.\%20([^\/]+)[\/](https://s3-us-west-2.amazonaws.com/us-west-2-aws-training/awsu-spl/spl-166/1.0.7.prod/instructions/en_us/.)$") LOCATION ‘${INPUT}/cloudfront/data/‘;
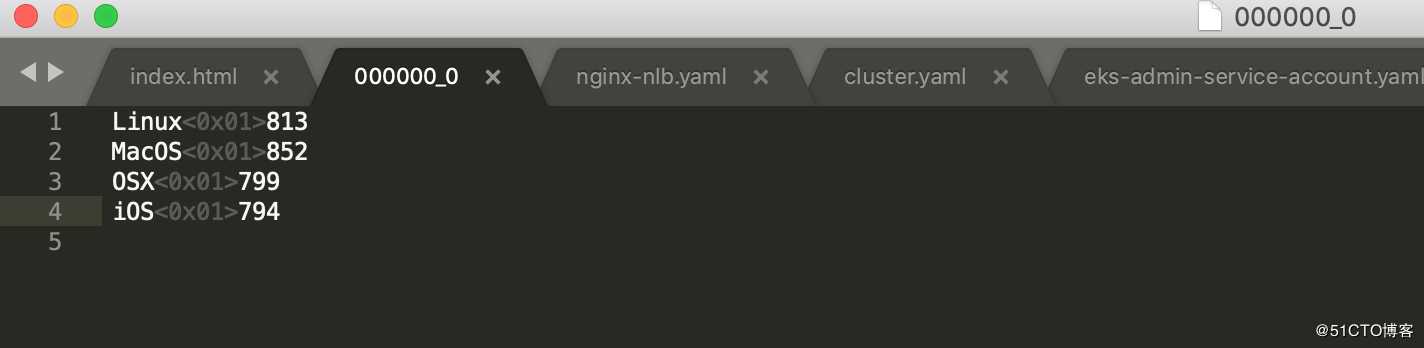
INSERT OVERWRITE DIRECTORY ‘${OUTPUT}/os_requests/‘SELECT os, COUNT(*) countFROM cloudfront_logsWHERE dateobjectBETWEEN ‘2014-07-05‘ AND ‘2014-08-05‘GROUP BY os;
有关云数据库视频教学参考:https://edu.51cto.com/course/23012.html
[AWS][大数据][Hadoop] 使用EMR做大数据分析
标签:反序 reduce 节点 大数 get apache keyword 文件 统计
原文地址:https://blog.51cto.com/13746986/2506206