标签:文件大小 crash media 配置 date values 解析 exce 文章
目录
一、Otter简介
二、Otter目前支持了什么
三、Canal & Otter 的一些注意事项
四、otter单向同步搭建测试
1. 环境准备
2. Manager使用(任务配置整个流程)
配置完整流程
3. 过程问题整理
3.1 Problem accessing /channelList.htm. Reason:
3.2 show master status 时没有数据显示
3.3 otter mainstem状态 定位中
五、相关mysql知识依赖
MySQL基于GTID的主从同步
mysql开启binlog
mysql中binlog_format模式与配置详细分析
mysql binlog的三种工作模式使用场景
行复制(binlog_format=row)
row格式在恢复数据中的好处
双M的主从复制中的循环复制问题
mysql查看binlog_format为row执行的sql语句?
MySQL异步复制、半同步复制
Mysql半同步复制详细配置
MySQL增强半同步复制
六、同类方案和产品
七、参考
一、Otter简介
otter是一款基于Java且免费、开源基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库的解决方案。
官方描述:
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
otter第一版本可追溯到04~05年,此次外部开源的版本为第4版,开发时间从2011年7月份一直持续到现在,目前阿里巴巴B2B内部的本地/异地机房的同步需求基本全上了otte4。
基本原理、项目介绍都可以参考官方github readme描述。
官方git https://github.com/alibaba/otter
二、Otter目前支持了什么
1. 单向同步, mysql/oracle互相同步
2. 双向同步,无冲突变更
3. 文件同步,本地/aranda文件
4. 双A同步,冲突检测&冲突补救
5. 数据迁移,中间表/行记录同步
三、Canal & Otter 的一些注意事项
Canal & Otter 的一些注意事项和最佳实践
参考URL: https://blog.csdn.net/weixin_34343308/article/details/91589600
四、otter单向同步搭建测试
[推荐-很全面]官方快速开始参考: https://github.com/alibaba/otter/wiki/Manager_Quickstart
mysql同步之otter/canal环境搭建完整详细版
参考URL: https://www.cnblogs.com/zhjh256/p/9261725.html
otter一共包含两个部分,manager(作为otter的配置中心和管理控制台应用)和node(作为otter的实际同步工作节点)。
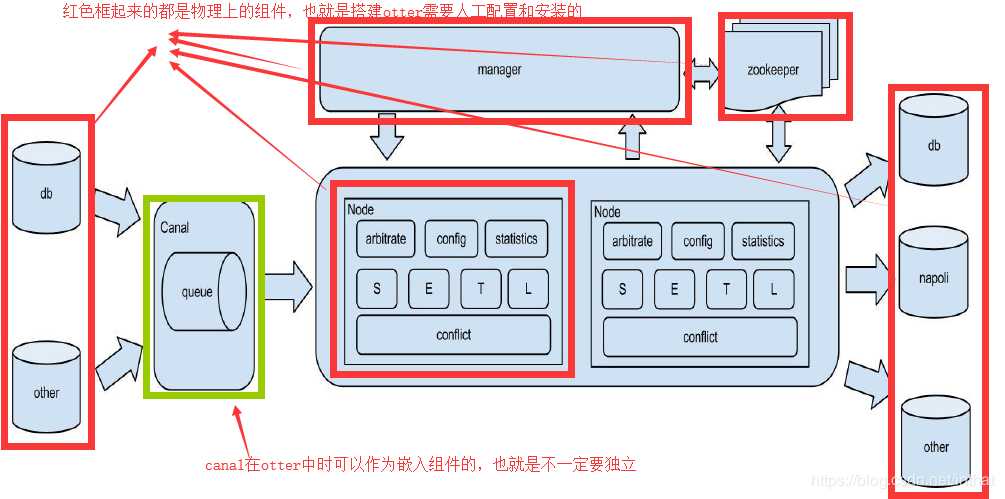
基本术语:
Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成
Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成
DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等
DataMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义
DataMediaSource : 抽象的数据介质源信息,补充描述DateMedia
ColumnPair : 定义字段映射关系
ColumnGroup : 定义字段映射组
Node : 处理同步过程的工作节点,对应一个jvm
1. 环境准备
Otter双A同步搭建入门教程
参考URL: https://www.cnblogs.com/Inspire-Yi/p/8094325.html
数据同步利器-otter的搭建使用说明
参考URL: https://blog.csdn.net/wudufeng/article/details/78688240
数据源(mysql需开启binlog,binlog_format=ROW):
Mysql_A:127.0.0.1:3306
Mysql_B:192.168.123.12:3306
ZooKeeper安装
Otter Manager安装
安装包地址 https://github.com/alibaba/otter/releases 请自己选择版本
修改配置文件
解压可见conf文件夹下otter.properties文件,修改以下配置
配置manager端口以及mysql和zookeeper的连接信息。
#以下配置为最基本需要改的配置,其他配置可根据实际要用的功能进行修改
otter.domainName = 192.168.0.130 #一定要改,不要用127.0.0.1
otter.port = 9000 #manager 站点端口号
otter.database.driver.url = jdbc:mysql://127.0.0.1:3306/otter?characterEncoding=utf-8&useSSL=false
otter.database.driver.username = root
otter.database.driver.password = password
otter.zookeeper.cluster.default = 192.168.0.130:2181
2)创建otter需要的数据库
在mysql中,新建otter所需的库,并执行otter提供的初始化sql。(初始化sql在otter的代码包中能找到,路径如下)
wget https://raw.github.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
3)启动manager
/usr/local/otter-manager/bin/starup.sh
4)判断是否成功启动
查看cat logs/manager.log
访问manage管理界面 http://127.0.0.1:9000/ (9000 为你配置文件中自己定义的监听端口)
默认账号密码是 admin/admin
mangage管理界面配置 Zookeeper集群参数
集群名字 ==> 自定义名称,方便记忆
zookeeper集群 ==> zookeeper集群机器列表,逗号分隔,最后以分号结束
Otter Node 安装
参考官方:https://github.com/alibaba/otter/wiki/Node_Quickstart
node主要负责接受manage下发任务的处理。
安装包地址 https://github.com/alibaba/otter/releases 请自己选择版本
otter node会受otter manager进行管理,所以需要预先安装otter manager
完成manager安装后,需要在manager页面为node定义配置信息,并生一个唯一id.
a. 首先访问manager页面的机器管理页面,点击添加机器按钮
在这里插入图片描述几点说明:
机器名称:可以随意定义,方便自己记忆即可
机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
机器端口:对应node节点将要部署时启动的数据通讯端口,建议值:2088
下载端口:对应node节点将要部署时启动的数据下载端口,建议值:9090
外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理。
zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群.
在这里插入图片描述通过这两部操作,获取到了node节点对应的唯一标示,称之为node id,简称:nid. 记录该nid,后续启动nid时会使用
3) node 节点配置文件配置
a. nid配置 (将环境准备中添加机器后获取到的序号,保存到conf目录下的nid文件,比如我添加的机器对应序号为1)
b. otter.properties配置修改
解压可见conf文件夹下otter.properties文件,修改以下配置
#以下配置为最基本需要改的配置,其他配置可根据实际要用的功能进行修改
otter.nodeHome = ../
otter.manager.address = 192.168.0.130:1099
4)启动node。
/path/bin/startup.sh
注:安装node要先在manager页面上配置node信息,否则启动node的时候会报错:‘在manager上找不到node x’。
5 Node正确启动后,可以查看node状态。
在manage管理界面可以查看node状态是否为已启动。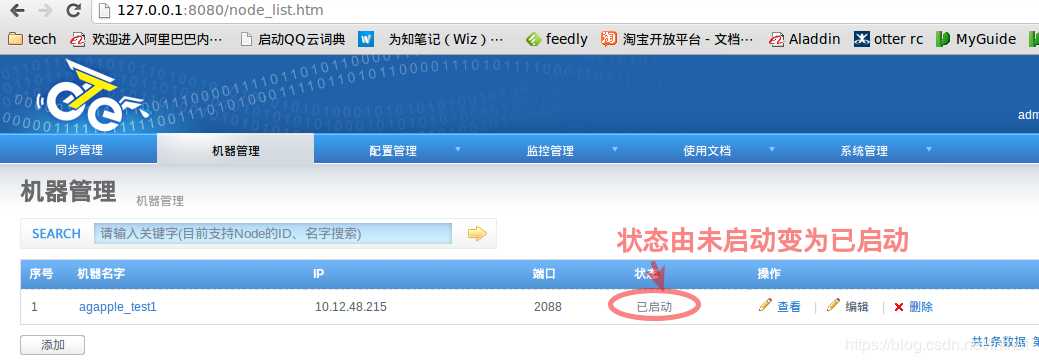
2. Manager使用(任务配置整个流程)
直接参考官网:https://github.com/alibaba/otter/wiki/Adminguide
通过manager发布同步任务配置,接收同步任务反馈的状态信息
目前manager的操作可分为两部分:
同步配置管理
添加数据源
canal解析配置
添加数据表
同步任务
同步状态查询
查询延迟
查询吞吐量
查询同步进度
查询报警&异常日志
演示sql
CREATE TABLE `test`.`example` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) COLLATE utf8_bin DEFAULT NULL ,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into test.example(id,name) values(null,‘hello‘);
配置完整流程
1) 配置管理-添加数据源 添加源数据库和目的数据库
源数据库已开启binlog,并且binlog_format为ROW.
show variables like ‘%binlog_format%‘;
2)配置管理-添加 canal
a. 提供数据库ip信息端口、账号密码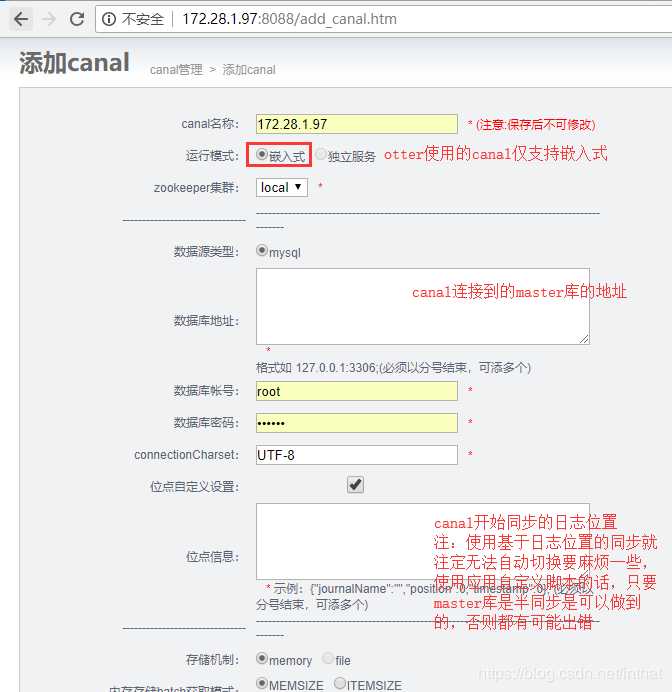
点位可以通过在主库执行show master status和select unix_timestamp()得到。
不指定任何信息:默认从当前数据库的位点,进行启动
3)添加同步表信息
a. 源数据表 test.example
b. 目标数据表 test.example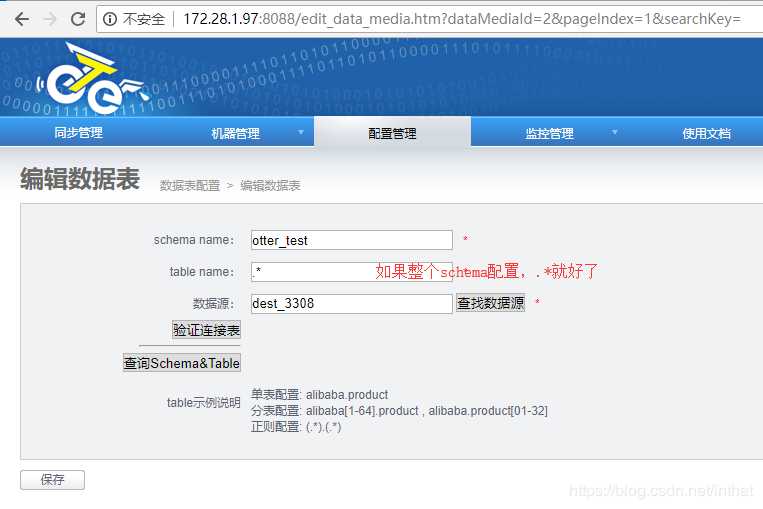
述表名可以用正则。
添加channel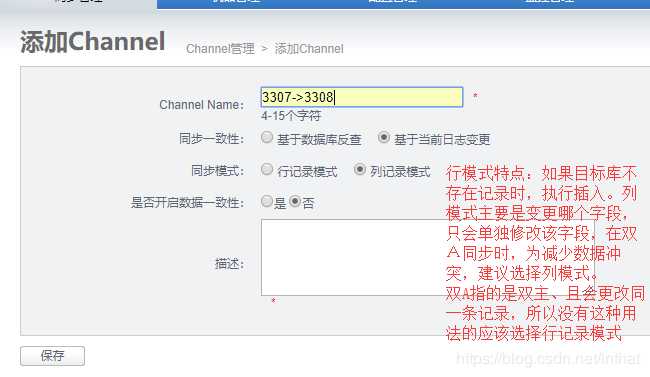
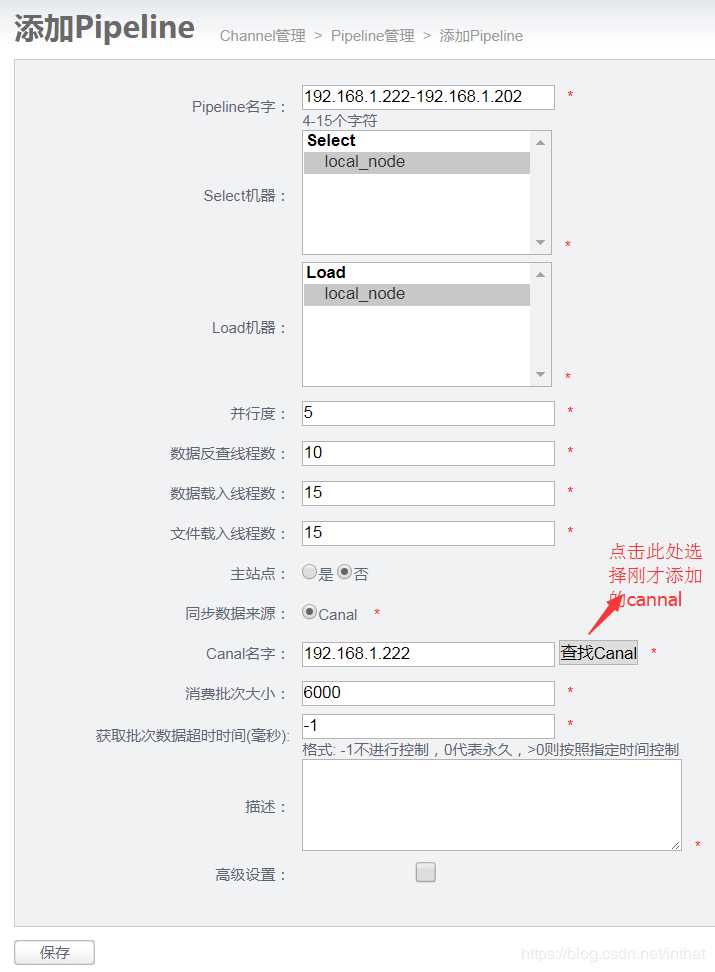
5) 添加pipeline
pipeline里面主要选择节点和canal。
添加channel成功后,点击Channel名字,进入Pipeline管理页面,添加一个pipeline;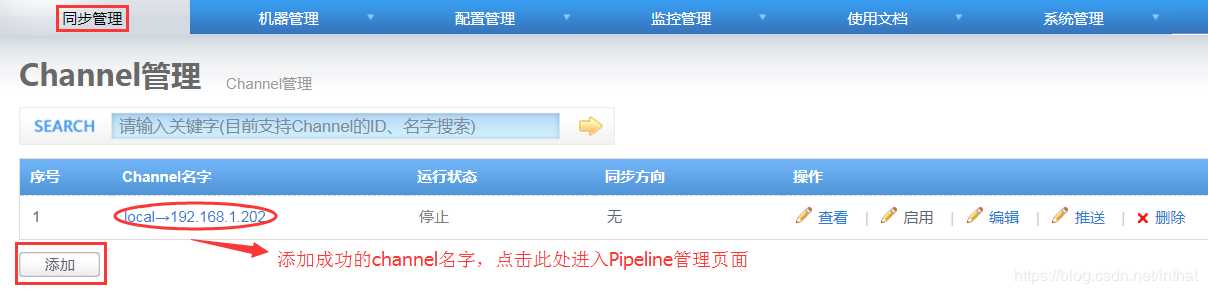
添加映射关系
添加pipeline成功后,点击Pipeline名字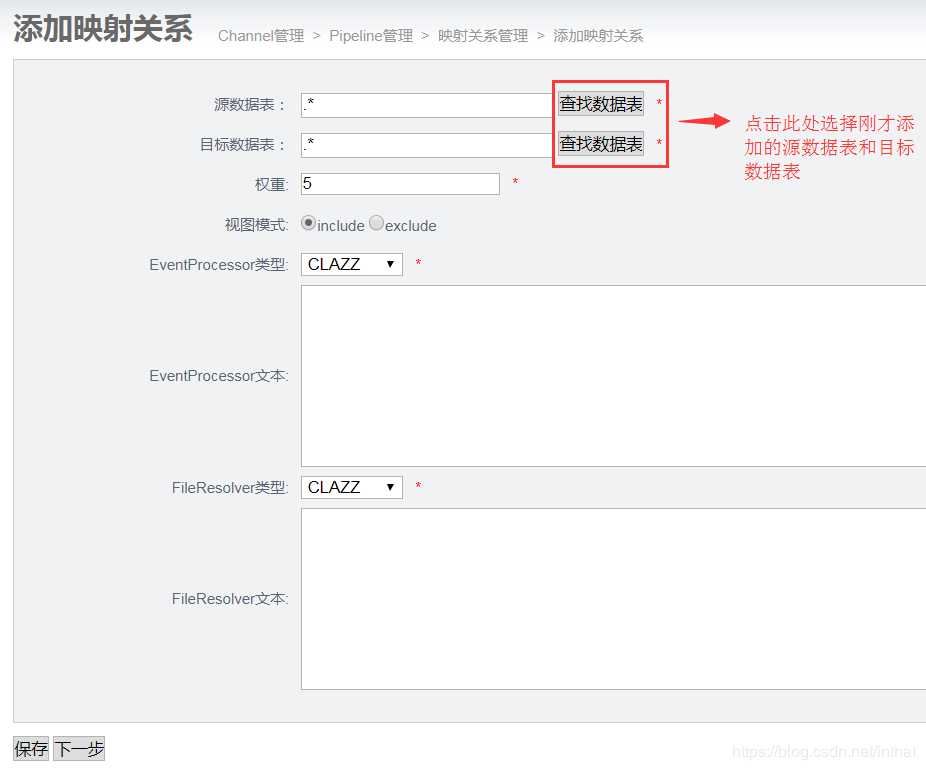
7) 启用同步
以上配置,一个简单的同步任务就完成了,返回Channel管理页面
点击“启用”,运行状态就变为“运行”;
现在可以新增一个表,插入记录,查看数据是否同步过去了。
点击Channel名字,进入Pineline管理页面,可点击“监控”查看同步状态
3. 过程问题整理
3.1 Problem accessing /channelList.htm. Reason:
Failed to invoke Valve[#2/3, level 3]: com.alibaba.citrus.turbine.pipeline.valve.PerformTemplateScreenValve#42d0e41:PerformTemplateScreenValve
继续往下查看异常
Caused by: java.sql.SQLException: null, message from server: “Host ‘DESKTOP-3ORT3QD’ is not allowed to connect to this MySQL server”
java.sql.SQLException: Access denied for user ‘root’@‘DESKTOP-3ORT3QD’ (using password: YES)
因此判断是因为mysql没有放开访问权限。因此:
注释掉文件中的绑定地址。/etc/mysql/my.cnf: #bind-address = 127.0.0.1
2)在phpMyAdmin中运行以下查询:GRANT ALL PRIVILEGES ON . TO ‘root’@’%’; FLUSH PRIVILEGES;
注意: 改完最好重启mysql
3.2 show master status 时没有数据显示
mysql show master status为空值
参考URL: https://www.cnblogs.com/lanyangsh/p/10164657.html
原因
mysql没有开启日志。
查看log_bin选项:
解决方法
在mysql 配置文件 /etc/my.cnf中
[mysqld]下添加:
log-bin=mysql-bin
3.3 otter mainstem状态 定位中
canal是运行在node节点上,因此,我们查看node节点日志:
类似路径: D:\home\otter-node\logs\1\1.log 其中1是节点id。
java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = Misconfigured master - server_id was not set
因此,修改源数据库配置
[mysqld]之后添加如下:
log-slow-queries=mysql-slow.log
log-error=mysql.err
log-bin=mysql-bin
server-id=1
解决后又报
Found old binary log without GTIDs while looking for the oldest binary log that contains any GTID that is not in the given gtid set
分析:
大致意思就是从库发现主库的binlog里面,有一部分内容并没有带上GTID的信息;
五、相关mysql知识依赖
MySQL基于GTID的主从同步
MySQL基于GTID的主从同步(一)
参考URL: https://blog.csdn.net/Necstyle/article/details/78047246
[推荐]MySQL5.7主从复制(基于GTID)
参考URL: https://blog.csdn.net/xiaojun_Fairy/article/details/78012378
[推荐]MySQL5.7双主架构搭建(基于GTID方式)
参考URL: https://blog.csdn.net/xiaoyi23000/article/details/80525625
[推荐]Mysql主从复制----传统模式切换到GTID模式
参考URL:https://blog.csdn.net/u014710633/article/details/93774379
global transaction identifiers (GTIDs),意味全局事务标识符。在MySQL主从同步中,如果使用GTID的方式来进行同步,任何在各主库中提交的事务能被识别和追踪,而且能被发送到各个从库中去。同时使用GTID模式进行复制,不需要在增加从库或更换主库时区记录binlog日志文件和文件中的偏移位置,极大简化了建主从同步的操作。GTID同步完全基于事务,因此主从的数据一致性是能得到保证的。但使用GTID会带来一些MySQL使用上的限制。
配置配置文件(/etc/my.cnf)并重启mysql(主从都配置一样)
gtid_mode=ON
enforce-gtid-consistency=ON
mysql开启binlog
log-bin=mysql-bin #添加这一行就ok
binlog-format=ROW #选择row模式,虽然Canal支持各种模式,但是想用otter,必须用ROW模式
server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
mysql中binlog_format模式与配置详细分析
Binlog日志的三种模式介绍及模式修改
参考URL: https://blog.csdn.net/m0_37814112/article/details/78638359
[推荐-认识binlog]mysql备份还原——深入解析二进制日志(1)binlog的3种工作模式与配置
参考URL:https://www.cnblogs.com/gered/p/10687319.html
[强烈推荐-全面详细-清晰]binlog的row\statement\mixed模式与具体内容
参考URL: https://blog.csdn.net/h2604396739/article/details/86680974
mysql复制主要有三种方式:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
① STATEMENT模式(SBR)
优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行的变化,较少bin-log日志量,节约IO,提高性能。因为它只需要记录在master上所执行的语句的细节,以及执行语句时候的上下文信息。
缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)。
Statement level缺点:一些新功能同步可能会有障碍,比如函数、触发器等。
② ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。
优点:在row level的模式下,bin_log中可以不记录执行的sql语句的上下文信息,仅仅只需要记录哪一条记录被修改,修改成什么样。所以row level的日志内容会非常清楚的记录每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程,或fuction,以及trigger的调用或处罚无法被正确复制的问题。
缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
总结:
row level的优点:
1、记录详细
2、解决statement level模式无法解决的复制问题。
row level的缺点:日志量大,因为是按行来拆分。
③ MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
binlog复制配置
在mysql的配置文件my.cnf中,可以通过一下选项配置binglog相关
[mysqld]
binlog_format=row //binlog日志格式,mysql默认采用statement,建议使用mixed
log-bin = /data/mysql/mysql-bin.log //binlog日志文件
expire_logs_days = 7 //binlog过期清理时间
max_binlog_size = 100m //binlog每个日志文件大小
binlog_cache_size = 4m //binlog缓存大小
max_binlog_cache_size = 512m //最大binlog缓存大小
mysql binlog的三种工作模式使用场景
【3.1】row level(默认级别:mysql5.7.6之后+8.0)
日志中记录每一行数据修改的情况;
(1)有点:可以更方便查看每一条数据修改的细节 (2)缺点:数据量比较大
使用场景:希望数据最安全,复制强一致。
【3.2】statement level(默认级别:Mysql5.7.6之前)
记录每一条修改的SQL
(1)优点:解决了数据量比较大的问题 (2)缺点:容易出现主从复制不一致
使用场景:使用mysql的功能比较少,又不使用存储过程/触发器/函数
【3.3】mixed(混合模式)
结合 row level 与statement level的优点
一般情况下都使用statement,但是如果隔离级别设置为RC,那么一般会使用row
不建议使用,还不如使用row level
行复制(binlog_format=row)
你所不知道的行复制(binlog_format=row)
参考URL: http://blog.itpub.net/30221425/viewspace-2637246/
mysql rc模式时binlog_format=row的解释【转】
参考URL: https://www.cnblogs.com/chaosheng/p/5446157.html
总体来说:在 tx_isolation= READ-COMMITTED 、binlog_format =statement 的情况下,mysql 没有gap 锁,这样binlog 记录的数据修改的顺序可能会导致 复制环境的 slave 数据和master 数据不一致。
row格式在恢复数据中的好处
[强烈推荐-全面详细-清晰]binlog的row\statement\mixed模式与具体内容
参考URL: https://blog.csdn.net/h2604396739/article/details/86680974
delete 语句,row 格式的 binlog 也会把被删掉的行的整行信息保存起来。所以,如果你在执行完一条 delete 语句以后,发现删错数据了,可以直接把 binlog 中记录的 delete 语句转成 insert,把被错删的数据插入回去就可以恢复了。
insert 语句呢?那就更直接了。row 格式下,insert 语句的 binlog 里会记录所有的字段信息,这些信息可以用来精确定位刚刚被插入的那一行。这时,你直接把 insert 语句转成 delete 语句,删除掉这被误插入的一行数据就可以了。
如果执行的是 update 语句的话,binlog 里面会记录修改前整行的数据和修改后的整行数据。所以,如果你误执行了 update 语句的话,只需要把这个 event 前后的两行信息对调一下,再去数据库里面执行,就能恢复这个更新操作了。
有人在重放 binlog 数据的时候,是这么做的:用 mysqlbinlog 解析出日志,然后把里面的 statement 语句直接拷贝出来执行。
这个方法是有风险的,例如使用了now(),不同时间执行now()就变了。因为有些语句的执行结果是依赖于上下文命令的,直接执行的结果很可能是错误的,row格式下会记录执行sql时now的值。
所以,用 binlog 来恢复数据的标准做法是,用 mysqlbinlog 工具解析出来,然后把解析结果整个发给 MySQL 执行。
mysqlbinlog master.000001 --start-position=2738 --stop-position=2973 | mysql -h127.0.0.1 -P13000 -uuser−p
user−ppwd;
双M的主从复制中的循环复制问题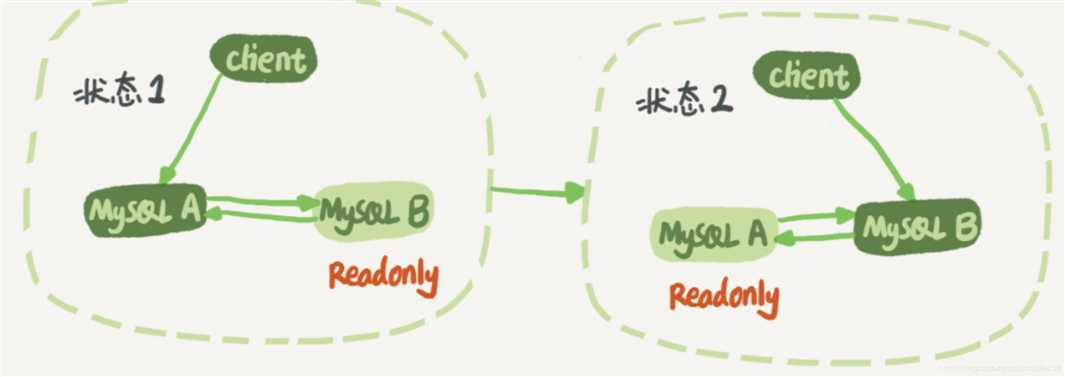
节点 A 同时是节点 B 的备库,相当于又把节点 B 新生成的 binlog 拿过来执行了一次,然后节点 A 和 B 间,会不断地循环执行这个更新语句,也就是循环复制了。这个要怎么解决呢?
MySQL 在 binlog 中记录了这个命令第一次执行时所在实例的 server id。因此,我们可以用下面的逻辑,来解决两个节点间的循环复制的问题:
规定两个库的 server id 必须不同,如果相同,则它们之间不能设定为主备关系;
一个备库接到 binlog 并在重放的过程中,生成与原 binlog 的 server id 相同的新的 binlog;
每个库在收到从自己的主库发过来的日志后,先判断 server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志。
按照这个逻辑,如果我们设置了双 M 结构,日志的执行流就会变成这样:
从节点 A 更新的事务,binlog 里面记的都是 A 的 server id;
传到节点 B 执行一次以后,节点 B 生成的 binlog 的 server id 也是 A 的 server id;
再传回给节点 A,A 判断到这个 server id 与自己的相同,就不会再处理这个日志。所以,死循环在这里就断掉了。
mysql查看binlog_format为row执行的sql语句?
使用mysql的bin目录底下的mysqlbinlog有查看binlog的工具
加上-v 能看详细语句
window环境下cmd命令页面
E:\xampp\mysql\bin>mysqlbinlog.exe e:\xampp\mysql\mysql-bin.000004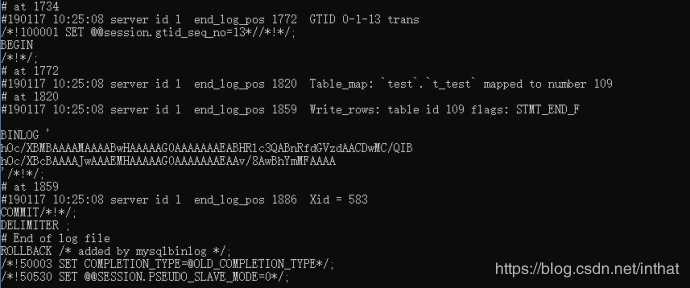
E:\xampp\mysql\bin>mysqlbinlog.exe e:\xampp\mysql\mysql-bin.000004 -v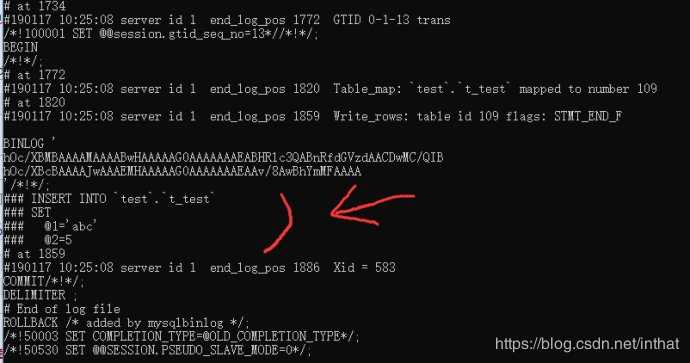
-v 是显示出一些sql的信息 -vv则是多一些注释性的东西
–base64-output=DECODE-ROWS 这个是把sql解码出来(执行sql部分的sql显示为base64编码格式,该参数把base64解析出来)
总结: 当binlog_format=row时,用mysqlbinlog想查看二进制日志时需要加上-v参数。
mysqlbinlog --base64-output=decode-rows -v ./mysql-bin.000003
可以注释掉row-format的binlog,出现可识别的sql(不过也是注释的)
MySQL异步复制、半同步复制
异步复制(Asynchronous replication)
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
MySQL 5.5之前的复制都是异步的,主服务器在将更新操作写入二进制日志文件中后,不用管从服务器是否已经完成复制,就可以自由处理其它事务处理请求。异步复制能提供较高的性能,但无疑易造成主/从服务器数据的不一致。MySQL 5.5开始引入半同步复制功能,此功能是由google开发的一个插件实现的。半同步复制要求主库提交的每一个事务,至少有一个备库成功接收后,才能继续提交下一个。
Mysql半同步复制详细配置
mysql主从复制、半同步复制配置记录
参考URL: https://yq.aliyun.com/articles/689732
在主、从上安装和开启半同步插件
mysql> install plugin rpl_semi_sync_master soname ‘semisync_master.so‘;
Query OK, 0 rows affected (0.02 sec)
mysql> set global rpl_semi_sync_master_enabled=on;
在主、从上检查是否安装成功
mysql> show variables like ‘%semi%‘;
相关参数解释
rpl_semi_sync_master_enabled ##设置为on表示开启了半同步功能
rpl_semi_sync_master_timeout ##单位是毫秒,表示如果主库等待从库回复消息的时间超过该值,就自动切换为异步复制模式
rpl_semi_sync_master_wait_for_slave_count ##它控制主库接收多少个从库写 事务 成功反馈,才返回成功给客户端
rpl_semi_sync_master_wait_point ##默认值是AFTER_SYNC,含义是主库将每个 事务 写入binlog,并传递给从库,刷新到中继日志,主库开始等待从库的反馈,接收到从库的回复之后,再提交事务并且返回“commit ok”结果给客户端
重启从库的io线程让设置生效
stop slave io_thread;
start slave io_thread;
最好不要重启sql_thread,免得影响slave的重演工作。
MySQL增强半同步复制
MySQL增强半同步复制
参考URL: https://cloud.tencent.com/developer/news/299922
MySQL在5.7版本中,主库上的事务提交之前会等待一个从库返回ACK信号。为了进一步增加数据的完整性,新的特性将等待从库返回ACK信号的时间点提前了(相对于MySQL5.5以及MySQL5.6),新特性中主库上的事务会在存储引擎层提交之前一直等待从库返回ACK信号。
在MySQL 5.7.2之前的版本中,用户在恢复crash掉的主库的时候,需要做以下操作:
手动清除并没有被复制到从库上的binlog事务
手动回滚已经提交但是还没有被复制的事务
因为新的特性保证所有的事务在提交之前都至少复制到一个从库上了,所以第二步可以不用做了。
如何设置新特性
这个特性的设置很简单,用户无需任何设置,因为在MySQL 5.7.2版本之后该特性是默认开启的。用户可以设置 变量控制主库等待从库返回ACK信号的时间点。
总而言之,这个新特性保证了主库和从库之间的数据完整性、一致性,并不会带来任何副作用以及性能印象。我强烈推荐你去尝试该特性。
六、同类方案和产品
DTLE
MySQL开源数据传输中间件架构设计实践
参考URL: https://www.jianshu.com/p/9813b4a95490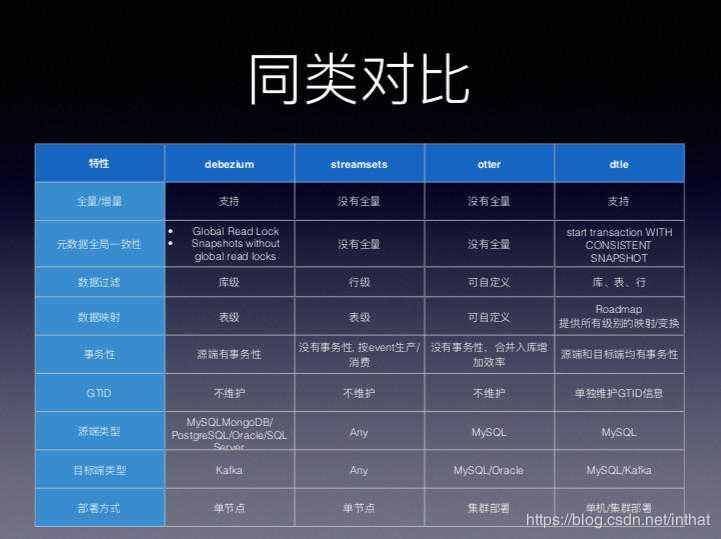
详解MySQL双活同步复制四种解决方案
参考URL:https://www.jb51.net/article/146131.htm#_label3
基于MySQL原生复制主主同步方案
基于Galera replication方案
基于Group Replication方案
基于canal方案
七、参考
官方https://github.com/alibaba/otter/wiki/Manager_Quickstart
[推荐]Otter 双向同步mysql
参考URL: https://blog.csdn.net/weixin_41676972/article/details/86632078
otter 数据库单向同步和双向同步
参考URL: https://blog.csdn.net/liaoxiaolin520/article/details/85779256
[强烈推荐-双活解决思路]了解 MySQL 双活同步复制四种方案
参考URL: https://www.sohu.com/a/199665469_151779
利用otter实现跨机房数据同步
参考URL: https://blog.51cto.com/icenycmh/2113579
双A机房解决方案
参考URL: https://blog.csdn.net/toontong/article/details/51014405
otter安装配置和注意事项
参考URL: https://www.jianshu.com/p/095656d95ed0
————————————————
版权声明:本文为CSDN博主「西京刀客」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/inthat/java/article/details/93595156
标签:文件大小 crash media 配置 date values 解析 exce 文章
原文地址:https://www.cnblogs.com/purple5252/p/13176551.html