标签:web自动化 ima loading 实例代码 源码 百度搜 列表 print htm
from selenium import webdriver # 导包
# 实例化浏览器 如果为空就是是用的项目根目录的Chrome驱动
borwser = webdriver.Chrome()
# 请求网址
borwser.get(‘http://www.baidu.com‘)
# print(borwser.page_source) # 获取网页源码
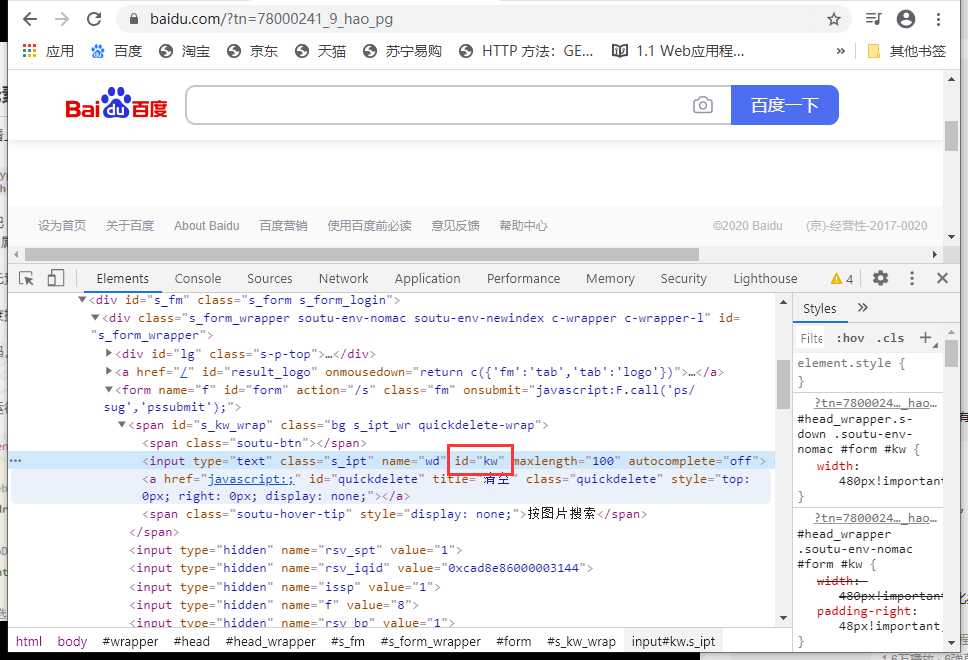
# 根据ID定位并 返回是该元素webelement对象
ele = borwser.find_element_by_id(‘kw‘)
# 可以通过webelement对象 就要对元素操作了 例如输入字符串
ele.send_keys(‘老祝头‘)
borwser.find_element_by_id(‘su‘).click() # 点击搜索
from selenium import webdriver # 导包
# 实例化浏览器 如果为空就是是用的项目根目录的Chrome驱动
borwser = webdriver.Chrome()
# 请求网址
borwser.get(‘http://f.python3.vip/webauto/sample1.html‘)
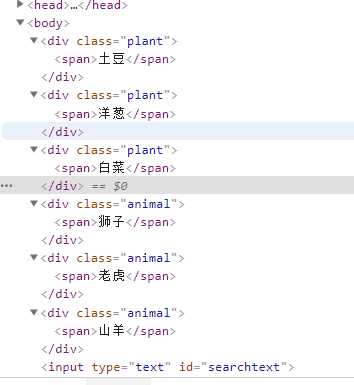
# 根据class name 选择元素 返回的是列表
ele = borwser.find_elements_by_class_name(‘plant‘)
# 取出列表中每个 webelement对象中的文本内容
for i in ele:
print(i.text)
标签:web自动化 ima loading 实例代码 源码 百度搜 列表 print htm
原文地址:https://www.cnblogs.com/sunzzc/p/13178141.html