标签:没有 存在 bsp width math 带来 get nal 控制
概述
贝叶斯神经网络是一类神经网络模型,模型的参数不是固定的值,而是分布,如$(图1)$所示。这样设置,我们就能够对数据和模型的不确定性(uncertainty)进行评估。例如有一个函数$f(x)=y$,当函数$f$确定时,输入$x$能得到唯一确定的y,如果我们调整$f$,得到的$y$就会发生变化。
现实中,数据内部通常会存在不确定性,$x$和$y$之间存在一定随机性。对于数据$x$和$y$,函数$f$的参数$w$服从后验$p(w|x,y)$,而不是确定的值。但是像在之前变分推断的文章中分析的,后验难以计算,所以我们要想办法将它转换为简单的可计算的问题。其中一种求近似问题的方法就是变分推断。变分推断是解决贝叶斯神经网络中的后验估计的流形方法,因为这种方法计算较快,而且适用于大规模数据——另一种方法是MCMC(Markov Chain Monto Carlo,马尔科夫链蒙特卡洛),它适合处理小规模数据,今后会介绍。
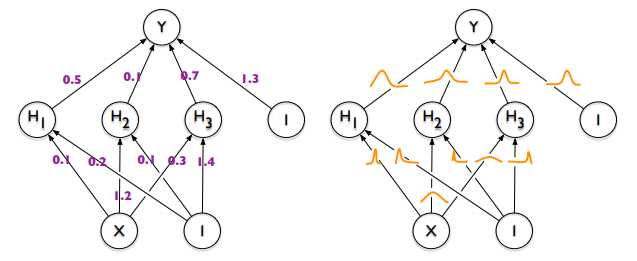
(图1,来自论文《Weight Uncertainty in Neural Networks》)
不确定性
上面说了,贝叶斯神经网络可以评估不确定性。论文$[1]$中将不确定性分为两类,偶然不确定性(aleatoric uncertainty)和认知不确定性(epistemic uncertainty)。偶然不确定性是指数据本身存在的不确定性,它可能是现实中各种原因造成的,例如传感器接收信号时产生的波动。这类不确定性并不会随着我们采集的数据的增加而减小。同时,这类不确定性又可以划分为同方差不确定性(homoscedastic uncertainty)和异方差不确定性(heteroscedastic uncertainty),其中前者表示所有子数据集中的不确定性都相同,而后者指不同子数据集中不确定性并不相同,可能某一部分数据中不确定性更大,而其他子数据集的不确定性较小。而认知不确定性性又称为模型不确定性(model uncertainty),这种不确定性随着处理的数据的增长,会逐渐降低,这就像当我们接触到越来越多的外国人时,我们对他们的认识就更全面。当我们缺乏对某样东西的认识时,我们会随意地相信我们相信的东西,模型也是一样。当模型没有见过某类数据时,它可以自由地设定它的参数$w$。对于参数的这种不确定性,我们可以用后验$p(w|x,y)$来评估。
变分推断
因为后验$p(w|x,y)$难以计算,所以我们用变分推断来求它的近似。设后验的近似是变分分布$q(w|x,y)$,为了让变分分布接近后验,我们设定目标函数为KL散度$KL(q(w|x,y) \parallel p(w|x,y))$。就像之前变分推断的文章中说的,后验$p(w|x,y)$难以计算,所以我们将目标函数替换为$ELBO$(Evidence Lower BOund)。我们可以把数据$x$和$y$都统一看成数据$D$,此时$ELBO$的形式如下:
\begin{align} ELBO(q) &= E_q [\log{p(D|w)} ] - KL(q(w|D) \parallel p(w)) \label{1} \\ &= E_q [\log{p(w,D)} ]- E_q [\log{q(w)} ] \nonumber \end{align}
为了求解$ELBO$,我们需要对$w$进行采样。我们可以假设$w$服从高斯分布$w \sim q(w|D)=N(\mu,\sigma^2)$——其他分布也可以——这样$w$就可以通过$z=g(\epsilon, D)=\mu + \sigma \epsilon$来采样。这里$\epsilon$是一个随机噪音,服从高斯分布$N(0,I)$,也就是说向量$\epsilon$中的元素的值在[0,1]区间,所以$z$是服从$N(\mu,\sigma^2)$分布的样本。但是为了避免$\sigma$取负值,从而导致数值稳定性(numerical stability)问题,实践中会采用$\rho$代替$\sigma$,并用softplus函数计算$\sigma$:
\begin{equation} \sigma = \log{(1+\exp{(\rho)})} \nonumber \end{equation}
用$\mu$和$\sigma^2$,或者说用$\mu$和$\rho$代替$w$,这种方法被称为重参数法(reparameterization trick)。这样,我们就可以采用stochastic的方法,优化我们的目标函数$ELBO$:
\begin{align} &ELBO= \frac{1}{M} \sum_{m=1}^M {\log{p(D_i, w_{i,m})}} - \log{q(w_{i,m},D_i)} \label{2} \\ &w_{i,m} = g(\epsilon_{i,m}, D_i) \nonumber \end{align}
因为式$(\ref{1})$中的KL散度是可以求解析解的,所以也可以采用下面的式子:
\begin{align} &ELBO = \frac{1}{M} \sum_{m=1}^M {\log{p(D_i| w_{i,m})}} -KL(q(w|D) \parallel p(w)) \nonumber \\ &w_{i,m} = g(\epsilon_{i,m}, D_i) \nonumber \end{align}
采用stochastic的方法,我们可以处理大规模的数据,因为$M$是批数据的数据量,它可以是较小的值,甚至是1。但是,我们可以发现,普通的神经网络模型的参数是$w$,而现在变成了$\mu$和$\rho$,参数的规模为原来的两倍。
参数先验
我们可以用$(\ref{2})$的方法计算参数的先验,但这样计算出来的先验是基于训练集的。除了$(\ref{2})$,还有其他方法设定可以先验,例如论文$[2]$中采用的混合尺度先验:
\begin{equation} p(w) = \prod_i {\pi N(w_i|0, \sigma_1^2) + (1-\pi)N(w_i|0, \sigma_2^2)} \nonumber \end{equation}
其中$\pi$是[0,1]区间的随机数,当$\pi=1$时$w$来自等号右边的第一个高斯分布,而当$\pi=0$时$w$来自第二个高斯分布,当$0<\pi<1$时是两个分布的混合。另外,第一个高斯分布的方差$\sigma_1^2$大于$\sigma_2^2$,且$\sigma_2^2$远小于1,从而使这些参数趋近于0。
除了混合尺度先验外,还有spike-and-slab先验、马蹄铁先验(horsehoe prior)等先验。
优化过程
我们采用随机优化的方法来优化$(\ref{1})$$ELBO$。假设每次只处理一条数据,并且取负的$ELBO$,从而将目标转换为最小化目标函数,那么$(\ref{1})$可以这样表示:
\begin{align} L &= -ELBO = - \log{p(D|w)} + \log{q(w|D)} - \log{p(w)} \nonumber \\ &= \log{q(w|D)} -\log{p(w)p(D|w)} \nonumber \end{align}
其中变分分布$q(w|D)$可以替换为$q(w|\mu,\rho)$。此时,优化参数$\mu$和$\rho$,可以采用随机梯度下降法(Stochastic Gradient Descent,SGD):
\begin{align} &\mu^{t+1} = \mu^{t} - \lambda \Delta \mu \nonumber \\ &\rho^{t+1} = \rho^{t} - \lambda \Delta \rho \nonumber \\ &\Delta \mu = \frac{\partial L}{\partial w} + \frac{\partial L}{\partial \mu} \nonumber \\ & \Delta \rho = \frac{\partial L}{\partial w}\frac{\varepsilon}{1+ \exp{-\rho}} + \frac{\partial L}{\partial \rho} \nonumber \end{align}
可以发现,$\frac{\partial L}{\partial w}$就是普通的神经网络的梯度。
局部重参数技巧
前面说到,对模型参数进行重参数化处理,会使模型参数的规模增大,而采用局部重参数化的方法,可以降低模型的计算量。局部重参数化,是将对参数的重参数化处理,替换为对激活函数的输出的重参数处理。这种方法假设激活函数的输出服从下面的高斯分布:
\begin{equation} o_{j,n}^l \sim N(\sum_{i=1}^{dim \, l-1}{\mu_{j,i}^l a_{i,n}^{l-1}}, \sum_{i=1}^{dim \, l-1}{(\sigma_{j,i}^l)^2 (a_{i,n}^{l-1})^2}) \nonumber \end{equation}
其中$a_{i,n}^{l-1}$是第$n$个数据对应在神经网络的第$l-1$层的第$i$个单元的输出,$dim \, l-1$表示第$l-1$层的维度,也就是神经元数目,$\mu_{j,i}^l$和$\sigma_{j,i}^l$是从第$l-1$层的神经元$i$到第$l$层的第$j$个神经元的参数。另外,$a_{j,n}^l=f(o_{j,n}^l)$,其中$f$是激活函数。所以:
\begin{equation} o_{j,n}^l = \sum_{i=1}^{dim \, l-1}{\mu_{j,i}^l a_{i,n}^{l-1} +\varepsilon_{j,n}^l \sqrt{(\sigma_{j,i}^l)^2 (a_{i,n}^{l-1})^2} } \nonumber \end{equation}
其中$\varepsilon_{j,n}^l \sim N(0,1)$。
局部重参数化有一个缺点,就是它只能用于没有参数共享的神经网络,例如全连接网络(fully-connected neural network)。但是收局部重参数技巧的启发,有一种通用的方法可以用各种模型,它就是variational dropout(这里就不细讲了,以后有时间在补充吧)。
预测
贝叶斯神经网络将神经网络嵌套到贝叶斯框架中。在贝叶斯推断(Bayesian inference)中,预测$y$值采用:
\begin{align} p(\hat{y}|\hat{x}) &= E_{p(w|x,y}[p(\hat{y}|\hat{x},w)] \nonumber \\ &= \int{p(w|x,y)p(\hat{y}|\hat{x},w)}dw \end{align}
其中$\hat{y}$是未知的预测值,$\hat{x}$是新数据,$x$和$y$来自训练集,$w$是模型参数,$p(w|x,y)$是$w$的后验,是我们上面变分推断所近似的分布。事实上,经过上面的变分推断以及重参数处理,后验已经替换为变分分布$q(w|\mu,\rho)$。另外,后验又可以看作是以$w$为参数的模型$p(\hat{y}|\hat{x},w)$的权重,因此贝叶斯神经网络相当于集成模型,计算模型平均。
$(图2)$展示了贝叶斯神经网络和标准神经网络预测的区别。图中黑色的交叉是训练集数据点,红色的是线条和浅蓝色区域是对所有数据(包括训练集)预测的结果,其中红线是预测的中位数(median),蓝色区域是四分位数区域(interquartile range)。可以看到,对训练集没有覆盖的区域,标准的神经网络从试图使预测结果的方差减小为0,这会使某些趋向于拟合到某个确定的函数,而这个函数未必是正确的——就像我们对不了解的东西可能有某种偏见,例如歧视。而贝叶斯神经网络则给这些区域的预测结果较低的置信度(confidence),也就是有更多可能的结果。贝叶斯神经网络,在认知不确定性较高的区域,其预测结果一定程度上取决于先验$p(w)$。不同的先验选择会带来不同的预测结果。
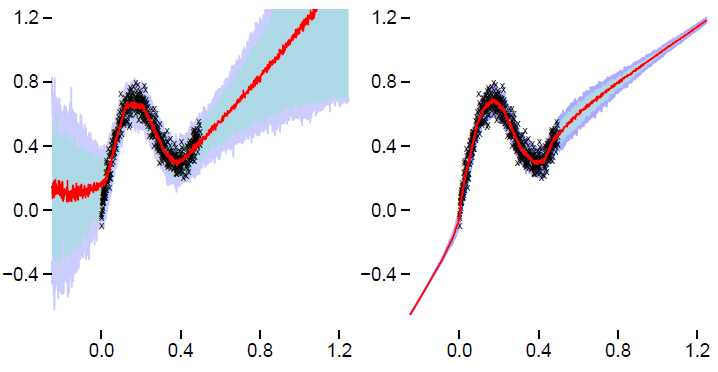
(图2,来自论文《Weight Uncertainty in Neural Networks》)
结语
经过三篇变分推断、一篇自编码器以及这篇贝叶斯神经网络,我们对变分推断应该是有了一个比较全面的认识。为了控制时间,文章的质量可能不是很好,而且删除了一些知识点。被删掉的知识点以后可能会补充进来(看心情)。不管怎么,希望这几篇文章对读者能够有帮助。
[1] Kendall, A., Gal, Y. (2017). "What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?".
[2] Blundell, C., Cornebise, J., Kavukcuoglu, K., Wierstra, D. (2015). "Weight Uncertainty in Neural Networks".
标签:没有 存在 bsp width math 带来 get nal 控制
原文地址:https://www.cnblogs.com/kai-nutshell/p/13156375.html