标签:blog http io os 使用 java sp 文件 数据
为什么HBase主要应用于在线应用系统?(还没搞懂)
google 三大论文 Google File System MapReduce BigTable
HBase shell 是一个封装了Java api 的JRuby软件
一个表可以有多个列簇,至少一个列簇
HBase==无模式数据库
HBase两种方式读取数据:get和scan
HBase每个数据单元可以有多个时间版本,版本数有默认值,也可以自定义,取出时默认是最新版本
scan命令在不指定情况下返回所有行
什么事HBase的逻辑数据模型、物理数据模型和模式设计
HBase运行和操作需要配置信息,有两种方式来定义或者获得配置信息,一种是从配置文件中获取比如hbase-site.xml,另一种是手动输入。shell一般用的是配置文件,Java api一般用的是手动,如果不指定,则使用默认的,比如zookeeper.quorum是localhost,如果你在客户端非集群上,显然不行,则要手动配置
由于操作hbase需要获得链接,消耗网络开销,所以有了链接池,链接从链接池里分配,工作关闭后链接返回到链接池
hbase中所有数据都是按字节数组的形式存储的
hbase使用坐标来定位数据。行健、列簇、列、时间版本。rowkey column family column qualifier version
hbase中数据作为值value存在单元里
hbase中修改数据使用的方式跟存储新数据使用的方式一样
执行写入的时会写到两个地方:预写式日志(WAL)和memstore。只有这两个地方的变换信息确认后才认为写操作完成
memstore,内存里的写入缓冲区。当memstore填满后刷新到硬盘,生成一个HFile。
HFile对应列族,一个列族可以有多个HFile,但一个HFile不能存多个列族的数据。在集群每个节点上,每个列族有一个memstore
如果HBase宕机,没有从memstore刷写数据到HFile,可以通过回访WAL来恢复。不用手工操作,HBase内部机制中有恢复流程部分来处理
每台服务器有一个WAL,这台服务器上所有表共享这个WAL
blockcache读优化。最近最少使用算法
删除是给要删除的内容打上墓碑标记,用来标志删除的内容不能被get和scan读取。
因为HFile不能改变,所以直到一次大合并,这些墓碑记录才会被处理
合并分为大合并和小合并。小合并把多个小的HFile合并成一个大的HFile。大合并将处理给定region的一个列族的所有HFile。大合并相当耗费资源。大合并是清理删除记录的唯一机会
如果一个单元的版本超出了最大数量,多出的记录会在下一次大合并的时候扔掉
关系型数据库是二维坐标系统,HBase是四维坐标系统
如果使用get检索数据的时候如果不指定时间版本,返回数据中会是多个时间版本的映射集合,按照坐标的降序排列
什么是半结构化数据
HBase没有事务
HFile本身是二进制文件
在HBase中query的替代品是scan加filter
Filter在服务器端过滤,不是在客户端。过滤器可以组合
HBase的在线操作(online)和离线操作(offline)
一张总的大HBase表切分成小一点的数据单位分配到堕胎服务器上,这些小一点的数据单位叫做region,托管region的服务器叫做regionserver。一个regionserver托管多个region
为什么工作负载主要是随机读写就不需要MR框架?
单个region大小可以自定义,如果超过则切分成两个
ROOT和META表用来查找region位置在哪儿。META表如果大到一定程度可以切分,ROOT表不会切分
zookeeper提供HBase的入口点,即ROOT表
在HBase中使用mapreduce计算和多线程计算有同样的效率,但是吞吐量却高很多的原因:数据的并行放置,让任务本地化了
(counters是hadoop作业里收集监控指标的一个简单方法)
宽表和窄表
get()API内部实现是一次扫描单行的scan()运算
get()的使用必须需要行健,scan没有限制,如果有起始和终止则可以限定范围
对于HBase集群,最消耗计算资源的操作发生在使用服务器过滤器扫描结果的时候
协处理器从0.92.0版本引入
OpenTSDB,基于HBase,一种数据可视化工具
scan ‘-ROOT-’
scan ‘.META.’
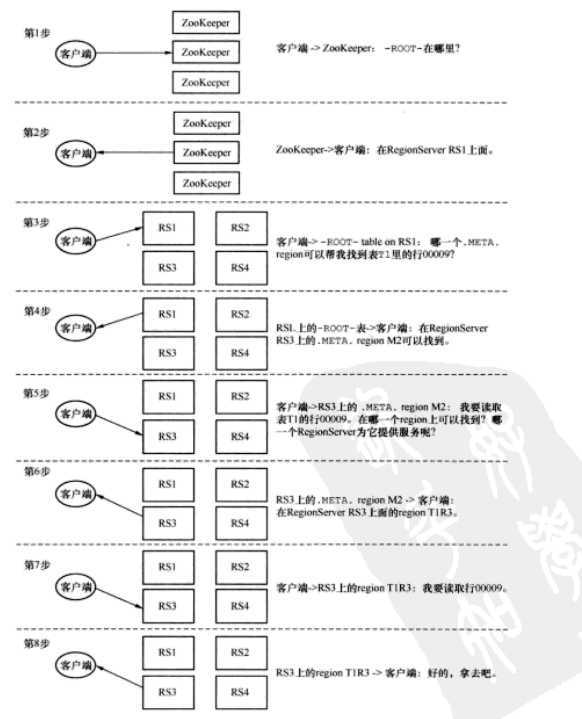
这些都是在HBase实战中看的,这本书不错
http://pan.baidu.com/s/1i3uwuZN
下一步学安装
标签:blog http io os 使用 java sp 文件 数据
原文地址:http://www.cnblogs.com/admln/p/HBase-againHBase.html