标签:设计 shp 并行编程 了解 alt 并行 组成 思想 模型
一、课前准备
1. 3节点hadoop集群
2. 安装IDEA
3. 安装maven并配置环境变量
二、课堂主题
1. 围绕MapReduce分布式计算讲解
三、课堂目标
1. 理解MapReduce编程模型
2. 独立完成一个MapReduce程序并运行成功
3. 了解MapReduce工程流程
4. 掌握并描述出shuffle全过程(面试)
5. 理解并解决数据倾斜
四、知识要点
1. MapReduce编程模型
小任务分别在不同的服务器上并行的执行,最终再汇总每个小任务的结果
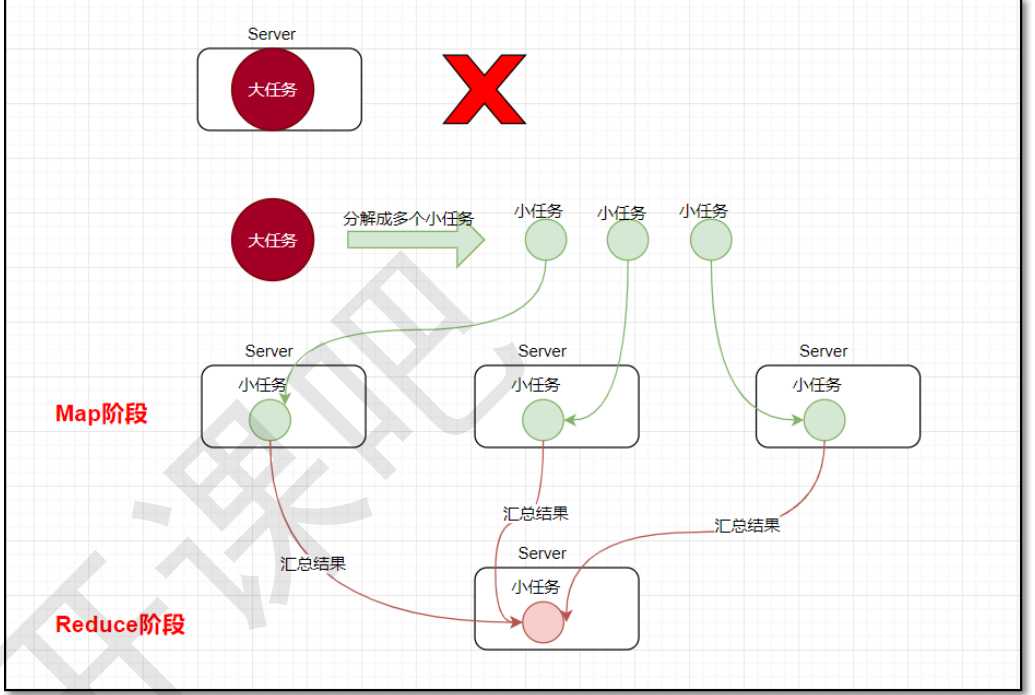
1.1 Map阶段
1.2 Reduce阶段
1.3 Main程序入口
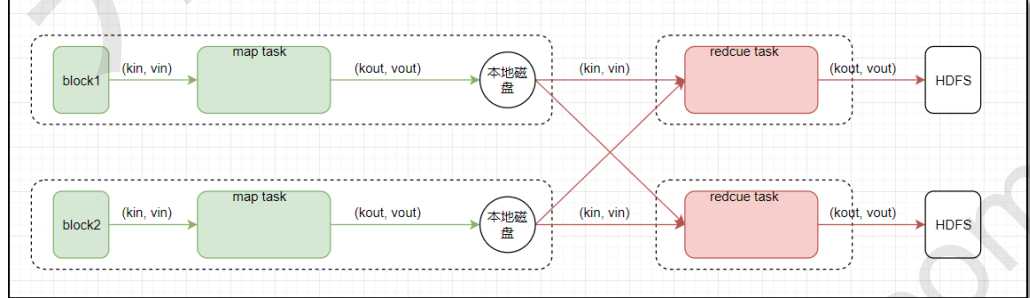
2. MapReduce编程示例
2.1 MapReduce原理图
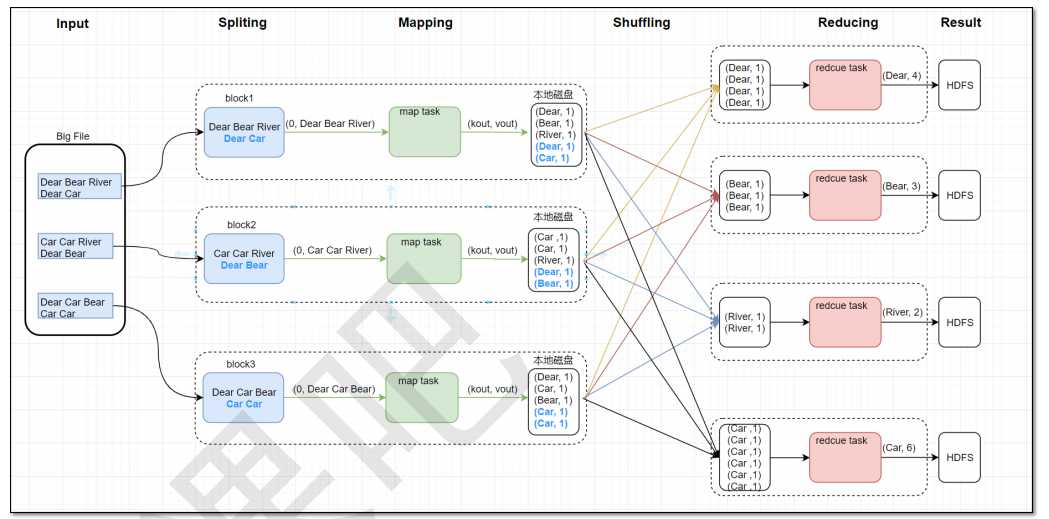
2.2 MR参考代码
2.2.1 Mapper代码
3. WEB UI 查看结果
3.1 Yarn
浏览器url地址: rm 节点IP:8088
3.2 HDFS结果
4. Combiner
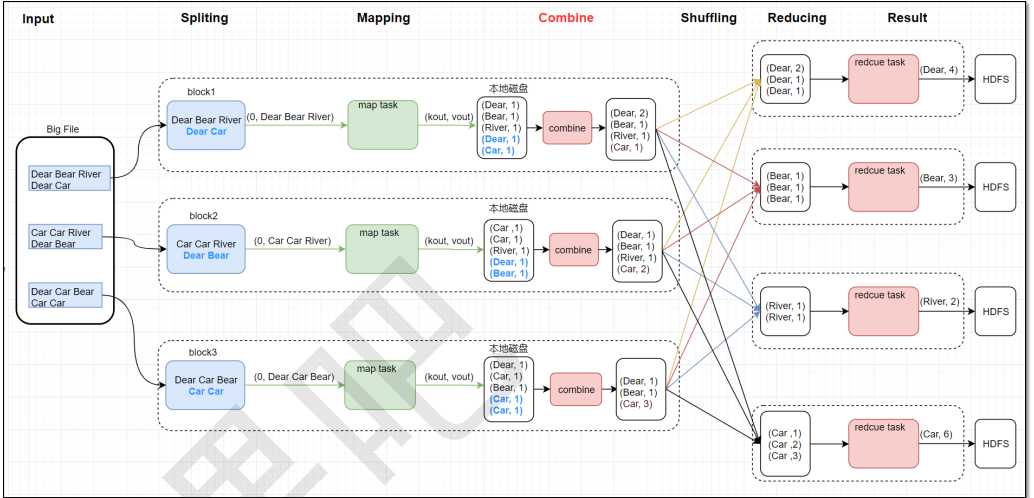
5. Shuffle
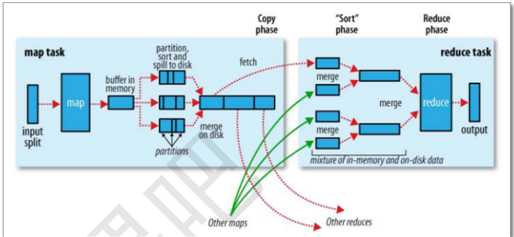
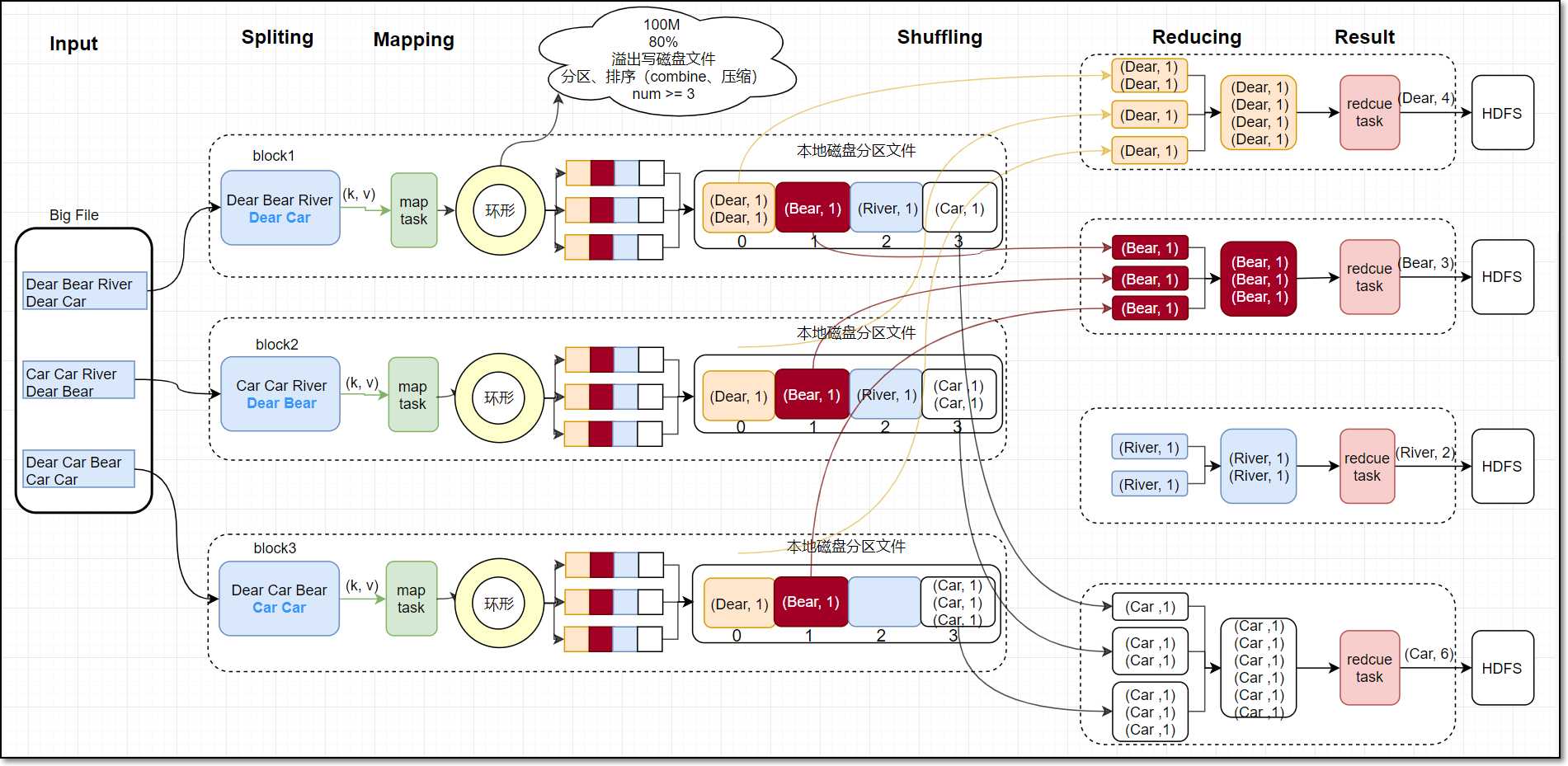
map task 向环形缓冲区写
环形缓冲区 100M,当使用达到80%,会溢出写磁盘文件(将环形缓冲区文件写入到磁盘中)
写的过程: 分区、排序(combine、压缩 、num>=3)
分区:默认HashPartition =>getPartition()方法,
(key.hashCode()&Integer.MAX_VALUE) % numReduceTasks
排序:每个分区内排序,根据key排序,
最后将多个小的分区文件合并成一个大的分区文件(仍然是排序的)
6. 自定义分区Partition
7. 二次排序
8. MapReduce分区倾斜
标签:设计 shp 并行编程 了解 alt 并行 组成 思想 模型
原文地址:https://www.cnblogs.com/hanchaoyue/p/13185305.html