标签:enc 之间 使用 cer 文章 演示 set color byte
倒排索引,也是索引。
索引,初衷都是为了快速检索到你要的数据。
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
对 Mysql 来说,是 B+ 树,对 Elasticsearch/Lucene 来说,是倒排索引。
Elasticsearch 是建立在全文搜索引擎库 Lucene 基础上的搜索引擎,它隐藏了 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API,不过掩盖不了它底层也是 Lucene 的事实。
Elasticsearch 的倒排索引,其实就是 Lucene 的倒排索引。
首先,在数据生成的时候,比如爬虫爬到一篇文章,这时我们需要对这篇文章进行分析,将文本拆解成一个个单词。
这个过程很复杂,比如 “生存还是死亡”,你要如何让分词器自动将它分解为 “生存”、“还是”、“死亡”三个词语,然后把“还是”这个无意义的词语干掉。这里不展开,具体涉及到分词相关知识,后续我会单独写一系列分词相关的文章。
接着,把这两个词语以及它对应的文档id存下来:
word documentId
生存 1
死亡 1
接着爬虫继续爬,又爬到一个含有“生存”的文档,于是索引变成:
word documentId
生存 1,2
死亡 1
下次搜索 “生存”,就会返回文档ID是 1、2两份文档。
基本原理是这样的,但是离实际情况还差的很远。
想想看,你有上百万 或 上亿 的文档,分词后的 word 何其之多,要查找一个词你要全局遍历,先不说是否可以遍历完毕,光内存就放不下这么多东西。
于是有了排序,我们需要对单词进行排序,像 B+ 树一样,可以在页里实现二分查找。
光排序还不行,你单词都放在磁盘呢,磁盘 IO 慢的不得了,所以 Mysql 特意把索引缓存到了内存。
还是想我所说的问题一样,那么多词都放到内存肯定会爆炸的。
所以,elasticsearch 底层存储如下图所示:
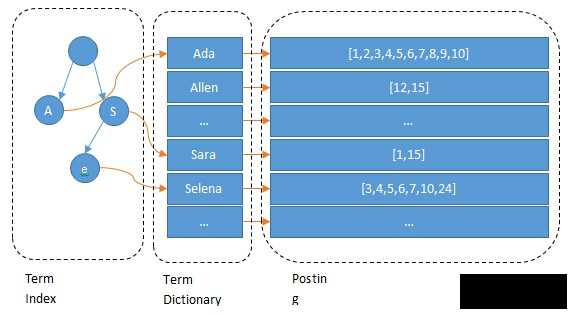
Lucene 的倒排索,增加了最左边的一层「字典树」term index,它不存储所有的单词,只存储单词前缀,通过字典树找到单词所在的块,也就是单词的大概位置,再在块里二分查找,找到对应的单词,再找到单词对应的文档列表。
当然,内存寸土寸金,能省则省,所以 Lucene 还用了 FST(Finite State Transducers)对它进一步压缩。
FST 是什么?这里就不展开了,这次重点想聊的,是最右边的 Posting List 的,别看它只是存一个文档 ID 数组,但是它在设计时,遇到的问题可不少。
原生的 Posting List 有两个痛点:
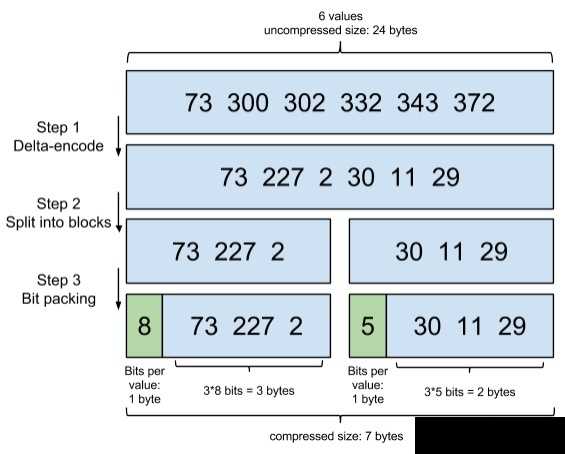
我们来简化下 Lucene 要面对的问题,假设有这样一个数组:
[73, 300, 302, 332, 343, 372]
如何把它进行尽可能的压缩?
Lucene 里,数据是按 Segment 存储的,每个 Segment 最多存 65536 个文档 ID, 所以文档 ID 的范围,从 0 到 2^16-1,所以如果不进行任何处理,那么每个元素都会占用 2 bytes ,对应上面的数组,就是 6 * 2 = 12 bytes。
怎么压缩呢?压缩的原则是什么?
压缩,就是尽可能降低每个数据占用的空间,同时又能让信息不失真,能够还原回来。
我们只记录元素与元素之间的增量,于是数组变成了:
[73, 227, 2, 30, 11, 29]
Lucene里每个块是 256 个文档 ID,这样可以保证每个块,增量编码后,每个元素都不会超过 256(1 byte).
为了方便演示,我们假设每个块是 3 个文档 ID:
[73, 227, 2], [30, 11, 29]
对于第一个块,[73, 227, 2],最大元素是227,需要 8 bits,好,那我给你这个块的每个元素,都分配 8 bits的空间。
但是对于第二个块,[30, 11, 29],最大的元素才30,只需要 5 bits,那我就给你每个元素,只分配 5 bits 的空间,足矣。
这一步,可以说是把吝啬发挥到极致,精打细算,按需分配。
以上三个步骤,共同组成了一项编码技术:
Elasticsearch调优篇 01 - Elasticsearch 倒排索引这一篇足够了
标签:enc 之间 使用 cer 文章 演示 set color byte
原文地址:https://www.cnblogs.com/liang1101/p/13186763.html