标签:man 一个 force eve 错误信息 执行 port 恢复 测试
1 问题:
最近有一个测试环境的 Swarm 集群挂了, 这个集群有两个管理节点, 执行 docker node ls, 均报:
The swarm does not have a leader. It‘s possible that too few managers are online. Make sure more than half of the managers are online
明明两个管理节点都在线.
2 分析:
通过 docker info 命令, 看到一条错误信息
Error: rpc error: code = Unknown desc = The swarm does not have a leader. It‘s possible that too few managers are online. Make sure more than half of the managers are online.
逐个分析两个节点的日志, 发现周期性打印的错误日志:
第一个管理节点:
第二个管理节点报:
初步得出结论, 第二个管理节点证书有问题, 并且很大可能是过期了,
根据字面信息猜测一下: 这里好像是个 BUG, 刷新本地证书需要请求某一个远程节点, 请求远程节点又报证书不对, 形成悖论.
查看两台机器的时间, 均是正常时间
3 验证:
通过命令
docker swarm ca | openssl x509 -noout -text
查看第二个管理节点证书, 命令报错无法显示证书信息
直接通过谷歌浏览器访问两个节点的 2377 端口 https://x.x.x.x:2377
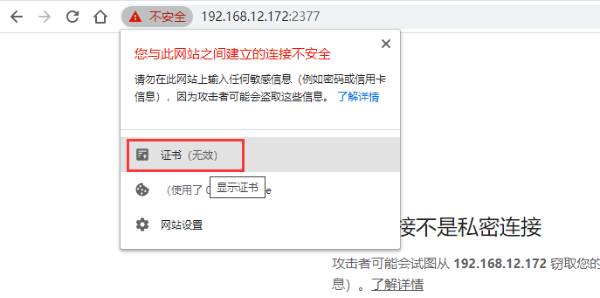
点击证书, 查看证书, 发现有效期不在当前时间范围内, 接着着手更新证书有效期
接着面临问题: 证书在哪存放? 怎么更新? 参考了以下地址的内容:
证书相关 GitHub 上的讨论 https://github.com/moby/moby/issues/34384
4 最终解决:
管理节点二因为证书失效, 直接主动让它离开集群
docker swarm leave --force
管理节点一仍然不正常, 在管理节点一上执行命令
docker swarm init --force-new-cluster --advertise-addr x.x.x.x
发现无法正常执行, 重启了 docker 进程
systemctl restart docker
等待时间较长, 之后再次执行
docker swarm init --force-new-cluster --advertise-addr x.x.x.x
集群恢复正常, 并且之前的部署和配置依然存在, 算是解决了问题
解决 The swarm does not have a leader
标签:man 一个 force eve 错误信息 执行 port 恢复 测试
原文地址:https://www.cnblogs.com/soymilk2019/p/13187001.html