标签:als 大小 type 最大 lxml 数据集 rds com python
不积跬步无以至千里,不积小流无以成江海!每天一点点,以达到积少成多之效!
word2vec----概念,数学原理理解
1.数据集
Kaggle上的电影影评数据,包括unlabeledTrainData.tsv,labeledTrainData.tsv,testData.tsv三个文件
Strange things: kaggle,主要为开发商和数据科学家提供举办机器学习比赛、托管数据库、编写和分享代码的平台。
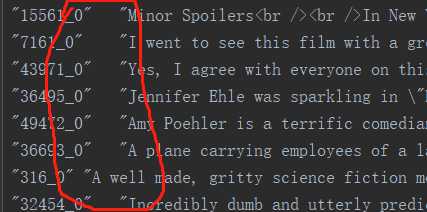
tsv,即tab separated values(制表符分隔值),就是数据集按照一个tab键的空格大小分开的,如下,
csv,即comma separated values(逗号分隔值),csv数据集常见些,就是用逗号分隔的数据集,如下

2.pandas等包的函数理解
Strange things: pandas.DataFrame类似于excel,是一种二维表,DataFrame的单元格可以放数值、字符串等。pandas.DataFrame(data,index,columns,dtype,copy),data:接受的数据的形式,如ndarry,series,map,lists,dict,constant和另一个DataFrame。参考博客(超好理解): https://www.cnblogs.com/IvyWong/p/9203981.html
index:行标签。columns:列标签。dtype:每列的数据类型。copy:若默认值为False,则此命令用于复制数据
BeautifulSoup:和lxml一样,是一个HTML/XML的解析器,主要就是如何解析和提取HTML/XML数据。它自动把输入文档转换为Unicode编码,输出文档转换为utf-8编码
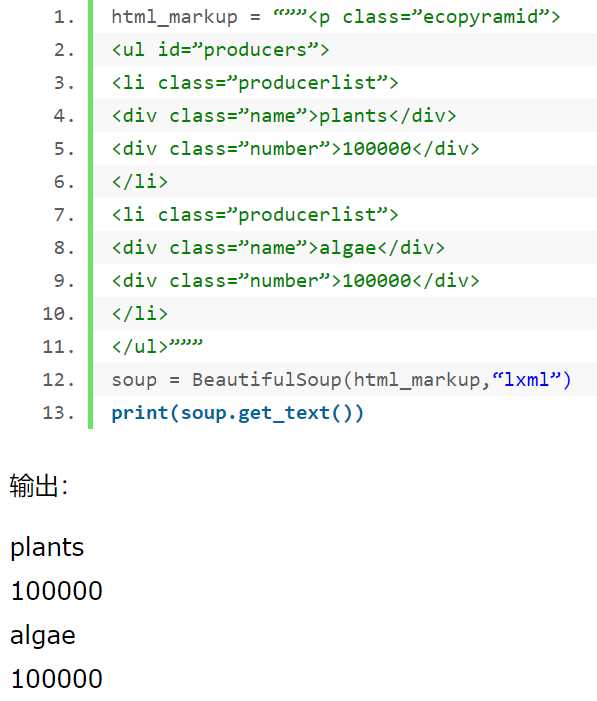
BeautifulSoup.get_text():get_text()方法返回BeautifulSoup对象或标签对象中的文本内容,其为一个Unicode字符串,如https://www.cnblogs.com/eternal1025/p/6866494.html中所示如下
DataFrame.apply(function,axis):对DataFrame里一行或一列做出一些操作(axis=1则为对某一列进行操作,此时,apply函数每次将dataframe的一行传给function,然后获取返回值,将返回值放入一个series),返回一个新的行(列)。参考博客:https://www.cnblogs.com/liulangmao/p/9342806.html https://www.cnblogs.com/liulangmao/p/9355633.html 超详细
pandas.concat([a1,a2,a3],axis=1)连接函数。axis=1:水平连接,axis=0:竖直连接 参考博客(超详细): https://www.cnblogs.com/zknublx/p/9645834.html
3.word2vec理解
先说什么是语言模型?简单说,就是用概率去判断某句话(文本)是否通顺
可参考博客:https://www.cnblogs.com/guoyaohua/p/9240336.html 仔细的看看,如果理解不了统计语言模型,可去看我的另一篇博客 https://www.cnblogs.com/JadenFK3326/p/11964892.html 是我结合上述博客和<<Python自然语言处理实战:核心技术与算法>> 的理解
还有就是神经网络语言模型(NNLM),理解了神经网络语言模型对于理解word2vec有很大 的帮助,对以后的CNN、LSTM进行文本分析也有很大帮助。摘自 https://www.cnblogs.com/xmeo/p/7463946.html
好吧,摊牌了,不装了,对于博客我看的都费劲,看不懂,我太菜了,还好学习统计语言模型,让我高哥(我同门,一数学系大佬过来的)教会了我理解,我又到处搜,好久才定位到百度的关键词(我想要的),但是写的也比较少,我在这把文本如何转为向量重复一下,对于我这样的菜鸟更好的理解一下。下面我说一下我对博客 https://blog.csdn.net/So_that/article/details/92800259 的理解,有错的请点出来,万分感谢。对于该博客的Forward请看我推荐的统计语言模型,就可以理解了,我从他的“回归正题开始”、
博客中假设词典中有10000个词(语料中不重复的词),即V=10000,对词典中的词进行one-hot编码如下
[1 0 0 ... 0 #假如第一个字是“我”,则“我”用[1,0,0, ... ,0]表示
0 1 0 ... 0 #假如第二个字是“是”,第三个字是“中国”,第四个字是“人”
...
0 0 0 ... 1] #万维方阵
博客中假设n=6,我这假设n=3,则n-1=2(其中n和n-gram中的n的意思一样,这里表示仅和前2个词有关系)假设输入为“我是中国人。”分词为“我”“是”“中国""人""。"
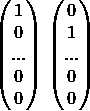
那么,“我”“是”的one-hot向量表示为(此处为列向量表示):
则这两个向量拼成一个2*10000的矩阵,然后乘上投影矩阵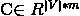 进行降维处理,其中m是自己设定的(假设m=100),则降维后是一个2*100的矩阵。
进行降维处理,其中m是自己设定的(假设m=100),则降维后是一个2*100的矩阵。
博客中设n=6,n-1=5,认为输入5个one-hot向量(仅和前五个词相关),这5个向量拼成一个[5*10000]的矩阵,降维是右乘一个[10000*100]的权重矩阵(即投影矩阵),100为自己设定。此时得到5*100的矩阵,用Z表示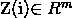 ,表示第
,表示第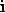 个词对应的特征向量(就是把一开始的5个one-hot稀疏向量转换成了稠密向量)。接着把[5*100]维的向量拼接成一个500维的向量
个词对应的特征向量(就是把一开始的5个one-hot稀疏向量转换成了稠密向量)。接着把[5*100]维的向量拼接成一个500维的向量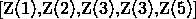 ,用这个向量来表示一个单词,即要预测的词,假如我们要预测第1236个词,则
,用这个向量来表示一个单词,即要预测的词,假如我们要预测第1236个词,则
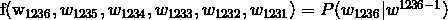
其中,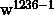 表示从第一个词到第1236个词组成的子序列。
表示从第一个词到第1236个词组成的子序列。
NNLM(神经网络语言模型)的目标是要训练模型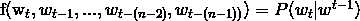 ,即上面公式的一般化表示。
,即上面公式的一般化表示。
模型的前馈式计算:
1.特征映射:即上面所述的把one-hot稀疏向量转换为稠密向量,然后拼接成一个(n-1)*m维的向量。
2.计算概率:把拼接的(n-1)*m维向量输入到函数g中,得到一个概率分布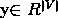 ,这个概率分布在这是10000维(词典里所有词的概率),最大概率的词典中的词即预测的词。
,这个概率分布在这是10000维(词典里所有词的概率),最大概率的词典中的词即预测的词。
模型详解为:
第一步: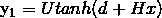 ,即拼接的(n-1)*m维向量输入到此公式
,即拼接的(n-1)*m维向量输入到此公式
即经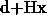 线性变换后,经tanh激活一下得到一个100维向量(
线性变换后,经tanh激活一下得到一个100维向量(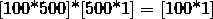 )然后左乘一个U得到一个10000维的向量
)然后左乘一个U得到一个10000维的向量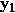 (
(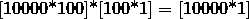 )
)
第二步: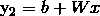 ,即拼接的(n-1)*m维向量输入到此公式
,即拼接的(n-1)*m维向量输入到此公式
即W是一个[10000*500]维的矩阵,Wx: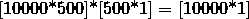 ,b是[10000*1],相加得
,b是[10000*1],相加得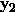
第三步: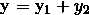 ,得出最终向量即
,得出最终向量即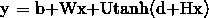 ,然后通过softmax激活函数求概率预测
,然后通过softmax激活函数求概率预测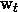
其中,W,U,H都是权重,d,b都是偏置。softmax预测如下(即激活)
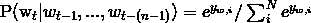
调参(这个公式我还么请教大佬,仅仅查看的博主的):
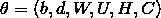 ,C是转化后的稠密向量,非是投影矩阵C。参数调优函数即最大化似然函数L,
,C是转化后的稠密向量,非是投影矩阵C。参数调优函数即最大化似然函数L,
$ L = \frac{1}{T}\sum_{t} logf(w_{t},w_{t-1},...,w_{t-(n-1)};\theta ) + R(\theta ) $
$ R(\theta) $为正则化项,更新参数则采用梯度下降算法(这也是我下步要搞懂的)
$ \theta \leftarrow \theta +\lambda \frac{\partial logp(w_{t}|w_{t-1},...,w_{t-(n-2))},w_{t-(n-1)})}{\partial \theta} $
$\lambda$为学习步长
从统计语言模型开始,到神经网络语言模型,再到word2vec,为什么?解决了什么不足?可参考博客(我老郭家的人写的) https://www.cnblogs.com/guoyaohua/p/9240336.html?utm_source=tuicool&utm_medium=referral
好,我也是好好学了NNLM模型,下面开始word2vec的两个模型:CBoW和Skip-gram
参考博客还有:https://www.cnblogs.com/jiangxinyang/p/9332769.html word2vec的基础是霍夫曼树(学过数据结构的话就知道了,没学过也没啥,超简单) https://www.cnblogs.com/pinard/p/7160330.html 个人感觉这个刘建平博主的博客容易理解些,可以看这个的word2vec原理去学习
Skip-gram模型
以中心词预测上下文词。输入是中心词的one-hot编码形式,隐藏层做线性变换,输出的是sofmax函数激活后的概率
和CBoW模型正好反过来,输入是一个词向量,所以从输入层到投影层(隐藏层)就简单了,然后就是输出层的霍夫曼树了
目标函数(即用的似然函数):$ \prod_{t=1}^{T}\prod_{-m\leq j\leq m,j\neq 0}^{}P(w^{t+j}|w^{t}) $ 目标是要最大化这个目标函数
给定中心词生成背景词的条件概率(对两者的向量做内积,然后做softmax):$ P(w_{o}|w_{c}) = \frac{exp(u_{o}^{T})}{\sum_{i\epsilon V}^{}exp(u_{i}^{T}v_{c}))} $
损失函数:$ -\sum_{t=1}^{T}\sum_{-m\leqslant j\leq m,j\neq 0}^{}logP(w^{t+j}|w^{t}) $ 最大化目标函数就等价于最小化这个损失函数
然后把$ P(w_{o}|w_{c}) $带入损失函数中,分别对要学习的参数进行求导(求导自己学了呀),优化即可。
CBoW模型(Continuous Bag-of-Words Model)
以上下文的词预测中间词。输入是上下文词的one-hot编码,隐藏层对输入值进行了加法运算,无激活函数,输出层和输入层维度一致
https://blog.csdn.net/github_36235341/article/details/78607323
CBoW模型无隐藏层,仅输入层+投影层+输出层,且输出层是一个霍夫曼树,沿着霍夫曼树寻找要预测的词,极大化从根节点走到预测词叶子节点路径上概率相乘的值。霍夫曼树是根据语料库中的词及其频率而建(构建依据:左0(负类)右1(正类))。
类似于Skip-gram模型,不同的是CBoW给定背景词生成中心词的条件概率: $ P(w_{c}|w_{o_{1}},\cdots ,w_{o_{2m}})=\frac{exp(\frac{1}{2m}u_{c}^{T}(v_{o_{1}},\cdots ,v_{o_{2m}}))}{\sum_{i\epsilon V}^{}exp(\frac{1}{2m}u_{i}^{T}(v_{o_{1}},\cdots ,v_{o_{2m}}))} $
为了公式简洁,令$ W_{o}=\left \{ w_{o_{1}},\cdots ,w_{o_{2m}} \right \} $, $ \bar{v_{o}}=\frac{v_{o_{1}}+\cdots +v_{o_{2m}}}{2m} $
那么CBoW给定背景词生成中心词的条件概率公式则可写为:$ P(w_{c}|W_{o})=\frac{exp(u_{c}^{T}\bar{v_{o}})}{\sum_{i\epsilon V}^{}exp(u_{i}^{T}\bar{v_{o}})} $
目标函数:$ \prod_{t=1}^{T}P(w^{t}|w^{t-m},\cdots ,w^{t-1},w^{t+1},\cdots ,w^{t+m}) $
损失函数:$ -\sum_{t=1}^{T}logP(w^{t}|w^{t-m},\cdots ,w^{t-1},w^{t+1},\cdots ,w^{t+m}) $
然后同样是对损失函数中需要优化的参数进行求导,然后优化。。。
由于篇幅已经挺长了,代码实现写在后面的博客中。。。如果有错误,请在下面评论区提出来,咱们共同学习
标签:als 大小 type 最大 lxml 数据集 rds com python
原文地址:https://www.cnblogs.com/JadenFK3326/p/11871745.html