标签:fir 安装包 关闭 平台 访问 个数 wget 节点 项目
kafka是什么
Kafka最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调
的,发布/订阅模式的消息队列(Message Queue),Linkedin于2010年贡献给了Apache基金会并成
为顶级开源项目。
经过多年发展,Kafka已经由最初的日志分发系统的一个模块,发展为一个通用的分布式消息队列,大
有发展成为一个流处理平台的趋势。
目前主要应用于大数据实时处理领域,作为分布式消息队列来使用,因此本课程主要聚焦于Kafka作为
分布式消息队列的方方面面。
Kafka主要设计目标如下:
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问
性能。
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
支持Kafka Server(Kafka Broker)间的消息分区,及分布式消费,同时保证每个partition内的消息
顺序传输。
同时支持离线数据处理和实时数据处理。
Scale out:支持在线水平扩展
官网:
http://kafka.apache.org/
Kafka安装
#安装Linux下的多线程下载工具
wget http://download-ib01.fedoraproject.org/pub/epel/7/x86_64/Packages/a/axel-2.4-9.el7.x86_64.rpm
sudo rpm -ivh axel-2.4-9.el7.x86_64.rpm
#下载Kafka安装包
axel -n 15 https://archive.apache.org/dist/kafka/2.0.0/kafka_2.12-2.0.0.tgz
集群部署
安装
在node01上
mkdir app
cd app
mv ~/kafka_2.12-2.0.0.tgz .
tar -zxf kafka_2.12-2.0.0.tgz
ln -s kafka_2.12-2.0.0 kafka
修改配置
在node01上:
编辑配置文件
vi /home/hadoop/app/kafka/config/server.properties
主要配置项如下:
#broker 的全局唯一编号,不能重复(拷贝到其他节点是必须修改)
broker.id=0
#是否允许删除topic
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#存放kafka log,所谓的log是指的数据,不是我们通常理解的那个log
log.dirs=/home/hadoop/app/kafka/data
#topic默认分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=node01:2181/kafka_2_0_0
分发到各个节点
通过scp把kafka分发到node02和node03。
修改broker.id
在node02-node03上分别把配置文件中的 broker.id改为1和2。
创建数据目录
创建目录用于kafka存放log(所谓的log是指的数据,不是我们通常理解的那个log):
在node01-node03上:
mkdir /home/hadoop/app/kafka/data
配置环境变量
在node01-03上
sudo vi /etc/profile
#KAFKA_HOME export KAFKA_HOME=/home/hadoop/app/kafka export PATH=$PATH:$KAFKA_HOME/bin
保存退出,使环境变量
source /etc/profile
启动集群
在node01-node03上
cd $KAFKA_HOME
bin/kafka-server-start.sh -daemon config/server.properties
关闭集群
在node01-node03上
cd $KAFKA_HOME
bin/kafka-server-stop.sh stop
执行命令行
#查看topic列表 kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --list #创建topic kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --create --replication-factor 3 --partitions 1 --topic first #删除topic kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --delete --topic first #控制台发送消息 kafka-console-producer.sh --broker-list node01:9092 --topic first #控制台消费消息 kafka-console-consumer.sh --bootstrap-server node01:9092 --topic first #查topic详情 kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --describe --topic first

控制台发送消息
修改kafka的配置文件
在node01-03上配置
vi /home/hadoop/app/kafka/config/server.properties
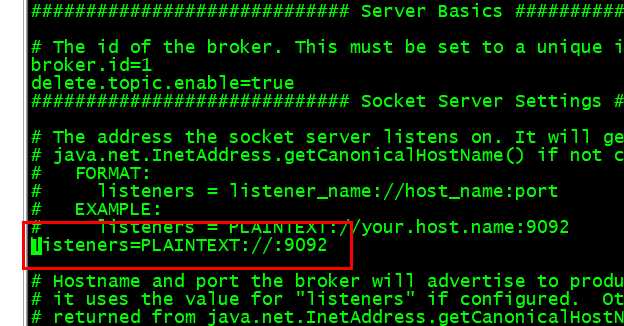
重启一下kafka
启动生产者

启动消费者

数据来源这生产者的

查topic详情

标签:fir 安装包 关闭 平台 访问 个数 wget 节点 项目
原文地址:https://www.cnblogs.com/braveym/p/13190897.html