标签:初始化 oba sed 就是 语义 平滑 image 增加 图片
现有的基于深度学习的图像修补方法在损坏的图像上使用标准卷积网络,使用卷积滤波器响应以有效像素以及掩蔽孔中的替代值(通常为平均值)为条件。 这通常会导致诸如颜色差异和模糊等伪影。 后处理通常用于减少这些工件,但代价很高,可能会失败。 我们提出使用部分卷积,部分卷积指的是卷积只在图片的有效区域进行(mask部分为0),并且图片的mask会随着网络的层数加深不断迭代和收缩,也就是说带有mask的图片和mask均参与训练,取得了很好的效果。

图. 从左到右,从上到下:2(a):带孔的图像。 2(b):PatchMatch [3]的修复结果。 2(c):Iizuka等人的修改结果[1]。 2(d):余等人[2]。 2(e)和2(f)使用与3.2节相同的网络架构,但使用典型的卷积网络,2(e)使用像素值127.5初始化空洞。 2(f)使用平均ImageNet像素值。 2(g):我们基于部分卷积的结果与孔值无关。
目前由于图片中孔的大小不同会带来不同的补全伪影,所以现在的方法都会在网络预测之后再加上后处理过程:
传统方法,基于邻近像素,只能解决小mask的问题,并且mask区域的像素需要和周围像素差不多:
基于深度学习的图像补全方法:
和本文相似的一些做法:
本文的主要贡献在于:使用PConv对于带有mask的图像进行操作,因为PConv可以对于mask的周围区域进行预测,换句话说在一层PConv中,mask的周围可以产生一些有效值。基于所产生的有效值可以对于mask进行收缩,在进入decoder阶段之前,只要网络深度足够,mask区域大小可以收缩到0。加入mask update仅仅是为了标记哪些值是有效的(因为输入的图片大小和mask大小是一样的,卷积核大小也是一样的,唯一不同是:图片的卷积核会不断更新,mask的卷积核永远为1)。
我们提出的模型使用堆叠的部分卷积运算和掩膜更新步骤来执行图像修复。我们首先定义我们的卷积和掩膜更新机制,然后讨论模型架构和损失函数。
为简洁起见,我们将部分卷积运算和掩膜更新函数联合称为部分卷积层。
设W是卷积滤波器的权重,b是相应的偏差。 X是当前卷积(滑动)窗口的特征值(像素值),M是相应的二进制掩膜。每个位置的部分卷积被表示为:
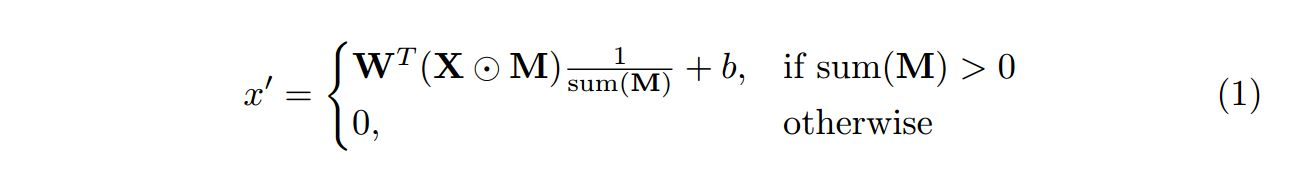
其中⊙表示单元乘法。 可以看出,输出值仅取决于非屏蔽输入。 比例因子1/sum(M)应用适当的缩放比例来调整有效(未屏蔽)输入的变化量。
在每次部分卷积操作之后,我们将更新我们的掩膜。 我们的屏蔽规则很简单:如果卷积能够在至少一个有效输入值上调整其输出,则我们移除该位置的掩膜。 这表示为:

并且可以在任何深度学习框架中轻松实施,作为正向传球的一部分。在部分卷积层有足够的连续应用的情况下,如果输入包含任何有效像素,则任何掩膜将最终全部为1。
网络结构类似于U-net,encoder阶段使用ReLU,decoder阶段用LeakyReLU,alpha=0.2。BN用在除了第一层encoder和最后一层decoder之外的所有层。
部分卷积作为填充,当图像边界附近时,我们不使用任何现有的填充方案来卷积。相反,部分卷积层直接通过适当的掩膜处理。这将进一步确保图像边界上的修复内容不会受到图像外部无效值的影响,这可以解释为另一个漏洞。
$I_{in}$: 带有mask的图片(需要补全的图片)
$I_{out}$:网络预测输出的图片
M:二值mask(有洞区域是0)
$I {gt}$:Ground Truth
$I{comp}$:将预测图片没有洞区域的像素替换为GT之后的图片
$Ψ_n$:预训练模型(VGG16)第n层激活后的特征图,文章选的是三个pooling层
$K_n$:系数,等于1/(Cn?Hn?Wn)1/(C_nH_nW_n)1/(C
Pixel Loss:
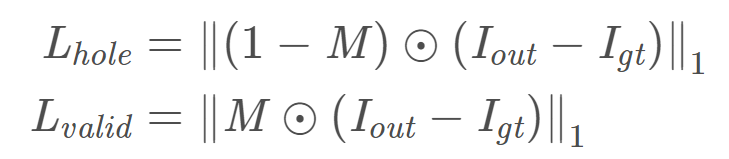
Perceptual Loss:
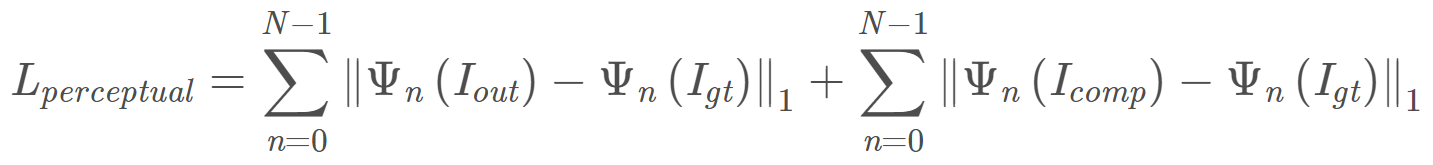
Style Loss:
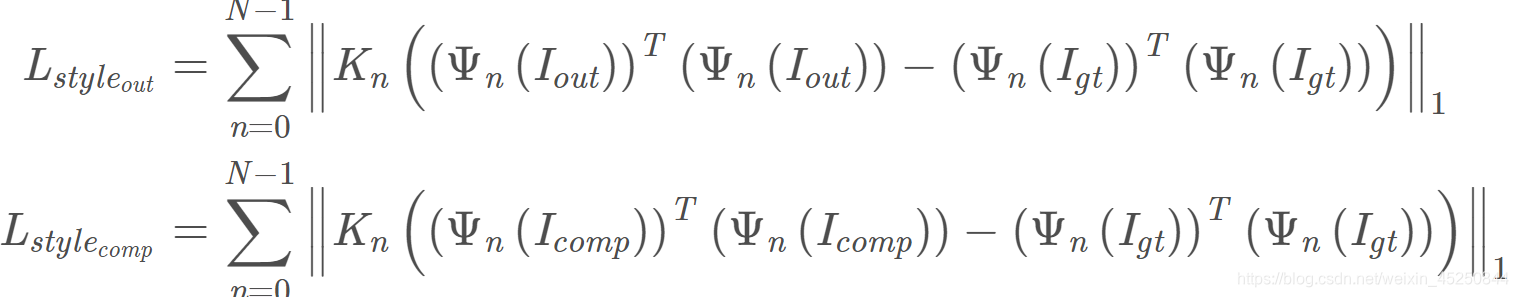
Total Variation Loss:
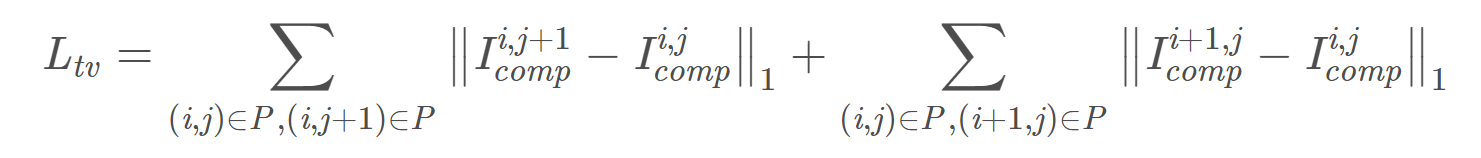
这里P是有洞区域。
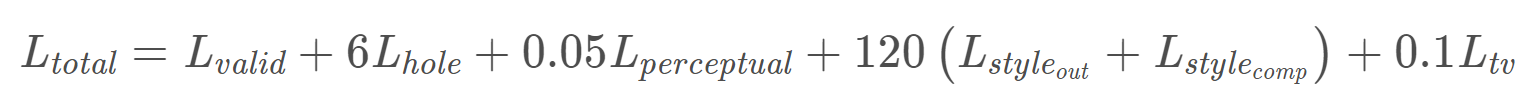
Style Loss很重要,有助于解决鱼鳞纹和棋盘格噪声,权重不能太小,但是权重太大的话会损失高频信息。
去除棋盘伪影和鱼鳞伪影 已知感知丢失[28]会产生棋盘伪影。 Johnson等人[28]建议通过使用总变差(TV)损失来改善问题。我们发现这不是我们模型的情况。图3(b)显示了移除Style Loss而训练的模型的结果。对于我们的模型,额外的样式损失项是必要的。然而,并非所有的风格损失的权重计划都会产生合理的结果。图3(f)显示了用小的损失权重训练的模型的结果。与图3(g)中完整Loss训练模型的结果相比,它具有许多鱼鳞伪影或块状棋盘伪影。最终,风格损失的权重太大会导致高频信息的丢失。我们希望这个讨论会对那些有兴趣使用基于VGG的高层次损失的读者有所帮助。

先前的作品通过随机移除图像中的矩形区域在其数据集中生成空洞。我们认为这不足以创造我们需要的不同孔洞形状和大小。因此,我们首先收集随机条纹和任意形状的孔的蒙版。我们发现在[29]中描述的视频的两个连续帧之间的遮挡/遮挡遮罩估计方法的结果是这样的图案的良好来源。我们为训练产生了55116个掩膜,并为测试产生了24866个掩膜。在训练期间,我们通过从55116个掩膜中随机采样一个掩膜并随后进行随机扩张,旋转和裁剪来增加掩膜数据集。所有用于训练和测试的掩膜和图像尺寸为512×512。
我们从24866个掩膜开始并添加随机扩张,旋转和裁剪来创建测试集。许多先前的方法如[1]在图像边界附近的孔处的性能下降。因此,我们将测试集分为两个:带有和不带有孔的边界的边界。具有远离边界的孔的分割确保距离边界至少50个像素的距离。
我们还根据孔的大小进一步分类我们的口罩。具体而言,我们生成了6种不同孔 - 图面积比的掩膜:(0.01,0.1],(0.1,0.2],(0.2,0.3],(0.3,0.4],(0.4,0.5],(0.5 ,0.6],每个类别包含1000个带和不带边界约束的掩膜,总共创建了6 * 2 * 1000 = 12,000个掩膜,每个类别掩膜的一些例子可以在图4中找到。

TODO
TODO
我们建议使用具有自动掩膜更新机制的部分卷积层并实现最新的图像修复结果。我们的模型可以稳健地处理任何形状,大小的位置或与图像边界的距离。此外,如图10所示,我们的性能不会随着孔的大小增加而发生灾难性的恶化。然而,我们的方法的一个局限性在于,它对于一些结构疏松的图像(例如图11中的门上的条)大多数方法,在最大的孔上挣扎。


我们还通过偏移像素和插入图像将我们的框架扩展到图像超分辨率任务。具体来说,给定具有高度H和宽度W以及放大系数K的低分辨率图像I,我们使用以下方式构造具有高度K * H和宽度K * W的输入I‘:对于I中每个像素(x, y),我们把它放在I‘中的(K * x +?K/2?,K * y +?K/2?),并将该位置标记为掩膜值为1.一个示例输入设置和相应的输出K = 4可以在图12中找到。我们比较图13中K = 4的两种众所周知的图像超分辨率方法SRGAN [37]和MDSR + [38]。

图像修复之Image Inpainting for Irregular Holes Using Partial Convolutions
标签:初始化 oba sed 就是 语义 平滑 image 增加 图片
原文地址:https://www.cnblogs.com/ai-tuge/p/13191387.html