标签:统计 生成 参考资料 data nta 有一个 常用 了解 添加
本文示例代码及数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
在基于geopandas的空间数据分析系列文章第8篇中,我们对geopandas开展空间计算的部分内容进行了介绍,涉及到缓冲区分析、矢量数据简化、仿射变换、叠加分析与空间融合等常见空间计算操作,而本文就将针对geopandas中剩余的其他常用空间计算操作进行介绍。
本文是基于geopandas的空间数据分析系列文章的第9篇,也是整个系列文章主线部分内容的最后一篇,通过本文,你将学习到geopandas中的更多常用空间计算方法。
承接上文内容,geopandas中封装的空间计算方法除了系列上一篇文章中介绍的那几种外,还有其他的几类,下面我们继续来学习:
类比常规表格数据的连接操作,在空间数据分析中也存在类似表连接的操作,譬如我们手头有一张包含设施点数据的矢量表,以及另一张包含行政区划面数据的矢量表,当我们想要通过某些操作来统计出每个行政区划面内部的设施点信息时,空间连接就可以非常方便快捷地实现这类需求。
我们都清楚常规表格数据的连接,是按照设定的连接方式,将每张表中指定的某列或某些列数值相等的记录行合并为同一行,最后汇整成连接结果表返回:

而空间连接不同于常规表连接,其合并同一行的依据不是检查指定的列数值是否相等,而是基于不同矢量表其矢量列之间的空间拓扑关系,譬如相交、包含等。
在geopandas中我们利用sjoin函数来实现空间连接,其使用方式类似pandas中的merge接近,主要参数如下:
left_df:GeoDataFrame,传入空间连接对应的左表
right_df:GeoDataFrame,传入空间连接对应的右表
how:字符型,用于决定连接方式,
‘inner‘表示内连接,且连接结果表中的矢量列来自左表;‘left‘表示左连接,且结果表中的矢量列来自左表;‘right‘表示右连接,最终结果表中的矢量列来自右表op:字符型,用于设定拓扑判断的规则,
‘intersects‘代表相交,即几何对象之间存在共有的边或内部点;‘contains‘代表包含,即一个几何对象至少有一个点位于另一个几何对象内部,且其本身没有任何点落在另一个结几何对象的外部;‘within‘表示在内部,是‘contains‘的相反情况,即左表被右表矢量‘contains‘lsuffix:字符型,代表当左右表连接之后存在重名列时,为左表重名的列添加的后缀,默认为
‘left‘rsuffix:字符型,意义类似lsuffix,默认为
‘right‘
了解过sjoin()中的核心参数后,我们来通过实际例子理解它们的具体作用,how的作用与pandas中效果的一致,这里不多解读,我们来重点学习op各参数的不同效果:
intersects是空间连接中最常使用的模式,即相比较的两个几何对象有至少1个公共点就会被匹配上,下面我们以柏林公交站点数据为例,首先我们先读入柏林行政区划面数据,其中字段Gemeinde_n是每个行政区划的名称:
# 读入柏林行政区划面文件
Berlin = gpd.read_file(‘Berlin/Bezirke__Berlin.shp‘)
Berlin.head() # Gemeinde_n代表镇,即Berlin中每个面文件对应的行政区划名称

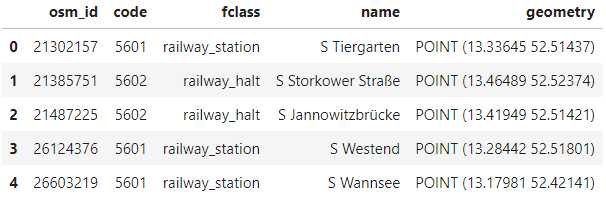
接着再读入柏林全部交通车站数据,其中fclass列代表对应车站的类别:
Berlin_transport = gpd.read_file(‘Berlin/gis_osm_transport_free_1.shp‘)
Berlin_transport.head()
对站点的空间分布进行可视化:
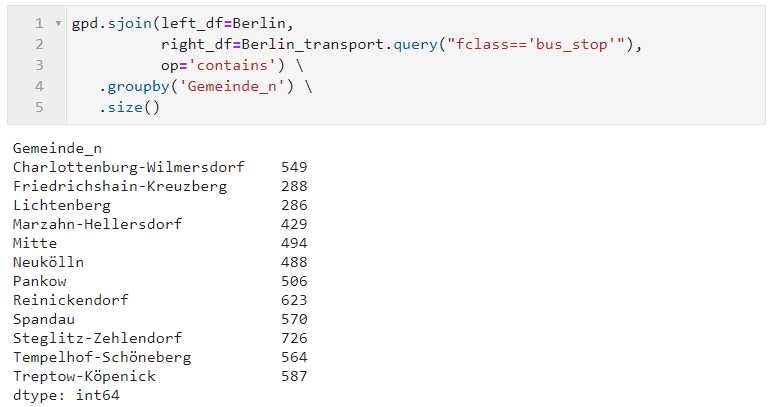
接着我们就利用sjoin()将区划面作为左表,站点作为右表,在op=‘intersects‘参数设置下进行空间连接,再衔接groupby,以统计出各区划面内部的公交站点数量:
gpd.sjoin(left_df=Berlin,
right_df=Berlin_transport.query("fclass==‘bus_stop‘"),
op=‘intersects‘) .groupby(‘Gemeinde_n‘) .size()

再设置op=‘contains‘,因为进行连接的对象是左表面要素,右表点要素,所以这里的效果等价于op=‘intersects‘:
但当op=‘within‘时,按照拓扑规则,如果依旧是左表面要素,右表点要素,得到的结果就会为空,反过来则正常:

类似的,其他类型几何对象之间的空间连接你也可以根据自己的需要进行操作,值得一提的是,利用sjoin()进行空间左、右、内连接时,因为结果表依旧是GeoDataFrame,所以只会保留一列矢量列,按照上文中参数介绍部分的描述,只有右连接时结果表中的矢量列才来自右表,但无论采取什么连接方式,结果表中未被保留的矢量列对应的index会被作为单独的一列保存下来,帮助我们可以按图索骥利用loc方式索引出需要的数据:
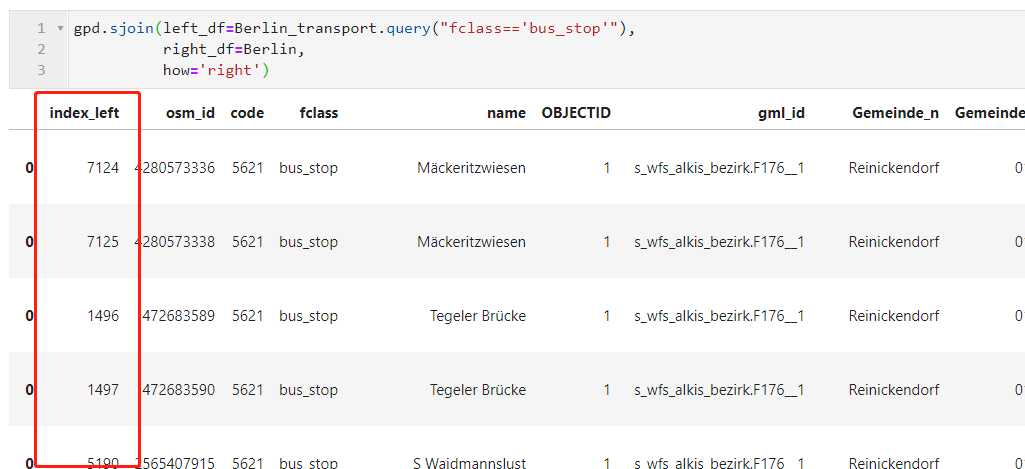
geopandas中除了在上一篇文章中介绍的叠加分析以及上文介绍的空间连接中基于拓扑关系判断实现多表数据联动之外,还针对GeoSeries与GeoDataFrame设计了一系列方法,可以直接进行矢量数据之间的拓扑关系判断并返回对应的bool型判断结果,以contains()为例,在比较矢量数据之间拓扑关系时,矢量数据与待比较矢量数据之间主要有以下几种格式:
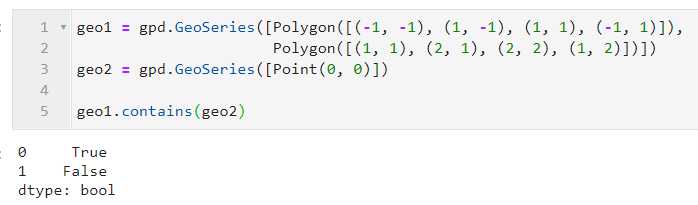
当主体矢量列长度为n,而输入待比较的矢量列长度为1时,返回的bool值是待比较矢量列与主题矢量列一一进行比较后的结果:
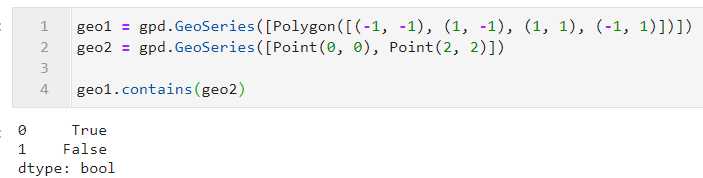
与前面一种情况类似,只不过这里是将主体矢量列与待比较矢量列一一比较之后的结果:
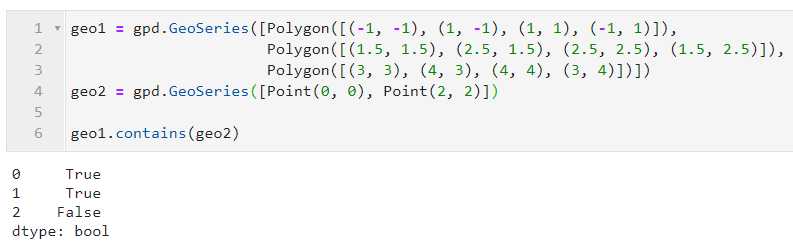
这里所说的情况指主体矢量与待比较矢量长度都不为1,且主体矢量列的长度大于待比较矢量,这时返回的结果只会对主体矢量列前m-n个要素与待比较矢量对应位置一一比较,主体矢量被截断未能进行比较的部分默认返回False:
这时的情况就与前面一种类似,即从头开始两两位置匹配上的要素才会进行比较及结果的输出,多出的得不到匹配的要素会自动返回False:
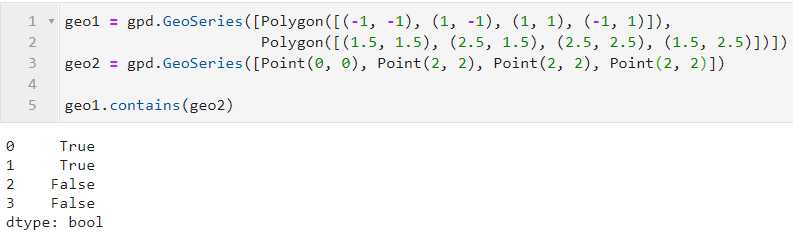
geopandas中进行拓扑关系判断的基本原则了解完了,下面罗列出常用的一些拓扑关系判断API,均为GeoSeries或GeoDataFrame的方法:
intersects():检查相交关系
contains():检查包含关系,即主体矢量完全包裹住待比较的矢量且它们的边界互不接触,譬如面对点的包含
within():检查主体矢量是否在待检查矢量的内部
touches():检查触碰关系,即两个矢量之间至少有一个1个公共点,但它们的内部无任何相交区域
crosses():检查交叉关系,常见如线与线之间的交叉
disjoint():检查不相交关系,即两个矢量之间没有任何接触
geom_equals():检查是否完全相同
overlaps():检查重叠关系
在空间数据分析中,裁切也是非常常用的操作,譬如我们想要获取某个公交站周围500米半径内部的路网矢量,就可以使用到裁切。
在geopandas中我们可以使用clip()函数来基于蒙版矢量对目标矢量进行裁切,其主要参数如下:
gdf:
GeoDataFrame或GeoSeries,代表将要被裁切的矢量数据集mask:
GeoDataFrame、GeoSeries或shapely中的Polygon、Multi-Polygon对象,代表蒙版矢量keep_geom_type:同叠加分析
overlay中的同名参数
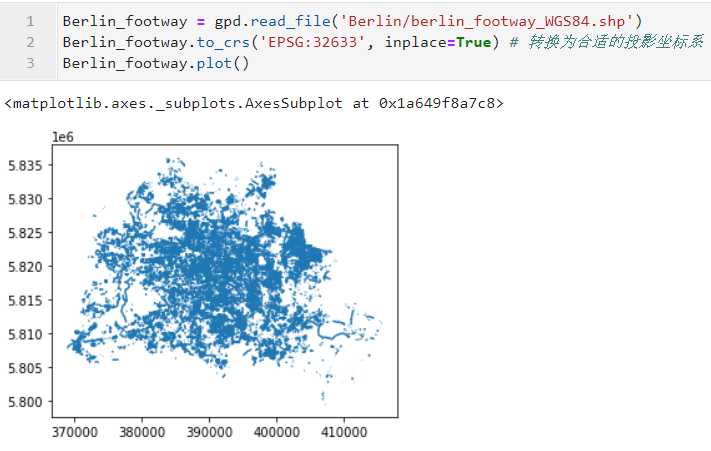
基于实际例子进行演示,我们读入数据berlin_footway_WGS84.shp,包含了柏林全部的步道路网线数据,并转换到适合柏林地区的投影EPSG:32633:
接下来我们从上文中使用到的柏林车站点数据中筛选出租车站点,与步道路网数据统一坐标参考系,生成500米缓冲区,并利用上一篇文章中介绍过的unary_union来得到MultiPolygon对象:

万事俱备,接下来我们使用clip()来裁切所有出租车站点500米缓冲区内部的步行道路网:
# 裁切所有出租车站点500米缓冲区内部的路网线数据
taxi_station_500buffer_roads = gpd.clip(gdf=Berlin_footway,
mask=taxi_station_500_buffer)
在交互模式下同时绘制出缓冲区以及裁切出的路网:
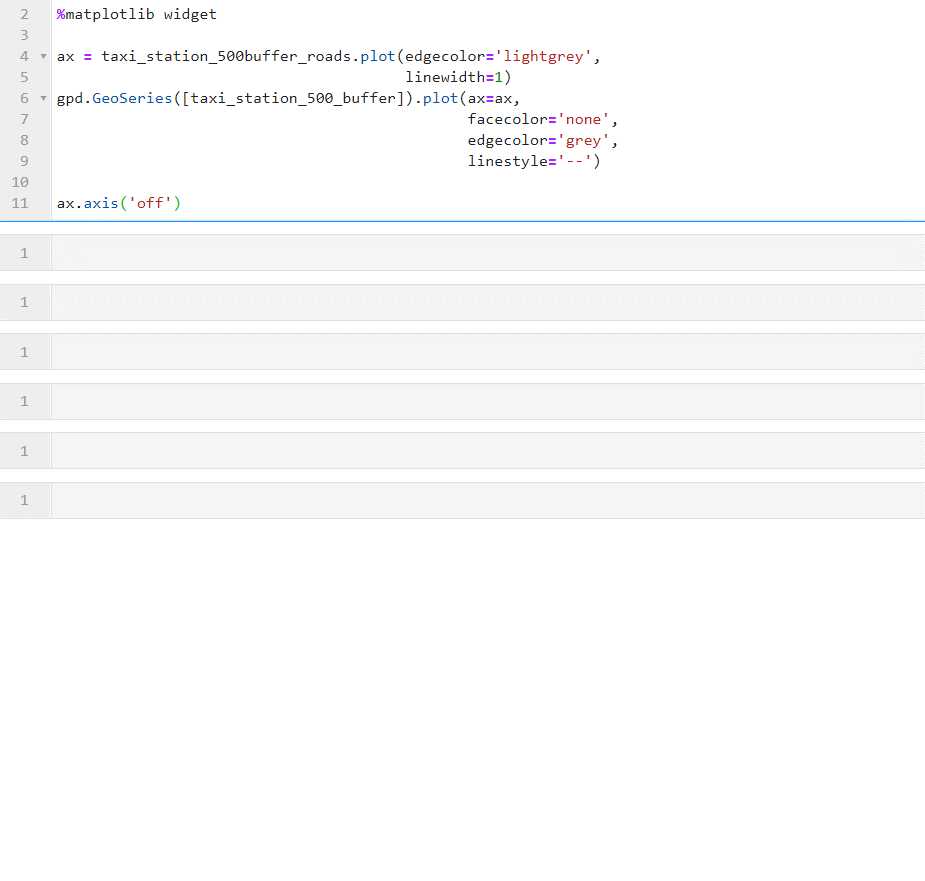
可以看出我们需要的道路网都被正确裁切出来。
需要注意的是,clip()中的mask参数,即蒙版矢量,无论是GeoDataFrame还是GeoSeries亦或是纯粹的shapely矢量,在执行裁切时,都会被整合为一个矢量对象整体,因此与之前文章介绍过的overlay()叠加分析有着本质上的不同。
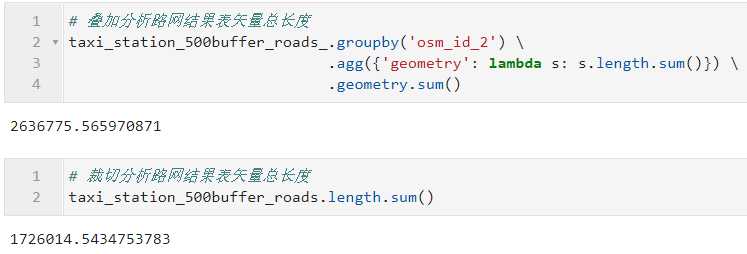
举个实际的例子,当我们想算出整个柏林被出租车站点500米缓冲区所覆盖的步道路网总长度时,可以在上文裁切计算结果的基础上直接求得:

但当我们想要针对每个站点求出各自500米缓冲区内部的步道路网长度时,就需要叠加分析,因为叠加分析的矢量叠置操作是在df1与df2各自行元素两两之间建立起的:

查看裁切与叠加分析分别结果表路网矢量总长度也可以看出叠加分析中的结果是针对每个站点分别计算的,因此对于彼此重叠的站点500米缓冲区就会出现重复重叠的路段:
从2020年2月8日发布了geopandas空间数据分析系列第一篇文章,到今天这篇为止,geopandas中全部实用的主线内容(截至0.7.0版本),都在这断断续续撰写完成的9篇文章中介绍完毕,不敢说是geopandas中文资料里最好的,但穿插了众多例子和举一反三的内容,绝对是帮助大家理解学习geopandas非常实在的参考资料。
撰写本系列文章的初衷,一是因为我对pandas的高度熟悉,二是由于喜欢编程,对ArcGIS之类主要靠点击相应按钮完成任务且容易出错的空间分析软件不太喜欢,所以在了解到有这么一个与pandas有着莫大渊源且可以做很多实用的空间计算操作的Python库时,萌发出浓郁的学习兴趣,便将整个对geopandas相关内容学习精进的过程记录下来,通过博客与微信公众号与广大的读者朋友共同交流学习,期间认识了很多业内大牛和朋友,收获了很多很多。
geopandas是一个非常优秀的工具,它给了我们进行空间计算的多一种选择,我目前所有工作中涉及到的可以用geopandas解决的问题,都会在jupyter中建立顺滑的工作流。geopandas也是一个不断发展不断迭代优化的开源项目,本系列主线内容虽已完结,但之后关于geopandas相关的新特性或额外知识,依旧会不定期作为系列文章的补充,总结发布出来与大家分享。
与热爱的技术一起成长??。
(数据科学学习手札88)基于geopandas的空间数据分析——空间计算篇(下)
标签:统计 生成 参考资料 data nta 有一个 常用 了解 添加
原文地址:https://www.cnblogs.com/feffery/p/13129271.html