标签:connect tiny code width src tin string 搭建 文件
一、安装
一、课前准备
1. 安装好hadoop2.X版本的三节点集群,并配置好JAVA_HOME和HADOOP_HOME两个环境变量。
二、课堂主题
讲解hive1.2.2版本的三种常见安装部署模式
三、课堂目标
1. 熟练搭建内嵌式hive环境
2. 熟练搭建本地式hive环境
3. 熟练搭建远程式hive环境
4. mysql数据库的安装
四、知识要点
================================================================================
hive-1
一、课前准备
1. 安装好对应版本的hadoop集群
2. 安装mysql服务
二、课堂主题
本课堂主要围绕hive的基础知识点进行讲解。主要包括以下几个方面
1. hive的核心概念
2. hive与数据库的区别
3. hive的架构原理
4. hive的安装部署
5. hive的交互方式
6. hive的数据类型
7. hive的DDL语法操作
三、课堂目标
1. 理解hive的核心概念和架构原理
2. 掌握hive的优缺点
3. 掌握hive的安装部署
4. 掌握hive的交互式方式使用
5. 掌握hive的数据类型
6. 掌握hive的DDL语法操作
四、知识要点
1. Hive是什么
1.1 hive的概念
Hive:由Facebook开源,用于解决海量结构化日志的数据统计
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将Hive SQL转化为MapReduce程序
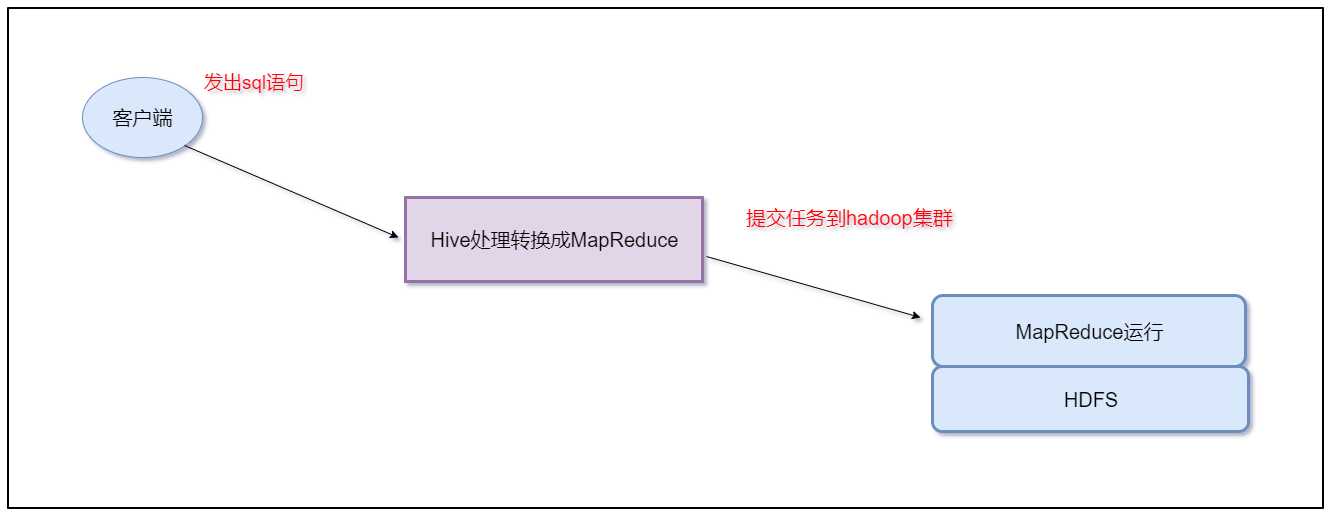
1.2 Hive与数据库的区别
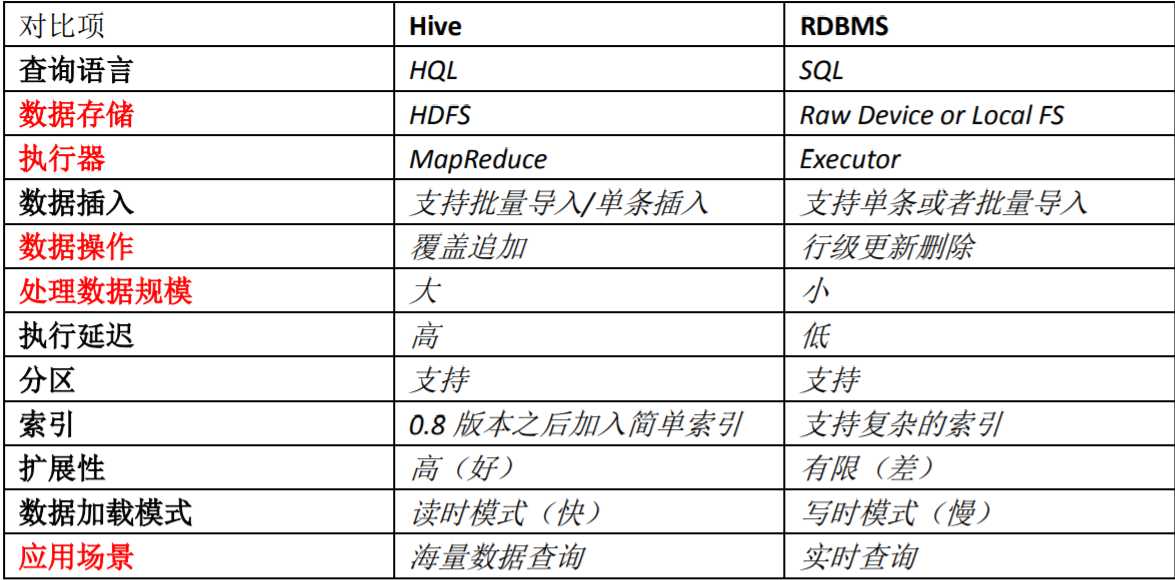
读时模式:hive加载数据到表中的时候,不会进行数据校验
写时模式:mysql加载数据的时候会进行严格校验
1.3 Hive的优缺点
优点
缺点:
1.4 Hive架构原理
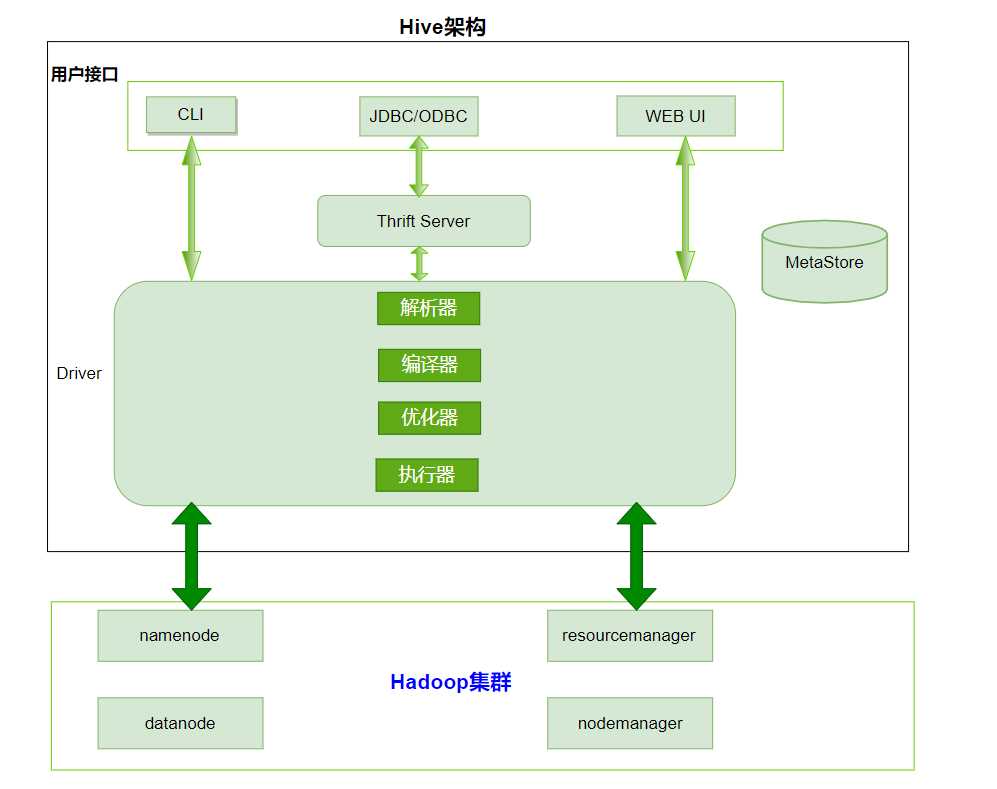
1、用户接口:Client
Clit(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2、元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)
、表的数据所在目录等
默认存储在自带的derby数据库中,推荐使用mysql存储Metastore
3、Hadoop集群
使用HDFS进行存储,使用MapReduce进行计算
4、Driver:驱动器
解析器(SQL Parser)
将SQL字符串转换成抽象语法树AST
对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
编译器(Physical Plan):将AST编译生成逻辑执行计划
优化器(Query Optimizer):对逻辑执行计划进行优化
执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说默认就是mapreduce任务
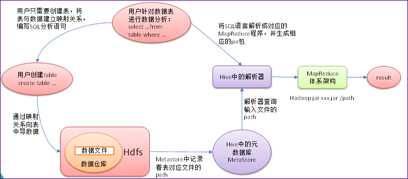
2. Hive的安装部署
注意hive就是一个构建数据仓库的工具,只需要在一台服务器上安装就可以了,不需要在多台服务器上安装
3. hive的交互方式
3.1 hive交互shell
3.2 hive jdbc服务
启动hiveserver2服务
beeline连接hiveserver2
beeline
!connect jdbc:hive2://node1:10000
3.3 Hive的命令
使用 -e参数来直接执行hql的语句
使用 -f 参数执行包含hql语句的文件
4. Hive的数据类型
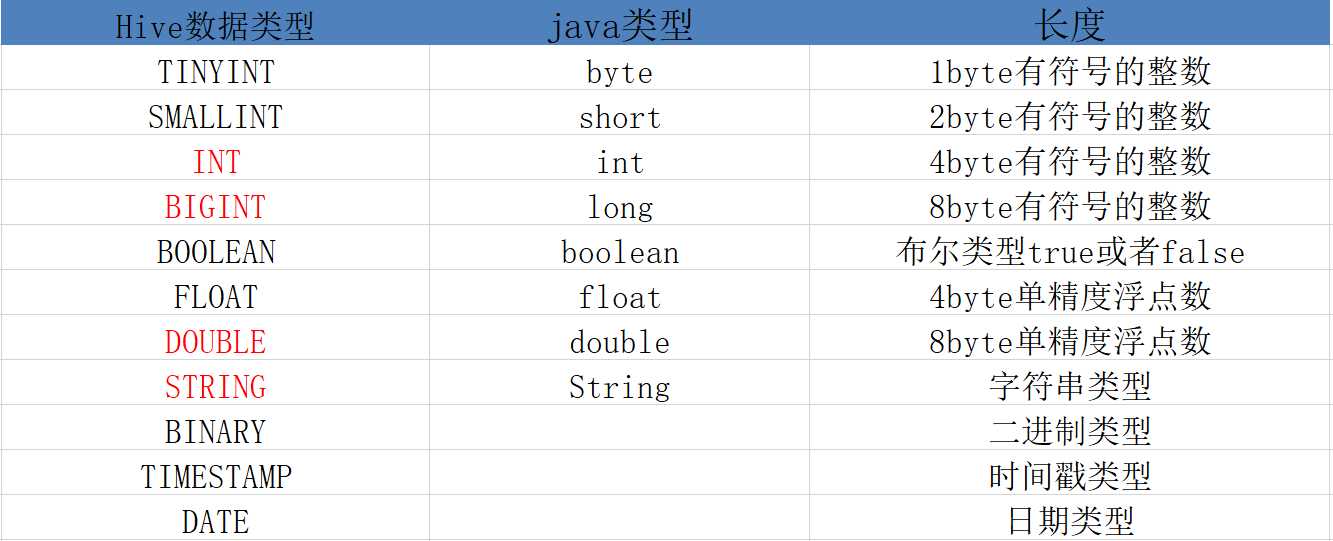
4.1 基本数据类型
4.2 复合数据类型
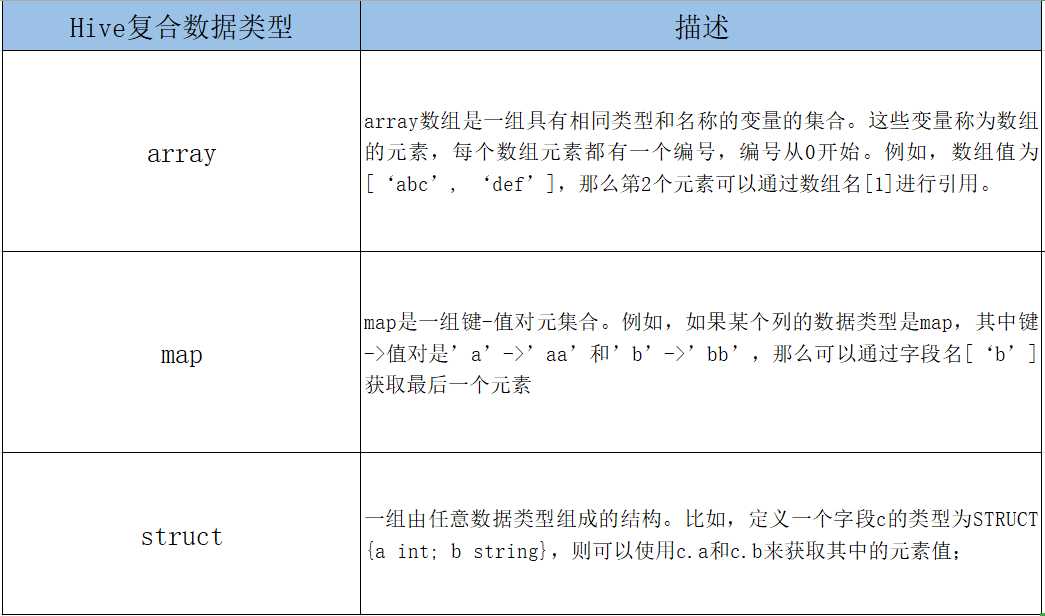
array字段的元素访问方式:
下标获取元素,下标从0开始
获取第一个元素
array[0]
map字段的元素访问方式
通过键获取值
获取a这个key对应的value
map[‘a‘]
struct字段的元素获取方式
定义一个字段c的类型为struct{a int;b string}
获取a和b的值
使用c.a和c.b获取其中的元素值
这里可以把这种类型看成一个对象
5、Hive的数据类型转换
5.1 隐式类型转换
系统自动实现类型转换,不需要用户干预
如tinyint可以转换成int,int可以转换成bigint
所有整数类型、float和string类型都可以隐式地转换成double
tinyint、smallint、int都可以转换为float
boolean类型不可以转换为任何其它的类型
5.2 手动类型转换
可以使用cast函数操作显示进行数据类型转换
cast(‘1‘ as int) 将把字符串 ‘1’转换成整数1;
如果强制类型转换失败,如执行cast(‘x’ as int) ,表达式返回空值NULL
6、Hive的DDL操作
如果数据库中有表存在,这里需要使用cascade强制删除数据库
drop database if exists db_hive cascade ;
。。。。。。中间很无聊,不写了
五、拓展点
hive cli命令窗口查看本地文件系统
与操作本地文件系统类似,这里需要使用!(感叹号),并且最后需要加上 ;分号
例如:
!ls / ;
hive cli命令窗口查看HDFS文件系统
与查看HDFS文件系统类似
dfs -ls / ;
hvie的底层执行引擎有3种
MapReduce(默认)
tez(支持DAG作业的计算框架)
spark(基于内存的分布式计算框架)
标签:connect tiny code width src tin string 搭建 文件
原文地址:https://www.cnblogs.com/hanchaoyue/p/13193475.html