标签:minor 多线程 cti 年龄 结构 对象 复制算法 reads 组成
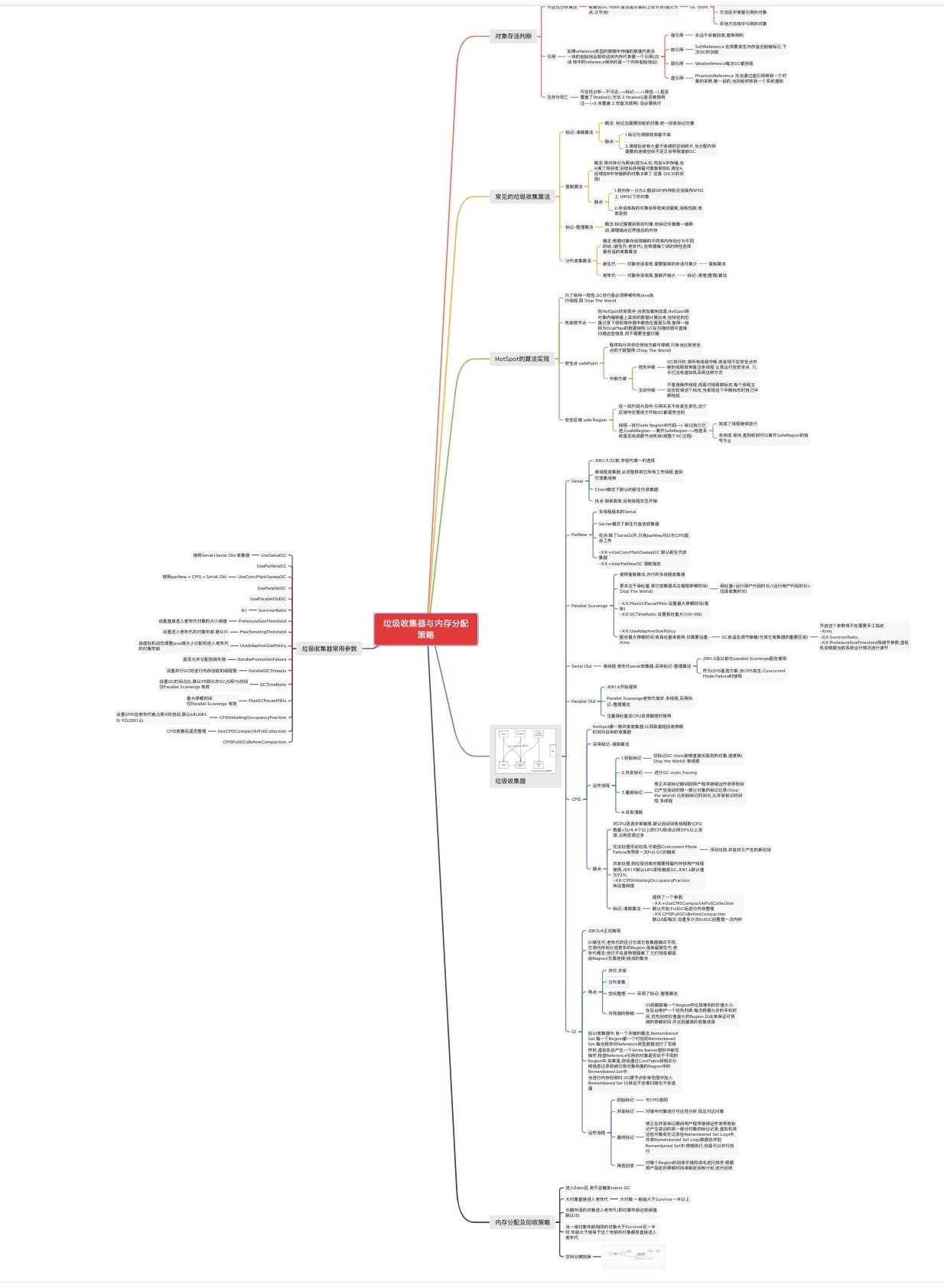
对象是否可到达GC roots
或者说GC roots 是否是对象的上层节点(祖父节点,父节点)
GC roots
如果reference类型的数据中存储的数值代表另一块的起始地址就称这块内存代表着一个引用(白话:栈中的reference保存的是一个内存起始地址)
强引用
软引用
弱引用
虚引用
概念: 标记出需要回收的对象,统一回收标记对象
缺点
概念:将内存分为两块(即为A,B),先在A中存储,当A满了将回收,回收后将保留对象复制到B,清空A,后续在B中存储新的对象,B满了.往复 (S0,S1的实现)
缺点
概念:根据对象存活周期的不同将内存划分为不同的块.(新生代,老年代),在根据每个块的特性选择最合适的收集算法
新生代
对象存活率低,需要复制的存活对象少
老年代
对象存活率高,复制开销大
程序执行并非任何地方都可停顿,只有当达到安全点时才能暂停.(Stop The World)
中断方案
抢先中断
主动中断
在一段代码片段中,引用关系不会发生变化,这个区域中任意地方开始GC都是安全的
线程--执行safe Region中代码--> 标记自己已进入safeRegion---离开SafeRegion-->检查系统是否完成跟节点枚举(或整个GC过程)
使用复制算法,并行的多线程收集器
更关注于吞吐量,其它收集器关注缩短停顿时间(Stop The World)
-XX:MaxGCPauseMillis 设置最大停顿时间(毫秒)
-XX:GCTimeRatio 设置吞吐量大小(0-100)
-XX:UseAdaptiveSizePolicy
配合最大停顿时间,或吞吐量来使用.仅需要设置-Xmx
GC自适应调节策略(与其它收集器的重要区别)
单线程,老年代serial收集器,采用标记-整理算法
HotSpot第一款并发收集器,以获取最短回收停顿时间为目标的收集器
采用标记-清除算法
运作流程
1.初始标记
2.并发标记
3.重新标记
4.并发清除
缺点
对CPU资源非常敏感.默认启动回收线程数(CPU数量+3)/4,4个以上的CPU则会占用25%以上资源.占用资源过多
无法处理浮动垃圾,可能因Concurrent Mode Failure而导致一次Full GC的触发
并发处理,则垃圾回收时需要预留内存供用户线程使用,JDK1.5默认68%即会触发GC,JDK1.6默认值为92%,
-XX:CMSInitiatingOccupancyFraction
来设置阀值
标记-清除算法
JDK7u4正式商用
G1新生代,老年代的区分与其它收集器模式不同,它将内存划分成更多的Region,虽保留新生代,老年代概念,但已不在是物理隔离了,它们现在都是由Region(无需连续)组成的集合
特点
并行,并发
分代收集
空间整理
可预测的停顿
在G1收集器中,有一个关键的概念,Remembered Set,每一个Region都一个对应的Remembered Set,每当程序对Reference类型数据进行了写操作时,虚拟机会产生一个Write Barrier暂时中断写操作,检查Reference引用的对象是否处于不同的Region中,如果是,则会通过CardTable将相关引用信息记录到被引用对象所属的Region中的Remembered Set中.
当进行内存回收时,GC跟节点枚举范围中加入Remembered Set 以保证不全堆扫描也不会遗漏
运作流程
初始标记
并发标记
最终标记
筛选回收

【版权声明】
本文版权归作者和博客园共有,欢迎转载,未经作者同意必须在文章页面给出原文链接,否则保留追究法律责任的权利。
标签:minor 多线程 cti 年龄 结构 对象 复制算法 reads 组成
原文地址:https://www.cnblogs.com/diandiandian/p/13194845.html