标签:就是 lazy 常用 pre 多个 ima csdn 注意 标签
本篇借鉴了这篇文章,如果有兴趣,大家可以看看:https://blog.csdn.net/geter_CS/article/details/84857220
1、交叉熵:交叉熵主要是用来判定实际的输出与期望的输出的接近程度
2、CrossEntropyLoss()损失函数结合了nn.LogSoftmax()和nn.NLLLoss()两个函数。它在做分类(具体几类)训练的时候是非常有用的。
3、softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
其公式如下:
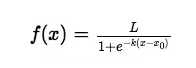
4、Pytorch中CrossEntropyLoss()函数的主要是将softmax-log-NLLLoss合并到一块得到的结果。
1、Softmax后的数值都在0~1之间,所以ln之后值域是负无穷到0。
2、然后将Softmax之后的结果取log,将乘法改成加法减少计算量,同时保障函数的单调性 。
3、NLLLoss的结果就是把上面的输出与Label对应的那个值拿出来,去掉负号,再求均值。
5、没有权重的损失函数的计算如下:
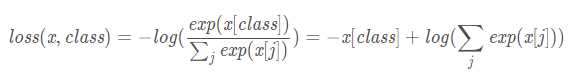
有权重的损失函数的计算如下:
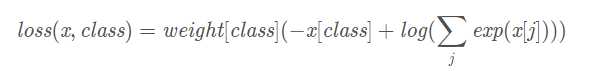
6、
举个栗子,我们一共有三种类别,批量大小为1(为了好计算),那么输入size为(1,3),具体值为torch.Tensor([[-0.7715, -0.6205,-0.2562]])。标签值为target = torch.tensor([0]),这里标签值为0,表示属于第0类。loss计算如下:
import torch import torch.nn as nn import numpy as np entroy = nn.CrossEntropyLoss() input = torch.Tensor([[-0.7715,-0.6205,-0.2562]]) target = torch.tensor([0]) output = entroy(input,target) print(output) #采用CrossEntropyLoss计算的结果。 myselfout = -(input[:,0])+np.log(np.exp(input[:,0])+np.exp(input[:,1])+np.exp(input[:,2])) #自己带公式计算的结果 print(myselfout) lsf = nn.LogSoftmax() loss = nn.NLLLoss() lsfout = lsf(input) lsfnout = loss(lsfout,target) print(lsfnout)
结果:
tensor(1.3447) tensor([1.3447]) tensor(1.3447)
Pytorch常用的交叉熵损失函数CrossEntropyLoss()详解
标签:就是 lazy 常用 pre 多个 ima csdn 注意 标签
原文地址:https://www.cnblogs.com/peixu/p/13194801.html