标签:字母 慢慢 loading 进制 使用 img 繁体 形式 image
对于数字来说,计算机可直接表示和处理,但是计算机是如何表示文字的呢?因为字符毕竟是现实世界当中的文字,而文字每个国家又是不同的。
字符编码(字符集):起初的时候计算机只支持数字,因为计算机最初就是为了科学计算,随着发展,需要让计算机支持现实世界当中的文字,一些标准制定的协会就制定了字符编码(字符集),字符编码其实就是一张对照表,在这个对照表上描述了某个文字与二进制之间的对应关系。
ASCII码
由美国标准协会指定,是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。是现今最通用的信息交换标准,并等同于国际标准ISO/IEC646。
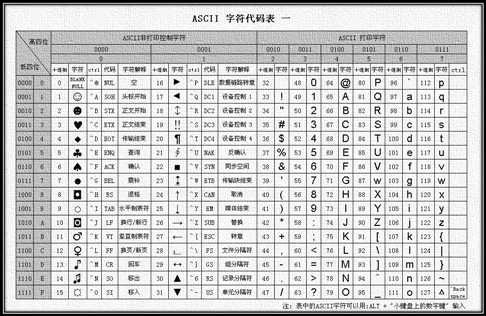
ASCII码采用1个字节编码,1个字节可以表示256种不同的形式,对于英文来说这个足够了,英文英文单词大小写全部才52个,再加上数字和标点符号也不会超过256个,但对于中文来说就远远不够了。
编码和解码
编码和解码是字符编码当中,常见的两个术语,举例来说:‘a‘是97,97对应的二进制是01100001,那么从‘a‘到二进制01100001的转换过程称为编码,从二进制01100001到‘a‘的转换过程称为解码。
为什么会出现乱码?
编码和解码要采用同一种字符编码方式(要采用同一个对照表),不然会出现乱码,这是乱码出现的本质原因。
ISO-8859-1字符集
随着计算机的不断发展,为了让计算机支持更多国家的语言,国际标准组织又制定了ISO-8859-1字符集,又被称为latin-1,向上兼容ASCII码,仍不支持中文主要支持西欧语言。再后来,计算机慢慢的开始支持简体中文、繁体中文、日本语、朝鲜语等,其中支持简体中文的字符集包括:GB2312 、GBK 、GB18030,它们的容量大小不同,其中 GB2312 < GBK < GB18030。支持繁体中文的是大五码 Big5 等。
Unicode编码
在上个世纪90年代初,国际组织制定了一种字符编码方式,叫做Unicode编码,这种编码方式统一了全球所有国家的文字,具体实现包括:UTF-8,UTF-16,UTF-32等。
Java 为了国际化,为了支持所有国家的语言,所以 Java 采用的编码方式为 Unicode 编码。例如字符‘中‘对应的 Unicode 码是‘\u4e2d‘。在实际开发中几乎所有的团队都会使用 Unicode 编码方式,因为这种方式更通用,兼容性更好。
标签:字母 慢慢 loading 进制 使用 img 繁体 形式 image
原文地址:https://www.cnblogs.com/wx1995/p/13195269.html