标签:关心 文件 注意力 情况 bsp 意图 结果 流行 接受
作者:朱晨光
机器阅读理解(Machine Reading Comprehension,MRC)是一种利用算法使计算机理解文章语义并回答相关问题的技术。由于文章和问题均采用人类语言的形式,因此机器阅读理解属于自然语言处理(NLP)的范畴,也是其中最新最热门的课题之一。近些年来,随着机器学习,特别是深度学习的发展,机器阅读理解研究有了长足的进步,并在实际应用中崭露头角。
学者 C. Snow 在 2002 年的一篇论文中定义阅读理解是“通过交互从书面文字中提取与构造文章语义的过程”。而机器阅读理解的目标是利用人工智能技术,使计算机具有和人类一样理解文章的能力。图1给出了一个机器阅读理解的样例。其中,模型需要用文章中的一段原文回答问题。

图1 机器阅读理解任务样例
大部分机器阅读理解任务采用问答式测评:设计与文章内容相关的自然语言式问题,让模型理解问题并根据文章作答。为了评判答案的正确性,一般有如下几种形式的参考答案:
此外,一些数据集设计了“无答案”问题,即一个问题可能在文章中没有合适答案,需要模型输出“无法回答”(unanswerable)。
在以上的答案形式中,多项选择和完形填空属于客观类答案,测评时可以将模型答案直接与正确答案比较,并以准确率作为评测标准,易于计算。
早期的阅读理解模型大多基于检索技术,即根据问题在文章中进行搜索,找到相关的语句作为答案。但是,信息检索主要依赖关键词匹配,而在很多情况下,单纯依靠问题和文章片段的文字匹配找到的答案与问题并不相关。随着深度学习的发展,机器阅读理解进入了神经网络时代。相关技术的进步给模型的效率和质量都带来了很大的提升。机器阅读理解模型的准确率不断提高,在一些数据集上已经达到或超过了人类的平均水平。
基于深度学习的机器阅读理解模型虽然构造各异,但是经过多年的实践和探索,逐渐形成了稳定的框架结构。机器阅读理解模型的输入为文章和问题。因此,首先要对这两部分进行数字化编码,变成可以被计算机处理的信息单元。在编码的过程中,模型需要保留原有语句在文章中的语义。因此,每个单词、短语和句子的编码必须建立在理解上下文的基础上。我们把模型中进行编码的模块称为编码层。
接下来,由于文章和问题之间存在相关性,模型需要建立文章和问题之间的联系。例如,如果问题中出现关键词“河流”,而文章中出现关键词“长江”,虽然两个词不完全一样,但是其语义编码接近。因此,文章中“长江”一词以及邻近的语句将成为模型回答问题时的重点关注对象。这可以通过自然语言处理中的注意力机制加以解决。在这个过程中,阅读理解模型将文章和问题的语义结合在一起进行考量,进一步加深模型对于两者各自的理解。我们将这个模块称为交互层。
经过交互层,模型建立起文章和问题之间的语义联系,就可以预测问题的答案。完成预测功能的模块称为输出层。由于机器阅读理解任务的答案有多种类型,因此输出层的具体形式需要和任务的答案类型相关联。此外,输出层需要确定模型优化时的评估函数和损失函数。
图2是机器阅读理解模型的一般架构。可以看出,编码层用于对文章和问题分别进行底层处理,将文本转化成为数字编码。交互层可以让模型聚焦文章和问题的语义联系,借助于文章的语义分析加深对问题的理解,同时也借助于问题的语义分析加深对文章的理解。输出层根据语义分析结果和答案的类型生成模型的答案输出。
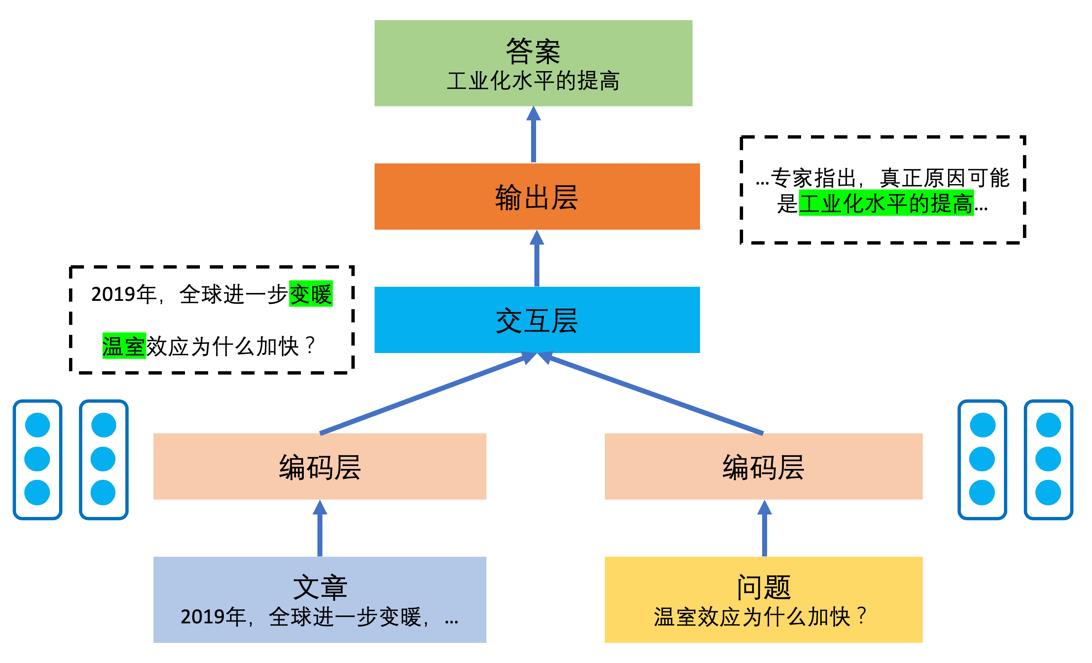
图2 机器阅读理解模型的总体架构,输出层以区间式答案为例
在基本框架的指引下,众多优秀的机器阅读理解模型脱颖而出。这些模型在网络架构、模块设计、训练方法等方面实现了各种创新,大大提高了算法理解文本和问题的能力和预测答案的准确性,在诸多机器阅读理解数据集和竞赛中取得了非常优秀的成绩。其中具有代表性的模型有:双向注意力流(BiDAF),使用门机制的 R-net、融合网络(FusionNet)等。
而近期非常流行的预训练模型给机器阅读理解领域带来了革命性的改变。预训练方法源于机器学习中迁移学习的概念:为了完成一个学习任务,首先在其他相关任务上预训练模型,然后将模型在目标任务上进一步优化,实现模型所学知识的迁移。预训练模型最大的好处是,可以克服目标任务(如机器阅读理解)数据不足的问题,利用大量其他任务的数据,建立有效的模型再迁移到目标任务,大大提高了模型的准确度。这其中最具有代表性的便是 Google 于 2018 年提出的双向编码器模型 BERT。BERT 采用无监督学习在大规模语料上进行预训练,并创新性地利用掩码设计与判断下一段文本两个子任务增强了模型的语言能力。在论文作者开源了代码和预训练模型后,BERT 立即被研究者运用在各种 NLP 任务中,并频繁大幅刷新之前的最好结果。例如,在 SQuAD 2.0 竞赛中,排名前 20 名的模型全部基于 BERT;CoQA 竞赛中,前 10 名模型全部基于 BERT。并且这两个竞赛中模型的最好表现已经超越人类水平。
机器阅读理解利用人工智能技术为计算机赋予了阅读、分析和归纳文本的能力。随着信息时代的到来,文本的规模呈爆炸式发展。因此,机器阅读理解带来的自动化和智能化恰逢其时,在众多工业界领域和人们生活中的方方面面都有着广阔的应用空间。
客服机器人是一种基于自然语言处理的拟人式服务,通过文字或语音与用户进行多轮交流,获取相关信息并提供解答。机器阅读理解可以帮助客服系统根据用户提供的信息在产品文档中快速找到解决方案,如图 3 所示。
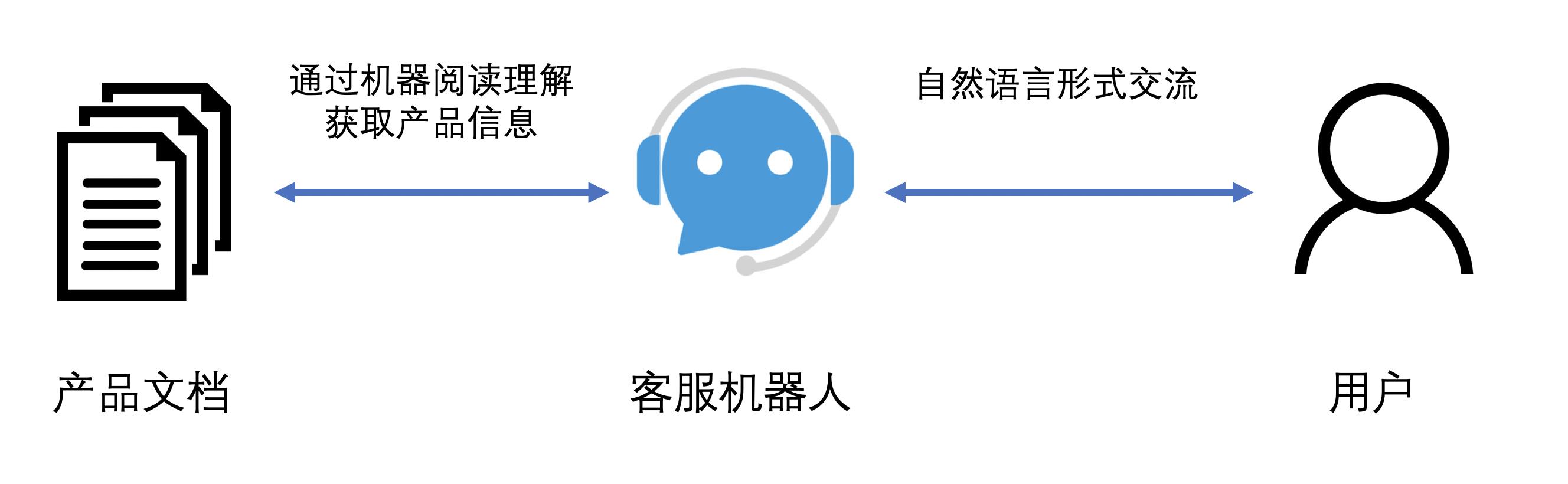
图3 客服机器人与用户与产品文档的关系
智能法律用于自动处理和应用各种错综复杂的法律法规实现对案例的自动审判,这正可以利用机器阅读理解在处理和分析大规模文档方面的速度优势。
智能教育利用计算机辅助人类的学习过程。机器阅读理解在这个领域的典型应用是作文自动批阅。自动作文批阅模型可以作为学生写作时的助手,理解作文语义,自动修改语法错误,个性化总结易错知识点。这些技术与当前流行的在线教育结合,很有可能在不久的将来对教育行业产生颠覆性的影响。
展望未来,机器阅读理解研究仍面临如知识与推理能力、可解释性、缺乏训练数据等挑战,但也有很大的应用空间。基于机器阅读理解高速处理大量文本的特点,这项技术最容易在劳动密集型文本处理行业落地。而在其产业化的进程中,可以有部分替代人类和完全替代人类两种模式。部分替代人类模式是指模型的质量没有完全达到可接受的水平,但是可以很好地处理简单高频的场景,然后由人类接力处理。而在作文自动批阅等需要模型独立完成任务的场景中,可以使用强化学习等手段根据用户的反馈不断改进模型的架构和参数,得到更好的表现。
在今后的发展中,一方面,机器阅读理解可以在自然语言理解已获得成功的深耕领域进一步细分与提升质量,如搜索引擎、广告、推荐等;另一方面,我们相信,随着机器阅读理解技术的不断进步,机器与人类的差距会不断缩小,我们必将迎来技术的奇点,使得这项技术对更多的行业产生革命性的影响。
最近,笔者参加了开源中国社区的“高手问答”活动,对读者们的提出的问题进行了总结,大致可以分为以下几个方面:
人工智能的语言
不少读者提到实现机器阅读理解和深度学习最好使用什么语言。首先,需要指出的是,任何编程语言都只是实现工具,而背后的算法和模型才是精髓。当前人工智能最热门的语言是 Python,主要原因是 Python 上手比较简单,语法规则没有 Java、C++ 那样复杂。而且 Python 属于解释性语言,即不需要编译就可以运行,可以一边写一边运行,利于调试。正因为如此,当前最流行的深度学习 TensorFlow 和 PyTorch 都基于 Python。使用的人多了,相关社区建立起来以后各种功能包、论文代码实现等都很齐全,就使得 Python 更加流行。
当然,我们还是需要先关注模型和算法,然后再用具体语言实现以加深理解。本书中介绍了机器阅读理解的各种模型,使用 PyTorch 展示,但也很容易转用其他框架或语言实现。
多模态阅读理解
市面上比较流行和成功的人工智能产品大多与多模态人工智能相关,特别是语音和语言的理解。例如 Amazon Echo、Google Home、天猫精灵等产品都嵌入了语言识别,意图理解,语音合成等人工智能技术。一般来说,这些产品首先将语音转化为文本,然后对文本进行类似于机器阅读理解的处理和分析,得到用户的意图。这个过程还包括理解对话的上下文(如指代词)、搜寻数据库(如找到用户想播放的歌的音频文件)、进一步提问以确定意图等技术。这些技术提升了用户与产品的交流体验,大大提高了用户对产品的满意度。因此,本书在最后一章提出,多模态是未来阅读理解的重要发展方向之一。
而对于其他多模态形式,例如文本图片混合,可以关注视觉问答(Visual Question Answering)等研究方向。
机器阅读理解的应用
不少读者提到了机器阅读理解的具体应用场景。下面列举一些。
人工智能自动写文章和作诗属于自然语言生成的范畴。书中在 3.3 节详细介绍了如何让自然语言模型生成文字。一般来说,利用大规模语料训练可以达到很好的效果,例如 GPT-2。
一位读者问对方言的阅读理解应该如何进行。由于方言中含有大量与标准汉语不同的单词、短语和语言用法,因此直接使用一般的中文模型效果较差,必须在专门的方言语料库上进一步训练。然而,缺少方言数据是一个很大的挑战。因此,可以考虑在深度学习中加入人工编辑的规则,将从方言中采集到的一些常见用法作为规则输入,是一种可行的解决办法。
此外,一些读者关心中文阅读理解的进展。近年来,随着各种论文、开源代码的普及,基本上所有英文方面的最新自然语言处理成果都有中文的实现和应用,而且方法基本类似。而中文和英文的不同点如分词、标点等都有专门的处理工具,如 Python 包 jieba 在中文分词方面有很好的效果(书中 2.1.1 节有代码实现)。
如何阅读本书
有读者问到阅读这本书需要有哪些基础。《机器阅读理解》这本书从深度学习和自然语言处理的基础讲起,例如分词、词向量、语言模型、语言理解、语言生成等。书中既有理论介绍,也有代码实践。因此,第 1-3 章可以作为自然语言处理和深度学习的入门书。
本书从第 4 章开始全面讲解机器阅读理解的任务、模型理论分析和实战代码,并介绍了各种落地应用,有很强的实用价值。
如果读者朋友有更多问题,欢迎阅读《机器阅读理解:算法与实践》一书,本书的源代码已开源在 https://github.com/zcgzcgzcg1/MRC_book。欢迎读者朋友们通过邮箱 zcg.stanford@gmail.com 与我联系。
作者介绍
朱晨光,微软公司自然语言处理高级研究员、斯坦福大学计算机系博士。负责自然语言处理研究与开发、对话机器人的语义理解、机器阅读理解研究等,精通人工智能、深度学习与自然语言处理,尤其擅长机器阅读理解、文本总结、对话处理等方向。带领团队负责客服对话机器人的语义理解与分析,进行机器阅读理解研究,在斯坦福大学举办的 SQuAD 1.0 机器阅读理解竞赛中获得全球第一名,在 CoQA 对话阅读理解竞赛中成绩超过人类水平并获得第一名。在人工智能和自然语言处理顶级会议 ICLR、ACL、EMNLP、NAACL 中发表多篇文章。

《机器阅读理解:算法与实践》
微软人工智能首席技术官黄学东、中国计算机学会秘书长杜子德联袂推荐!微软高级研究员、斯坦福大学计算机系博士、2届全球阅读理解竞赛冠军朱晨光撰写。让你深刻认识机器阅读理解并直接进行相关模型开发、实验和部署。
标签:关心 文件 注意力 情况 bsp 意图 结果 流行 接受
原文地址:https://www.cnblogs.com/1156184981651a/p/13195556.html