标签:mit mpi art focus comm ati 控制台 http 输出
1、hive的企业级调优
1.1 Fetch抓取(鸡肋)
Fetch抓取是指,==Hive中对某些情况的查询可以不必使用MapReduce计算==
在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台
set hive.fetch.task.conversion=none;
select * from employee;
select sex from employee;
select sex from employee limit 3;
set hive.fetch.task.conversion=more;
select * from employee;
select sex from employee;
select sex from employee limit 3;
1.2 本地模式
案例实操
--开启本地模式,并执行查询语句
set hive.exec.mode.local.auto=true; //开启本地mr
--设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,
--默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
--设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,
--默认为4
set hive.exec.mode.local.auto.input.files.max=5;
--执行查询的sql语句
select * from employee cluster by deptid;
1.3 表的优化
1.3.1 小表、大表join
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
实际测试发现:新版的hive已经对小表 join 大表和大表 join 小表进行了优化。小表放在左边和右边已经没有明显区别。
1.3.2 大表join大表
1.空 key 过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。
此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。
2、空 key 转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中,此时我们可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的 reducer 上。
1.3.3 map join
如果不指定MapJoin 或者不符合 MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存在map端进行join,避免reducer处理。
1、开启MapJoin参数设置
--默认为true
set hive.auto.convert.join = true;
2、大表小表的阈值设置(默认25M一下认为是小表)
set hive.mapjoin.smalltable.filesize=25000000;
3、MapJoin工作机制
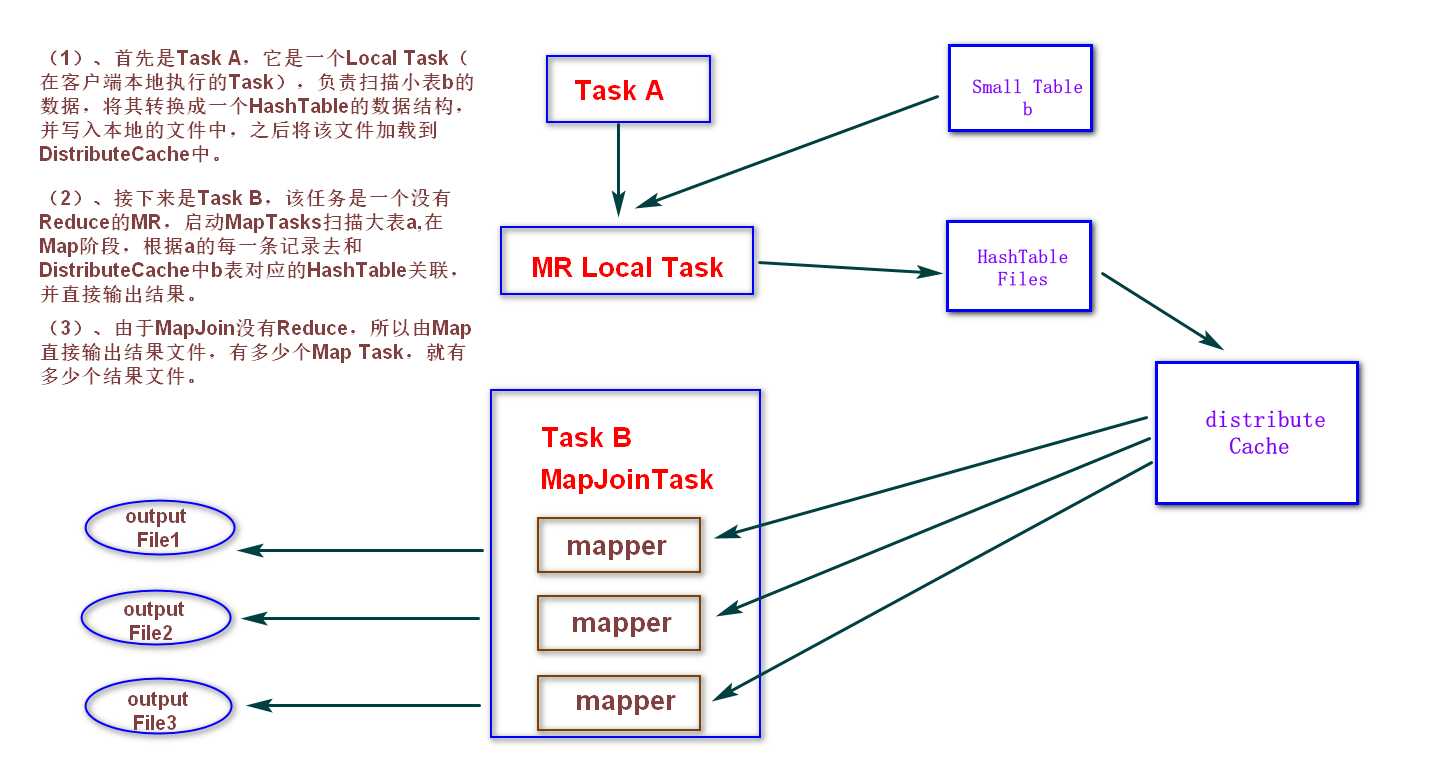
1.3.4 group by
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。
并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
开启Map端聚合参数设置
--是否在Map端进行聚合,默认为True
set hive.map.aggr = true;
--在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
--有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true;
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
1.3.5 count(distinct)
数据量小的时候无所谓,数据量大的情况下,由于count distinct 操作需要用一个reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般count distinct使用先group by 再count的方式替换
--每个reduce任务处理的数据量 默认256000000(256M)
set hive.exec.reducers.bytes.per.reducer=32123456;
select count(distinct ip ) from log_text;
转换成
select count(ip) from (select ip from log_text group by ip) t;
虽然会多用一个Job来完成,但在数据量大的情况下,这个绝对是值得的。
1.3.6 笛卡尔积
尽量避免笛卡尔积,即避免join的时候不加on条件,或者无效的on条件
Hive只能使用1个reducer来完成笛卡尔积。
1.4 使用分区裁剪、列裁剪
尽可能早地过滤掉尽可能多的数据量,避免大量数据流入外层SQL。
只获取需要的列的数据,减少数据输入。
分区裁剪
分区在hive实质上是目录,分区裁剪可以方便直接地过滤掉大部分数据。
尽量使用分区过滤,少用select *
1.5 并行执行
把一个sql语句中没有相互依赖的阶段并行去运行。提高集群资源利用率
--开启并行执行
set hive.exec.parallel=true;
--同一个sql允许最大并行度,默认为8。
set hive.exec.parallel.thread.number=16;
1.6 严格模式
Hive提供了一个严格模式,可以防止用户执行那些可能意想不到的不好的影响的查询。
--设置非严格模式(默认)
set hive.mapred.mode=nonstrict;
--设置严格模式
set hive.mapred.mode=strict;
(1)对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行
--设置严格模式下 执行sql语句报错; 非严格模式下是可以的
select * from order_partition;
异常信息:Error: Error while compiling statement: FAILED: SemanticException [Error 10041]: No partition predicate found for Alias "order_partition" Table "order_partition"
(2)对于使用了order by语句的查询,要求必须使用limit语句
--设置严格模式下 执行sql语句报错; 非严格模式下是可以的
select * from order_partition where month=‘2019-03‘ order by order_price;
异常信息:Error: Error while compiling statement: FAILED: SemanticException 1:61 In strict mode, if ORDER BY is specified, LIMIT must also be specified. Error encountered near token ‘order_price‘
(3)限制笛卡尔积的查询
严格模式下,避免出现笛卡尔积的查询
1.7 JVM重用
JVM重用可以使得JVM实例在同一个job中重新使用N次。减少进程的启动和销毁时间。
-- 设置jvm重用个数
set mapred.job.reuse.jvm.num.tasks=5;
1.8 推测执行
Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
--开启推测执行机制
set hive.mapred.reduce.tasks.speculative.execution=true;
1.9 压缩
#设置为true为激活中间数据压缩功能,默认是false,没有开启
set hive.exec.compress.intermediate=true;
#设置中间数据的压缩算法
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;
set hive.exec.compress.output=true;
set mapred.output.compression.codec=
org.apache.hadoop.io.compress.SnappyCodec;
1.10数据倾斜
1.10.1 合理设置map数
1) 通常情况下,作业会通过input的目录产生一个或者多个map任务。
主要的决定因素有:input的文件总个数,input的文件大小,集群设置的文件块大小。
2) 是不是map数越多越好?
答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
3) 是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
针对上面的问题2和3,我们需要采取两种方式来解决:即减少map数和增加map数;
1.10.2 小文件合并
CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
1.10.3 复杂文件增加map数
增加map的方法为
根据 ==computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))==公式
==调整maxSize最大值==。让maxSize最大值低于blocksize就可以增加map的个数。
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值Long.MAXValue因此,默认情况下,切片大小=blocksize
maxsize(切片最大值): 参数如果调到比blocksize小,则会让切片变小,而且就等于配置的这个参数的值。
minsize(切片最小值): 参数调的比blockSize大,则可以让切片变得比blocksize还大。
例如
--设置maxsize大小为10M,也就是说一个block的大小为10M
set mapreduce.input.fileinputformat.split.maxsize=10485760;
1.10.4 合理设置reduce数
1)每个Reduce处理的数据量默认是256MB
set hive.exec.reducers.bytes.per.reducer=256000000;
2) 每个任务最大的reduce数,默认为1009
set hive.exec.reducers.max=1009;
3) 计算reducer数的公式
N=min(参数2,总输入数据量/参数1)
2、调整reduce个数方法二
--设置每一个job中reduce个数
set mapreduce.job.reduces=3;
3、reduce个数并不是越多越好
过多的启动和初始化reduce也会消耗时间和资源;
同时过多的reduce会生成很多个文件,也有可能出现小文件问题
其实吧,调优这个玩意,上面只写只是一个方向,根据业务来摸索自己做的东西的优化
over,over===============
标签:mit mpi art focus comm ati 控制台 http 输出
原文地址:https://www.cnblogs.com/hanchaoyue/p/13195728.html